
یادگیری ماشین – SVM یا ماشین بردار پشتیبان به زبان ساده

یکی از الگوریتم ها و روشهای بسیار رایج در حوزه دسته بندی داده ها، الگوریتم SVM یا ماشین بردار پشتیبان است که در این مقاله سعی شده است به زبان ساده و به دور از پیچیدگیهای فنی توضیح داده شود.
آشنایی با مفهوم دسته بندی
فرض کنید مجموعه داده ای داریم که ۵۰٪ افراد آن مرد و ۵۰٪ افراد آن زن هستند. این مجموعه داده می تواند مشتریان یک فروشگاه آنلاین باشد. با داشتن یک زیرمجموعه از این داده ها که جنسیت افراد در آن مشخص شده است، می خواهیم قوانینی ایجاد کنیم که به کمک آنها جنسیت بقیه افراد مجموعه را بتوانیم با دقت بالایی تعیین کنیم. تشخیص جنسیت بازدیدکنندگان فروشگاه، باعث می شود بتوانیم تبلیغات جداگانه ای را برای زنان و مردان نمایش دهیم و سودآوری فروشگاه را بالا ببریم . این فرآیند را در علم تحلیل داده، دسته بندی می نامیم .
برای توضیح کامل مسأله، فرض کنید دو پارامتری که قرار است جنسیت را از روی آنها تعیین کنیم، قد و طول موی افراد است . نمودار پراکنش قد و طول افراد در زیر نمایش داده شده است که در آن جنسیت افراد با دو نماد مربع (مرد) و دایره (زن) به طور جداگانه نمایش داده شده است .
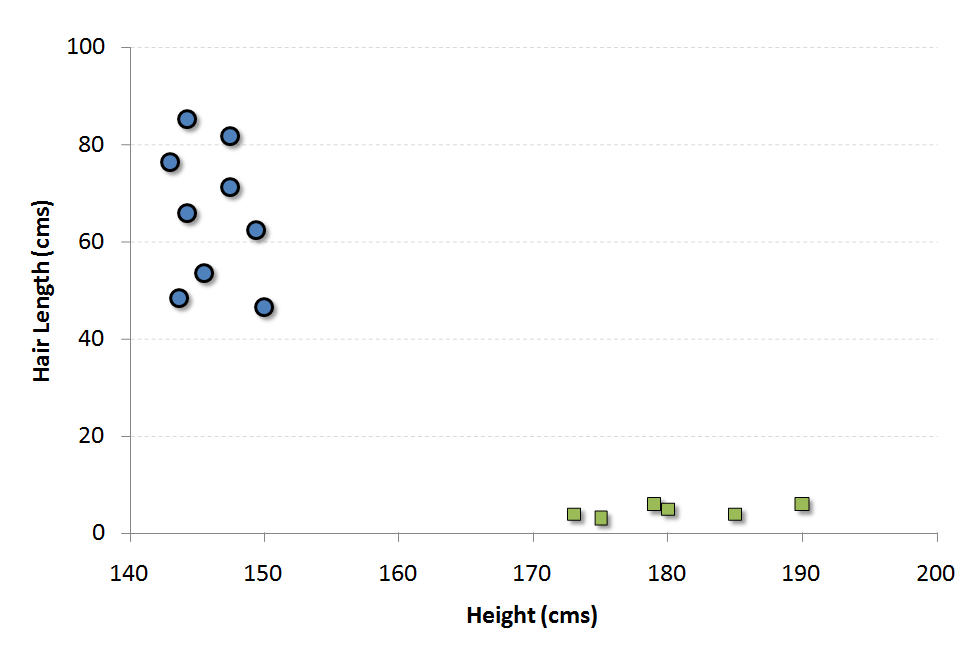
با نگاه به نمودار فوق، حقایق زیر به سادگی قابل مشاهده است :
- مردان در این مجموعه، میانگین قد بلندتری دارند.
- زنان از میانگین طول موی بیشتری برخوردار هستند.
