
بررسی مهاجرت از MySQL به TiDB
چگونه با دیتابیس TiDB، تمامی مشکلات زیرساخت داده مبتنی بر MySQL خود را به سرعت برطرف کنیم
اگر شما هم جزء سازمانها و یا توسعهدهندگانی هستید که سالهاست با MySQL کار کردهاید اما افزایش حجم داده و ظهور نیازمندیهای تحلیلی جدید، شما را با چالشهای جدی در ادامه کار با این دیتابیس قدیمی اما محبوب مواجه کردهاست، با ما همراه باشید تا راهحل سریع و جامع شرکت Bigo که یک شرکت فعال در حوزه رسانههای اجتماعی با حدود ۴۰۰ میلیون کاربر ماهیانه است و به تازگی از MySQL به TiDB4.0 مهاجرت کرده است، را با هم بررسی کنیم . با توجه به محبوبیت مایاسکیوال در جامعه کاربری ایرانی، امیدوارم این بررسی، بتواند به مهندسین داده درگیر در پروژههای بزرگ شامل این دیتابیس، یک گزینه مناسب را پیشنهاد دهد.
بیگو بعد از چندین سال فعالیت و با رشد جامعه کاربران خود و افزایش میزان پرسوجوهای لحظهای، در استفاده و مقیاسپذیری مایاسکیوال به مشکل برخورد. این شرکت به دنبال راه حلی بود که چهار مورد زیر را بتواند حل کند :
- تا حد امکان با MySQL سازگار باشد که مجبور به تغییرکدهای نوشته شده و برنامههای موجود خود نباشند.
- پرسوجوهای SQL را در حجم بالای داده به سرعت بتواند پاسخ دهد.
- پرسوجوهای تحلیلی که معمولاً کوئریهای سنگین حاوی گروهبندیها، جوینها و توابع تجمعی تودرتو است را به سرعت پاسخ دهد.
- بتوان از ابزارهای پردازش داده مانند اسپارک برای پردازش دادههای آفلاین هم در کنار آن به راحتی استفاده کرد و خروجیهای مورد نیاز برای جداول تحلیلی دورهای و یادگیری ماشین را بدون دغدغه، تولید کرد.
اگر با حوزه داده و بخصوص دیتابیسهای رابطهای موجود آشنا باشید، میدانید که وجود دو مورد میانی فوق یعنی پاسخگویی سریع به پرسوجوهای روزانه در کنار نیازمندیهای تحلیلی، باعث بوجود آمدن نوع جدیدی از دیتابیسها شدهاند که امروزه از آنها به عنوان دیتابیسهای هایبرید یا ترکیبی (HTAP) یاد میکنیم.
البته این نکته را هم باید اذعان کنیم که شرکتها به جای استفاده ازیک دیتابیس ترکیبی، دادههای روزانه و تراکنشی را در دیتابیسهای رابطهای و دادههای تحلیلی را در انبارههای داده و یا دیتابیسهای تحلیلی ( مانند کلیکهوس یا آپاچی دروید) ذخیره میکنند و کمتر به سراغ دیتابیسهای تحلیلی رفتهاند. اما اگر بتوان از یک دیتابیس، به صورت همزمان برای این دو نیاز اطلاعاتی استفاده کرد و کارآیی لازم را به دست آورد، سربار نگهداری دادهها در دو دیتابیس از دوش مهندسین داده شرکتها برداشته خواهد شد.
همانطور که قبلاً هم در سایت مهندسی داده، TiDB را معرفی کرده بودیم، این دیتابیس به عنوان یک راهحل مقیاسپذیر سازگار با مایاسکیوال و مبتنی بر مدل کلید/مقدار (TiKV) به عنوان یک گزینه اصلی برای بیگو، مدتها بر روی میز بود اما تنها دو نیاز ابتدایی آنها را پاسخ میگفت و یک راه حل جامع و موثر برای آنها نبود.
با معرفی TiDB4.0 و افزودن دو امکان اصلی جدید (امکانات اضافه شده در این نسخه بیش از ۷۰ مورد است )، با نام TiFlash و TiSpark ، مجموعه امکانات TiDB، کامل شد و به عنوان گزینه اصلی مهاجرت از مایاسکیوال در بیگو انتخاب شد.
