مدیر تیم دیتای شرکت الوپیک جناب آقای بیژن موعودی اخیراً وبیناری را با همکاری مرکز مطالعات مهندسی فرآیند دانشگاه تهران برگزار کرده است و علاوه بر تشریح بخشی از معماری داده این شرکت، چالشهایی که این تیم در چند سال اخیر با آن مواجه بوده است را توضیح داده است.
نکته اول در این خصوص، کار ارزشمندی است که انجام شده است و امیدوارم سایر تیم های داده شرکتهای بزرگ ایرانی هم با هدف اشتراک دانش و تجربیات با جامعه مهندسی کشور، وبینارها و کارگاههای مشابهی را برگزار کنند.
نکته مهم بعدی هم مجموعه ابزارهای بسیار کامل و جدیدی بود که این تیم برای مدیریت دادههای خود استفاده کرده بود که با شناختی که از برخی شرکتهای ایرانی به دست آورده ام، این شرکت را جزء شرکتهای بسیار پیشرو در این زمینه می بینم . برخی از این فناوریها را در این نوشتار با هم مرور میکنیم .
معماری داده شرکت الوپیک – بهمن ۹۹
اجزای اصلی معماری داده
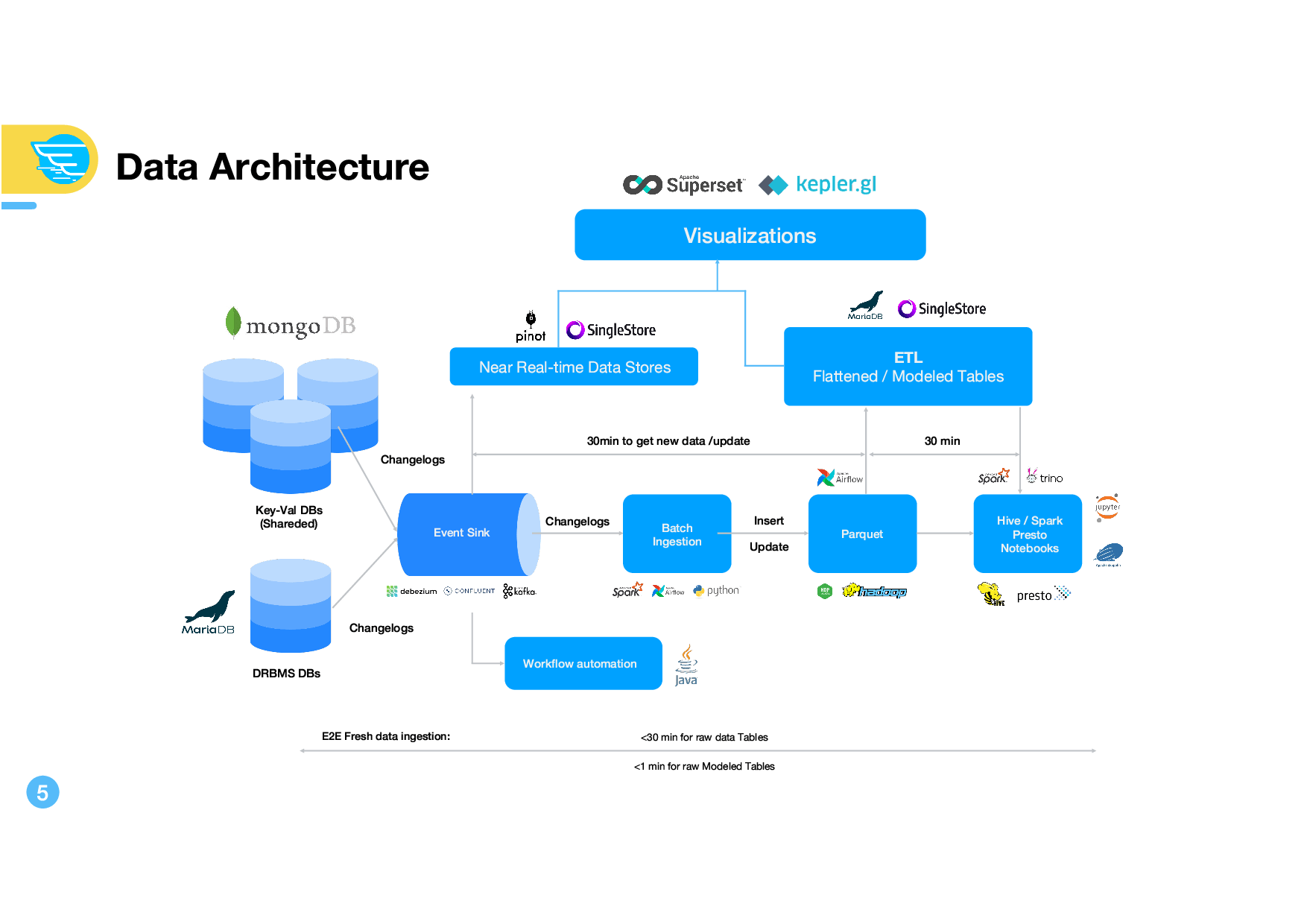
معماری داده الوپیک در شکل فوق نمایش داده شده است که نسخه با کیفیت آنرا در فایل پی دی اف خود ارائه میتوانید مشاهده کنید. در این معماری موارد زیر قابل مشاهده است :
ساخت ایونت باس یا گذرگاه رویداد شرکت به کمک فناوری CDC : تغییرات دو دیتابیس اصلی از طریق Debezium که یک ابزار متنباز در حوزه (Change Data Capture) است به کافکا ارسال می شود. با این کار، بدون نیاز درگیر کردن تیمهای برنامه نویسی، میتوانیم رویدادهای انجام شده در کسب و کار را شناسایی و عملیات مناسب برای هر یک را برنامه ریزی کنیم. مثلا هر درخواست پیک، کنسل کردن پیک، درخواست سرویس ویژه و … اگر در دیتابیسهای اصلی ذخیره شوند، به کمک ابزارهای CDC، دریافت شده و ایونت مناسب برای پردازش هر یک از آنها تولید میشود. مثلا با ثبت نام هر کاربر جدید و ذخیره کاربر در دیتابیس، این تغییر توسط دبزیوم دریافت شده و به کافکا