اگر یک داده جدید با قد ۱۸۰cm و طول موی ۴cm به ما داده شود، بهترین حدس ما برای ماشینی این شخص، دسته مردان خواهد بود .
بردارهای پشتیبان و ماشین بردار پشتیبان
بردارهای پشتیبان به زبان ساده، مجموعه ای از نقاط در فضای n بعدی داده ها هستند که مرز دسته ها را مشخص می کنند و مرزبندی و دسته بندی داده ها براساس آنها انجام می شود و با جابجایی یکی از آنها، خروجی دسته بندی ممکن است تغییر کند. به عنوان مثال در شکل فوق ، بردار (۴۵,۱۵۰) عضوی از بردار پشتیبان و متعلق به یک زن است . در فضای دوبعدی ،بردارهای پشتیبان، یک خط، در فضای سه بعدی یک صفحه و در فضای n بعدی یک ابر صفحه را شکل خواهند داد.
در SVM فقط داده های قرار گرفته در بردارهای پشتیبان مبنای یادگیری ماشین و ساخت مدل قرار می گیرند و این الگوریتم به سایر نقاط داده حساس نیست و هدف آن هم یافتن بهترین مرز در بین داده هاست به گونه ای که بیشترین فاصله ممکن را از تمام دسته ها (بردارهای پشتیبان آنها) داشته باشد .
چگونه یک ماشین بر مبنای بردارهای پشتیبان ایجاد کنیم ؟
به ازای داده های موجود در مثال فوق، تعداد زیادی مرزبندی می توانیم داشته باشیم که سه تا از این مرزبندی ها در زیر نمایش داده شده است.
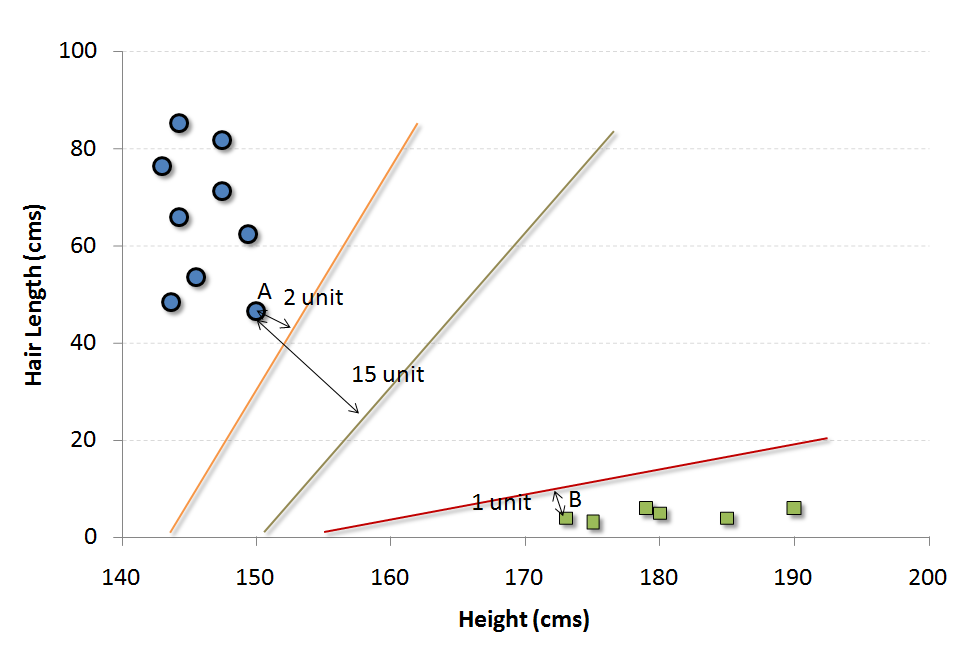
سوال اینجاست که بهترین مرزبندی در این مسأله کدام خط است ؟
یک راه ساده برای انجام اینکار و ساخت یک دسته بند بهینه ، محاسبه فاصله ی مرزهای به دست آمده با بردارهای پشتیبان هر دسته (مرزی ترین نقاط هر دسته یا کلاس) و در نهایت انتخاب مرزیست که از دسته های موجود، مجموعاً بیشترین فاصله را داشته باشد که در شکل فوق خط میانی ، تقریب خوبی از این مرز است که از هر دو دسته فاصله ی زیادی دارد. این عمل تعیین مرز و انتخاب خط بهینه (در حالت کلی ، ابر صفحه مرزی) به راحتی با انجام محاسبات ریاضی نه چندان پیچیده قابل پیاده سازی است .