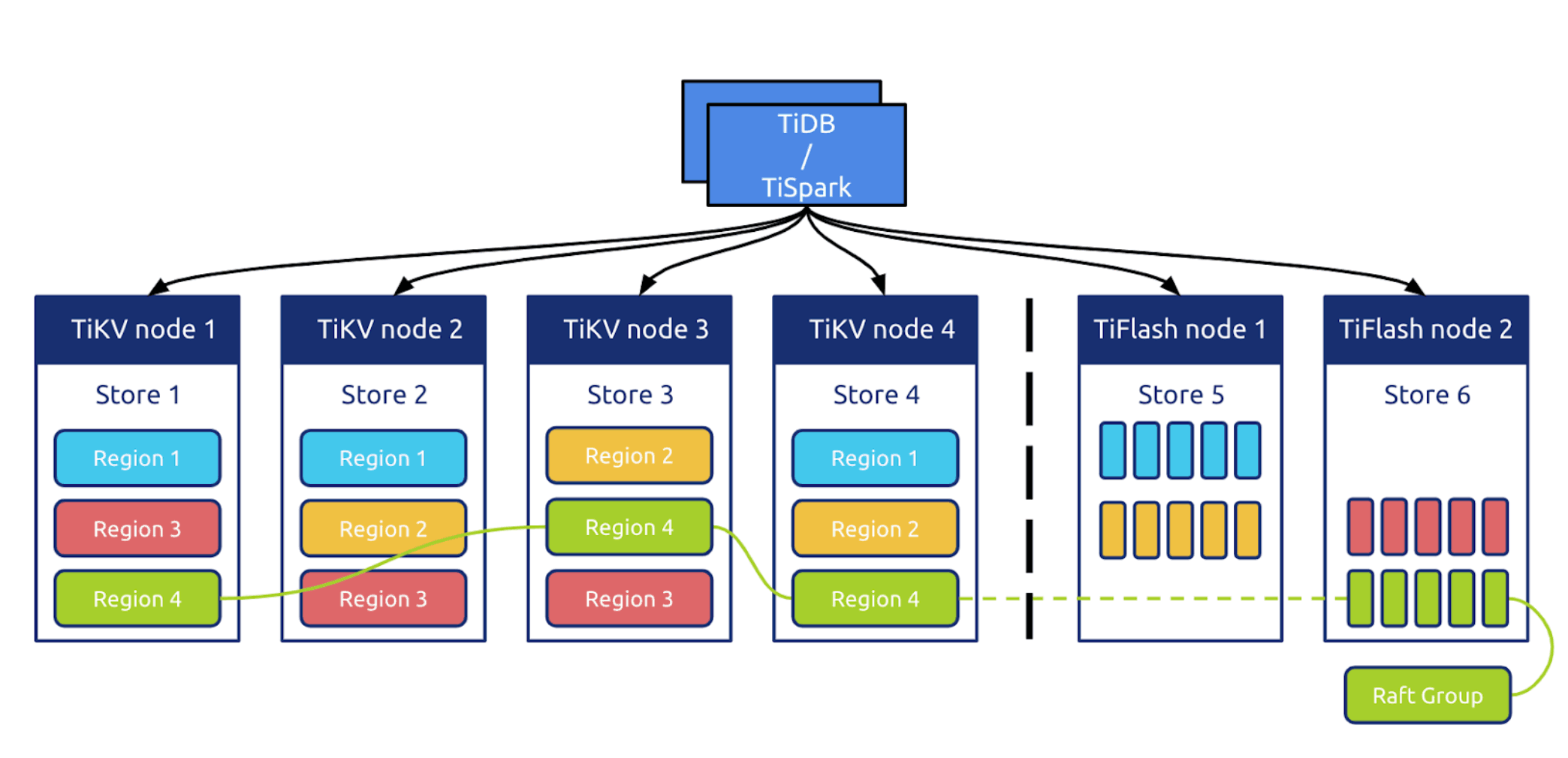
نودهای موجود در یک کلاستر تایدیبی به دو گروه عمده تقسیم میشوند :
- نودهای اصلی (TiKV) : حاوی جداول رابطهای و تکرار شده در کل شبکه که هر یک، بخشی از یک ناحیه یا Region را مدیریت میکنند.