ارسال می شود. سپس به ازای هر یک از این تغییرات، ایونت مناسب تولید و به کانال پردازشی مرتبط با آن در کافکا ارسال می شود. مثلا اگر تغییر کپچر شده، یک تغییر در جدول کاربران و نوع آن اینزرت باشد، متوجه میشویم که یک کاربر جدید، در سایت ثبت نام کرده است. بنابراین ایونتی با نام User_Register تولید کرده و با دادههای مرتبط با آن، به کانال پردازش کاربران در کافکا ارسال می کنیم . کانسیومرهای کافکا، به کمک اسپارک یا سایر فریمورکهای پردازشی، این رخداد را پردازش و عملیات مرتبط با آن را انجام میدهند مثلا ایمیل خوش آمد گویی به کاربرارسال میشود و کد تخفیف برایش پیامک می گردد. (این ها البته توضیح مساله بود و جزییات کاری که تیم دیتای الوپیک انجام میدهند حتما با این روال متفاوت خواهد بود )
پردازش دادهها با اسپارک و ایرفلو : دادهها به کمک اسپارک پرداش شده و تغییرات لازم بر روی آنها صورت میگیرد. ایرفلو هم برای مدیریت کارهای زمان مند استفاده میشود. مثلا ارسال ایمیل به تمام کاربران جدید در پایان روز، کاری است که ایرفلو به راحتی آنرا مدیریت کرده و سر ساعت مشخص، ارسال ایمیل ها را انجام خواهد داد. تبدیل دادهها به پارکت و ذخیره آنها توسط اسپارک انجام میشود اما اجرای پردازش های اسپارک در هر مثلا نیمساعت، توسط ایرفلو مدیریت میشود.
ذخیره دادههای تحلیلی با قالب پارکت : برای ساخت دیتالیک یا دریاچه داده که دادهها را به شکل خام در آن ذخیره میکنیم، یکی از محبوب ترین قالبها، پارکت است که هم فشرده سازی بالایی میتوان روی آن انجام داد و حجم دادهها را کم کرد و هم کار با آن در اسپارک بسیار راحت و سهل الوصول است . این دادهها برای توزیع در شبکه میتواند در هدوپ (HDFS) ذخیره شود . کاری که در الوپیک هم انجام شده است و دریاچه داده آنها ترکیب پارکت و HDFS است. راه حل حرفهای تر در این حوزه میتواند ترکیب آپاچی iceberg و پارکت باشد.