توزیع غیر خطی داده ها و کاربرد ماشین بردار پشتیبان
اگر داده ها به صورت خطی قابل تفکیک باشند، الگوریتم فوق می تواند بهترین ماشین را برای تفکیک داده ها و تعیین دسته یک رکورد داده، ایجاد کند اما اگر داده ها به صورت خطی توزیع شده باشند (مانند شکل زیر )، SVM را چگونه تعیین کنیم ؟
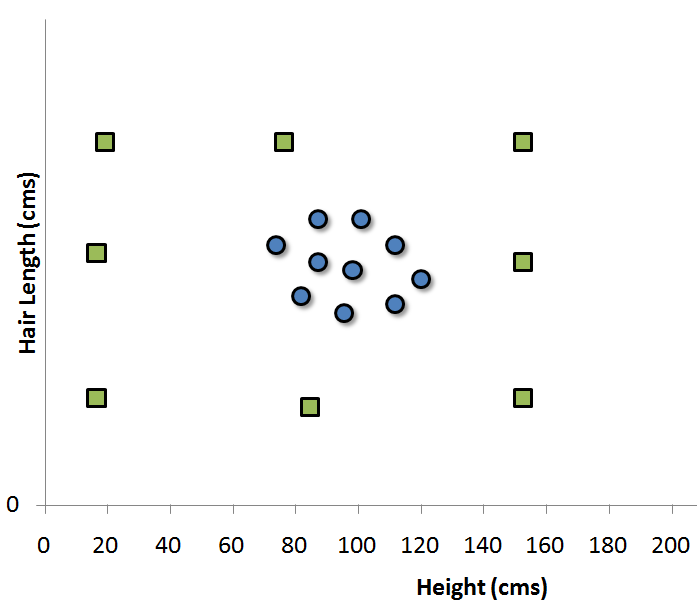
در این حالت، ما نیاز داریم داده ها را به کمک یک تابع ریاضی (Kernel functions) به یک فضای دیگر ببریم (نگاشت کنیم ) که در آن فضا، داده ها تفکیک پذیر باشند و بتوان SVM آنها را به راحتی تعیین کرد. تعیین درست این تابع نگاشت در عملکرد ماشین بردار پشتیبان موثر است که در ادامه به صورت مختصر به آن اشاره شده است.