- نودهای تحلیلی یا TiFlash که در حقیقت، تکرار شده دادههای اصلی (Replicated) هستند که آنها را به صورت ستونی ذخیره میکنند. (فرمت ایدهآل برای پرسوجوهای تحلیلی)
پرسوجوهای عادی به کلاستر اصلی حاوی نودهای TiKV ارسال می شود و پرسوجوهای تحلیلی به سمت نودهای TiFlash هدایت شده و توسط بخش تحلیلی، پاسخ داده میشوند. با درج هر داده جدید، نسخهای از آن به صورت خودکار وارد بخش تحلیلی میشود بنابراین همزمان با ورود دادهها میتوان کوئریهای سنگین تحلیلی و آماری را بر روی آنها اجرا کرد.
از طرفی،برای اجرای مدلهای یادگیری ماشین و پردازشهای سنگین دادهمحور میتوان از رابط TiSpark آن استفاده کرد و به صورت مستقیم، دادهها را با اسپارک و در حجم بالا پردازش و تحلیل کرد.
به دو تصویر زیر نگاه کنید :
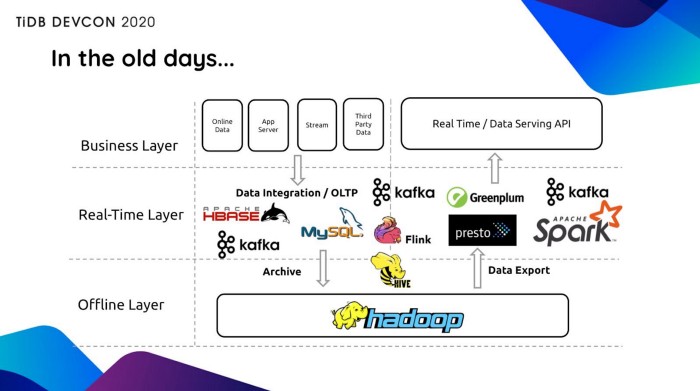
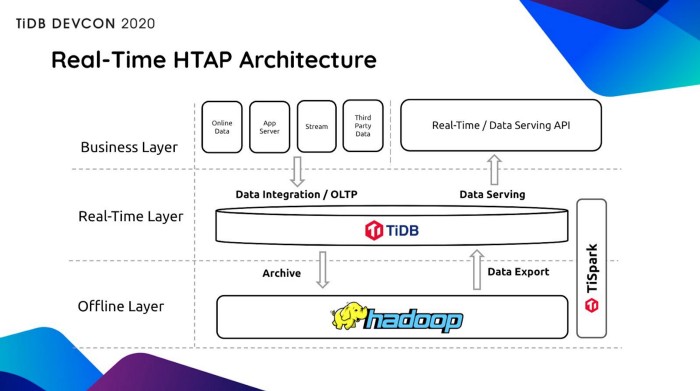
TiDB4.0 وعده داده است که میتواند همزمان نقش تمامی واسطهای بلادرنگ تحلیل داده را ایفا کند و استفاده شرکتهایی مثل Zhihu با حدود ۵۰۰ ترابایت داده و شرکت بیگو با چهارصد میلیون کاربر فعال از آن، اطمینان خاطر اولیه ای به ما میدهد که میتوانیم بر روی امکاناتی که این دیتابیس ترکیبی ارائه کرده است تا حدود زیادی حساب کنیم.
نکته آخر هم اینکه این دیتابیس کاملا مبتنی بر رایانش ابری و حتی به صورت سرورلس طراحی شده است یعنی به کمک کوبرنتیز و تنظیمات لازم، میتوان کاری کرد که در صورت بالارفتن لود درخواستها به صورت خودکار، نودهای پاسخدهنده افزایش یابند و با کاهش این بارکاری، تعداد نودها کاهش یابد . امری که هم رضایت مشتریان را به همراه دارد و هم هزینه کمی را به شرکتها تحمیل میکند. نکته اصلی در این موضوع هم این است که خود TiDB این مقیاسپذیری پویا را برعهده میگیرد.