
اخیرا به پروژه متنبازی با نام کدرو برخوردم که هم ماموریت آن به عنوان یک مهندس نرمافزار که قدر و قیمت استانداردها را در حوزههای برنامهنویسی و نرم افزار با تمام وجود احساس کرده است، برایم ارزشمند بود و هم تعداد نسبتاً زیاد توسعه دهندگان آن ( حدود صد نفر) توجهم را جلب کرد. بنابراین تصمیم گرفتم علیرغم اینکه از حوزه علم داده فاصله گرفتهام اما این کتابخانه ارزشمند پایتون را معرفی کنم. باشد که برای علاقهمندان آن مفید باشد .
یک تیم علم داده در یک سازمان، نیاز دارد علاوه بر پاکسازی و پردازش داده و ساخت مدلهای پیشگویانه، موارد زیر را هم در پروژهای علم داده لحاظ کند :
- کدنویسی استاندارد
- ساختار منظم برای هر پروژه
- تفکیک منطق و الگوریتم از فریمورکهای اجرا کننده
- مدیریت یا نظارت گرافیکی و ساده بر خطوط پردازش داده
- امکان ایجاد خطوط پردازش داده
- نسخهدهی کدها و دادهها
- وجود یک کاتالوگ برای هر مجموعه داده شامل توضیحات کلی و شرح فیلدها
کِدرو، این نیازمندیها را با ایجاد یک فریمورک منظم برای تولید پروژههای علم داده به خوبی پاسخ می دهد.

به عنوان مثال، ساختار پیشنهادی کِدرو برای پروژههای علم داده از قرار زیر است :
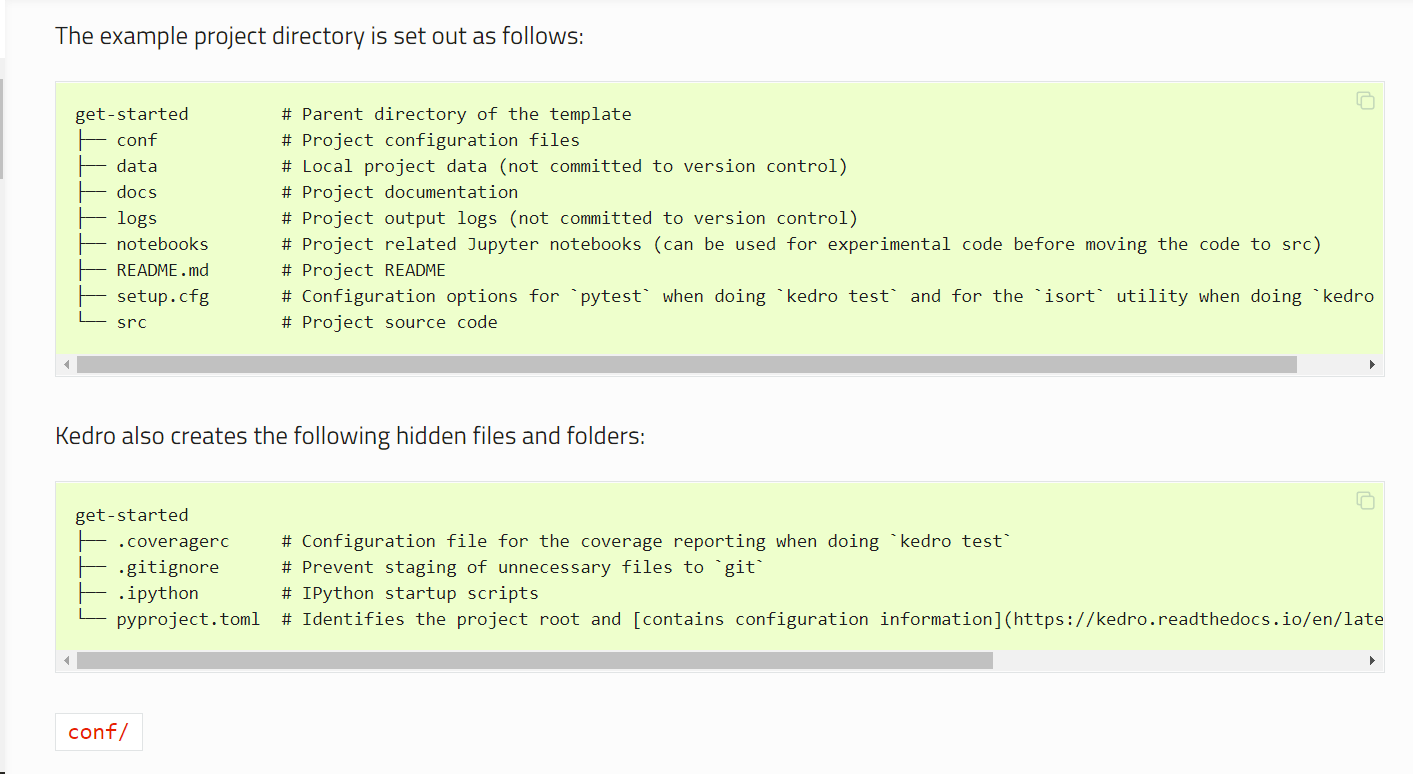
و یا نمونهای از خروجی یک خط پردازش داده که با کِدرو طراحی شده است مشابه قطعه کد زیر است :
کِدرو با اسپارک هم به خوبی کار میکند و میتوانید مستقیما خطوط پردازش دادهای طراحی کنید که با اسپارک پردازش شوند.
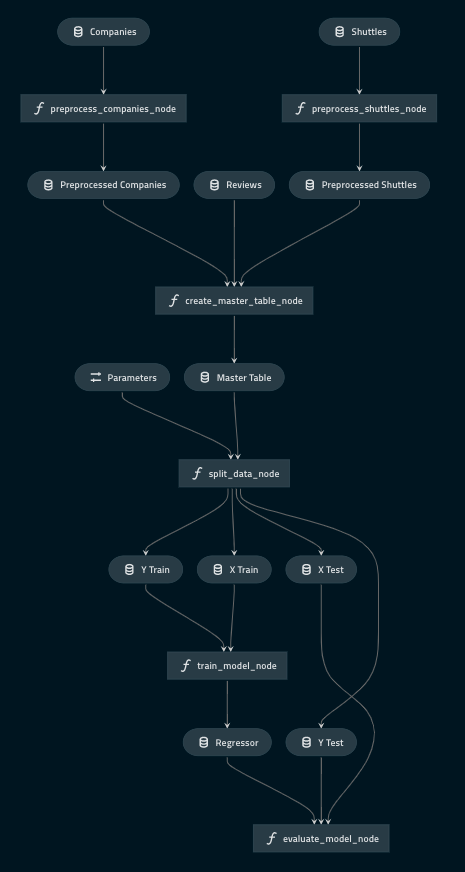
به عنوان کلام آخر، نمایش گرافیکی یک خط پردازش داده نمونه که با کِدرو طراحی شده است را در تصویر زیر میتوانید مشاهده کنید :
اگر به کدرو علاقهمند شدهاید میتوانید با این مثال ساده شروع کنید.