با فرض یافتن تابع تبدیل برای مثال فوق، فضای داده ما به این حالت تبدیل خواهد شد :
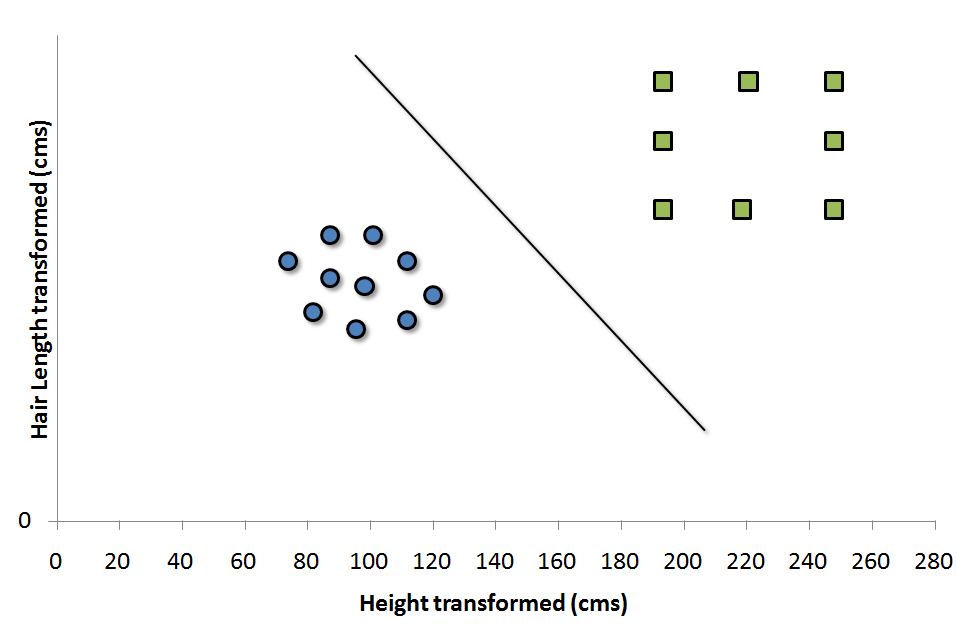
در این فضای تبدیل شده، یافتن یک SVM به راحتی امکان پذیر است .
نگاهی دقیق تر به فرآیند ساخت SVM
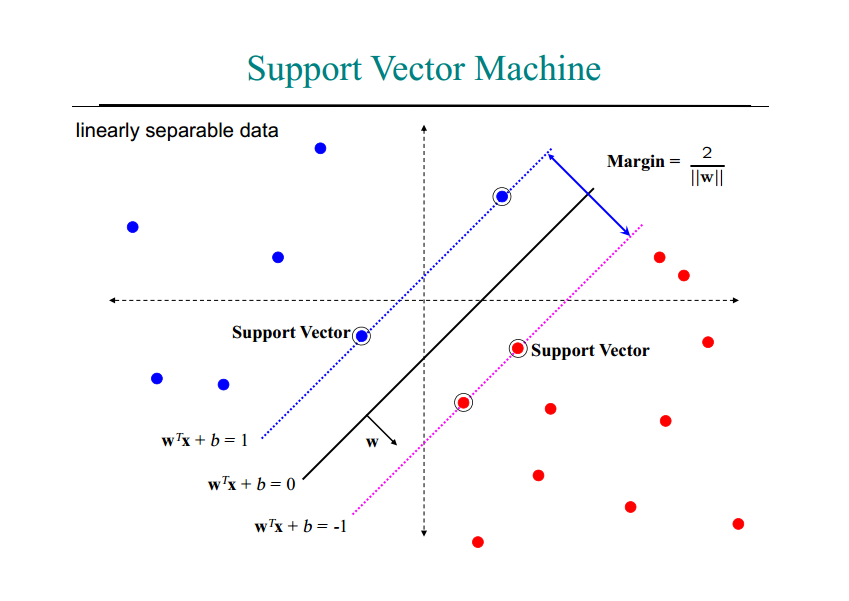
همانطور که اشاره شد،ماشین بردار پشتیبان یا SVM داده ها را با توجه به دسته های از پیش تعیین شده آنها به یک فضای جدید می برد به گونه ای که داده ها به صورت خطی (یا ابر صفحه ) قابل تفکیک و دسته بندی باشند و سپس با یافتن خطوط پشتیبان (صفحات پشتیبان در فضای چند بعدی) ، سعی در یافتن معادله خطی دارد که بیشترین فاصله را بین دو دسته ایجاد می کند.
در شکل زیر داده ها در دو دوسته آبی و قرمز نمایش داده شده اند و خطوط نقطه چین ، بردار های پشتیبان متناظر با هر دسته را نمایش می دهند که با دایره های دوخط مشخص شده اند و خط سیاه ممتد نیز همان SVM است . بردار های پشتیبان هم هر کدام یک فرمول مشخصه دارند که خط مرزی هر دسته را توصیف می کند.