پرستو (Prsto/Trino) : بعد از ذخیره دادهها در هدوپ به صورت پارکت، خیلی اوقات نیاز داریم تحلیلها و کوئری هایی روی این دادهها انجام دهیم. یکی از بهترین ابزاری که امروزه برای این موضوع یعنی اجرای SQL بر روی هر چیز! به کار می رود (SQL on Everything) نرم افزار PrestoDB است که با دو شاخه شدن پروژه اصلی که متعلق به فیس بوک بود، نسخه کاملا متنباز و غیر وابسته به فیس بوک آن با نام Trino امروزه شناخته می شود و به نظر می رسد الوپیک از هر دوی آنها استفاده کرده است. لوگوی هایو در این بخش هم احتمالا به دلیل استفاده از Hive Metastore برای ذخیره دادههای داخلی پرستو مانند مکان قرارگیری فایلهای داده در شبکه است .
آپاچی پینوت و SingleStore: آپاچی پینوت به عنوان یک دیتابیس تقریبا نوظهور در حوزه ذخیره دادههای تحلیلی (غیر از داده های عملیاتی که مورد نیاز مستقیم مشتریان شرکت است ) در کنار کلیک هوس و آپاچی دروید، سه بازیگر اصلی این حوزه هستند و برای پاسخگویی لحظهای به کوئریهای موردنیاز بخشهای مختلف به دادههای تحلیلی، استفاده شده است. SingleStore هم که قبلا با نام MemSQL شناخته میشد، یک دیتابیس رابطهای توزیع شده و منطبق بر پروتکلهای ارتباطی MySQL است که دادهها را در دیسک به صورت ستونی و در حافظه به صورت سطری لود میکند و از انواع دادهها مانند جیسان، کلید/ مقدار و جداول رابطهای هم به خوبی پشتیبانی میکند. به دلیل نیاز به انواع کوئری های پیشرفته sql و جوین های پیچیده، این دیتابیس در کنار پینوت برای ذخیره توزیع شده و مقیاس پذیر دادهها به کار رفته است.
آپاچی سوپرست و کپلر:سوپرست که اخیرا نسخه یک آن عرضه عمومی شده است یکی از پروژه های محبوب حوزه دیتا در بنیاد آپاچی است که به کمک آن، میتوان انواع نمودارها را ایجاد کرده و تصویرسازی های مختلفی را به صورت آنلاین انجام داد. این پروژه که با پایتون و فریمورک محبوب فلسک نوشته شده است، به راحتی به برنامههای تحت وب شما افزوده میشود و میتواند جایگزینی مطمئمن برای ابزارهای هوش تجاری مانند پاوربیآی و تبلوباشد (البته برای کاربردهای نمایش و تصویرسازی). کانکتورهای متنوع آن اجازه اجرای انواع کوئری های SQL و اتصال به انواع منابع داده و ساخت گزارشات و داشبوردهای حرفه ای را به کاربران میدهد. طبق گفته آقای موعودی، تیم الوپیک در توسعه این محصول هم با بنیاد آپاچی همکاری میکند که بسیار باعث خوشحالی است. کپلر هم کتابخانه تصویرسازی مبتنی بر وب برای دادههای جغرافیایی است که توسط اوبر توسعه داده شده است.
وبینار چالشهای تیم داده الوپیک را در زیر می توانید مشاهده کنید :
دانشجوی دکترای نرمافزار دانشگاه تهران (yun.ir/smbanaie)، مدرس دانشگاه و فعال در حوزه توسعه نرمافزار و مهندسی داده که تمرکز کاری خود را در چند سال اخیر بر روی مطالعه و تحقیق در حوزه کلانداده و زیرساختهای پردازش داده و تولید محتوای تخصصی و کاربردی به زبان فارسی و انتشار آنها در سایت مهندسی داده گذاشته است. مدیریت پروژههای نرمافزاری و طراحی سامانههای مقیاسپذیر اطلاعاتی از دیگر فعالیتهای صورت گرفته ایشان در چند سال گذشته است.


ممنون