SVM در پایتون
برای استفاده از ماشین بردار پشتیبان در پایتون، توصیه بنده استفاده از کتابخانه یادگیری ماشین پایتون به نام scikit–learn است که تمام کرنل ها و توابع نگاشت را به صورت آماده شده دارد. سه تا تابع SVC , NuSVC , LinearSVC وظیفه اصلی دسته بندی را برعهده دارند . (SVC = Support Vector Classifier) . نمونه ای از دسته بندی با این توابع را در زیر می توانید مشاهده کنید :
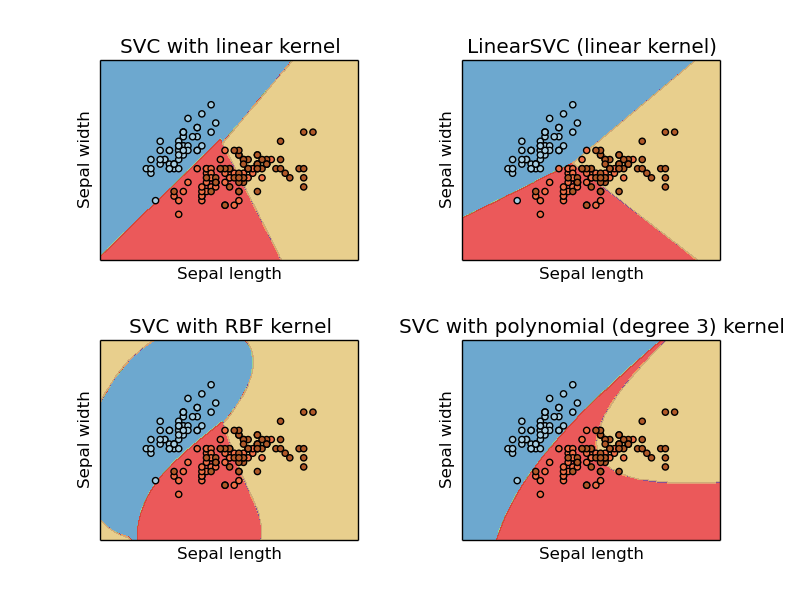
برای انتخاب دقیق تر نوع کرنل و پارامترهای آن می توانید از این مقاله هم استفاده کنید .
ماشین بردار پشتیبانی در عمل
برای استفاده از SVM در مورد داده های واقعی ، چندین نکته را باید رعایت کنید تا نتایج قابل قبولی را بگیرید
- ابتدا داده ها را پالایش کنید (نقاط پرت ، داده های ناموجود و …..)
- داده را عددی و نرمال کنید . این مباحث را در مقالات پیش پردازش داده ها دنبال کنید. به طور خلاصه ، داده هایی مانند جنسیت، رشته تحصیلی و … را به عدد تبدیل کنید و سعی کنید مقادیر همه صفات بین یک تا منهای یک [۱,-۱] نرمال شوند تا بزرگ یا کوچک بودن مقادیر یک ویژگی داده ها، ماشین را تحت تاثیر قرار ندهد .
- کرنل های مختلف را امتحان و به ازای هر کدام، با توجه به مجموعه داده آموزشی که در اختیار دارید و دسته بندی داده های آنها مشخص است، دقت SVM را اندازه گیری کنید و در صورت نیاز پارامتر های توابع تبدیل را تغییر دهید تا جواب های بهتری بگیرید. این کار را برای کرنل های مختلف هم امتحان کنید . می توانید از کرنل RBF شروع کنید . برای آشنایی با توابع کرنل، آموزش مفید زیر را از دست ندهید :
A Visual Introduction to Function Kernels · Dhruv On Math
I hope that by the end of this post you will:
https://www.dhruvonmath.com/2019/04/04/kernels/
نقاط ضعف ماشین بردار پشتیان
- این نوع الگوریتم ها، محدودیت های ذاتی دارند مثلا هنوز مشخص نشده است که به ازای یک تابع نگاشت ، پارامترها را چگونه باید تعیین کرد.
- ماشینهای مبتنی بر بردار پشتیبان به محاسبات پیچیده و زمان بر نیاز دارند و به دلیل پیچیدگی محاسباتی، حافظه زیادی نیز مصرف می کنند.
- داده های گسسته و غیر عددی هم با این روش سازگار نیستند و باید تبدیل شوند.
با این وجود، SVM ها دارای یک شالوده نظری منسجم بوده و جواب های تولید شده توسط آنها ، سراسری و یکتا می باشد. امروزه ماشینهای بردار پشتیبان، به متداول ترین تکنیک های پیش بینی در داده کاوی تبدیل شده اند.
سخن پایانی
ماشینهای بردار پشتیبان، الگوریتم های بسیار قدرتمندی در دسته بندی و تفکیک داده ها هستند بخصوص زمانی که با سایر روشهای یادگیری ماشین مانند روش جنگل تصادفی تلفیق شوند. این روش برای جاهایی که با دقت بسیار بالا نیاز به ماشینی داده ها داریم، به شرط اینکه توابع نگاشت را به درستی انتخاب کنیم، بسیار خوب عمل می کند .
ساختار اصلی این نوشتار از روی یک مقاله سایت آنالیتیکزویدیا برداشته شده است و برای دو بخش پایانی مقاله هم از کتاب «داده کاوی پیشرفته : مفاهیم و الگوریتم ها» دکتر شهرابی استفاده شده است .
آیا در .net یا java پیاده سازی شده این الگوریتم ها را سراغ دارید؟ (با performance قابل توجه)
متشکر
کتابخانه LibSVM یک کتابخانه چند زبانه است که می توانید از آن استفاده کنید.
salam, man zamineye informatici nadaram vali vaghti khundam be dalile negareshe sade va ravane shoma fahmidam,va mofid bud ama agar kamel tar beshe makhsusan agar mesalhaye kameli az marhaleye teory ta amal ruye python erae konin aalii mishe.sepase faravan
با سلام .
ممنون از اظهار لطف شما . مثالهای عملی هم به تدریج اضافه خواهد شد
باسلام،بسیار از توضیحات شما سپاسگزارم
استاد بزرگوار شما کارت خیلی درسته. خدا بهت سلامتی بده
اگه مطالب پیشرفته تر مخصوصاَ اون قسمتی که صحبت از تلفیق این متد با الگوریتم جنگل تصادفی شد؛ بذارین واقعاَ ممنون میشم.
سلام
ممنونم خیلی توضیحاتتون عالی و قابل درک بود سپاس بی کران.
سلام من یه مثال عددی همراه با مراحل حل برای ماشین بردار پشتیبان و شبکه عصبی احتمالی لازم دارم به علت کمبود وقت نتونستم پیدا کنم اگه دوستان میتونید کمکم کنید ممنون میشم برای الگوی آموزش چارت کنترل باشه بهتره اما اگه خارج از این هم بود بازم ممنونم
با عرض سلام
من نیاز ب کد متلب svm در حالتی ک هر داده چندین ویژگی داشته باشد دارم.
کد رو برای حالت دو ویژگی نوشتم ولی نمیتونم ب حالت چند ئیژگی تعمیمش بدم. ممنون میشم راهنمایی بفرمایید
معرفی خیلی خوبی از SVM بود، ممنونم
سلام من دنبال یک الگوریتم پرقدرت تر از svm هستم طوری که درصد نتایج بدست اومد رو افزایش بده برای کار متن کاوی ممنون میشم راهنماییم کنید
درود.
در دسته بندی متن، svm یکی از الگوریتمهای مناسب است اما می توانید بسته به نوع کار، الگوریتم های یادگیری عمیق را هم آزمایش کنید. برای نمونه، این مقاله را بررسی بفرمایید :
http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
باسلام وممنونم از سایت خوبتون
ببخشید پروژه من در مورد شناسایی چهره با استفاده از ماشین برداری پشتیبان هستش، من میخوام اونو تو متلب پیاده سازی کنم ،
اما اطلاعی از این ماشین برداری پشتیبان ندارم ، شما میدونین از کجا بایستی کدهای تشخیص چهره با ماشین برداری پشتیبان رو بگیرم؟
خواهش میکنم کمکم کنین.
مهندسی داده :
متاسفانه در زمینه برنامه نویسی متلب ، کار نکرده ایم. انشالله که با کمی حوصله و استفاده از گوگل، بتوانید کدهای مورد نیاز خودتان را پیدا کنید.
خدا قوت.
بسیار عالی توضیح دادید. از ریاضی که متنفرم؛ اما سبک توضیحاتتون باعث شد فرمول های گنگ رو بهتر متوجه بشم در SVMها.
با تشکر
بسیار ممنون و متشکرم از توضیحات خوبتان در مورد svm
با سلام و احترام
از توضیحات خوبتان متشکرم
انشاالله موفق باشید
سلام.یه سوال داشتم من روی داده های مصرف برق کارکردم از مدل نایو بیز دقت بیشتری نسبت به svm و درخت تصمیم گرفتم.علتش چیه؟
این مدل ها روی چه داده هایی هرکدومشون بهتر عمل می کنند؟
مهندسی داده :
الگوریتم های طبقه بندی، کاملا به مجموعه داده، کیفیت آنها، نوع داده ها و خصوصیات انتخابی برای عمل طبقه بندی وابسته اند و معمولا برای یک مساله، بعد از انتخاب خصوصیات اصلی و مهم داده ها و پیش پردازش اولیه داده، بر اساس هر کدام از الگوریتم ها ، تستی را انجام میدهیم تا ببینیم دقت مدل به دست آمده چقدر است. اگر با تغییر پارامترهای مدل، باز هم الگوریتم دیگری مناسب تر بود، آنرا انتخاب می کنیم.
هر چند سایر دوستان که اشراف دقیق تری روی این موضوع دارند، شاید نظر دقیق تری داشته باشند .
موفق باشید .
thanks from your describtion which is very useful for human which for this topic
سلام روزتون بخیر عالی بود توضیحاتتون اگه می شه راجع به رگرسیون ماشین بردار پشتیبان هم توضیح بدید یا یک منبع آموزشی معرفی کنید ممنون.
با سلام. خوشحالم که مقاله براتون مفید بوده. متاسفانه توی حوزه SVR کار نکردم. اگه شما به نتیجه رسیدید خوشحال میشوم خلاصه آنرا برای بنده ارسال کنید تا در انتهای این مقاله آنرا درج کنم.
موفق باشید .
سلام و خسته نباشید .. بنده روی پروژم دارم الگوریتم ماشین بردار پشتیبان رو در رپیدماینر پیاده سازی میکنم .. ولی دیتاست من اکثرا اتریبیوت های غیر عددی (حروفی) داره و اررور میده که svm داده های polynominal رو ساپورت نمیکنه … میشه توضیح دهید چگونه داده های غیر عددی رو به عددی تبدیل کنم ؟ ممنونتون میشم .
سلام. میبایست عملیات لیبلینگ و کمی سازی برای داده های غیرعددی انجام بدین،
خیلی مفید و عالی بود با تشکر فراون
با سلام
استاد گرامی میشه لطفا یک نمونه از اینکه چطور میشه svm رو در جاوا استفاده و پیاده سازی کرد هم بگین لطفا
باتشکر
سلام ،ممنونم بابت توضیحات عالی شما
ببخشید میشه در مورد روش جنگل تصادفی و ترکیب آ ن با svmتوضیح بدین .ممنونم
سلام
میشه الگوریتمی شبیهavm و ECOC بهم معرفی کنید
پروژه ام:
: تشخیص طاسی موی سر با استفاده از استفاده از کدهای خروجی تصحیح کننده خطا و الگوریتم ماشین بردار
سلام
واقعا عالی بود
دست شما درد نکنه.