
مدیریت گرافیکی پروژههای کلانداده با آپاچی نایفای
در ادامه مباحث آشنایی با سامانههای پردازش جریان بنیاد آپاچی به عنوان مهمترین مرجع متنباز در حوزه کلانداده، در این نوشتار به آشنایی با آپاچی نایفای می پردازیم. اکثر قریب به اتفاق کتابخانهها و ابزار آپاچی برای استفاده در یک محیط عملیاتی و همچنین طراحی خطوط پردازش داده، ابزار گرافیکی ارائه نمیکنند و تمام کار بر دوش برنامهنویسان است.
آپاچی نایفای به عنوان یکی از پروژه های نوپای آپاچی با هدف مدیریت گرافیکی و راحت جریان دادهها (Data Workflow) پا به عرصه وجود نهاده است که به کمک آن به صورت گرافیکی و با روش معمول کشیدن ورها کردن (Drag & Drop) میتوانید خط پردازش داده خود را راهاندازی کنید. یعنی داده ها را از نوع منبع داده ای مانند فایل، دیتابیس، هدوپ ، توئیتر و مانند آن به کمک پردازشگرهای گرافیکی از پیش آماده شده، بخوانید، انواع پردازش ها را به کمک پروسسورهای گرافیکی موجود در آن بر روی آنها انجام دهید ونتیجه را هم در منابع مختلف داده ای ذخیره کنید. شکل زیر نمونهای از این مدیریت جریان داده را در نایفای نشان میدهد
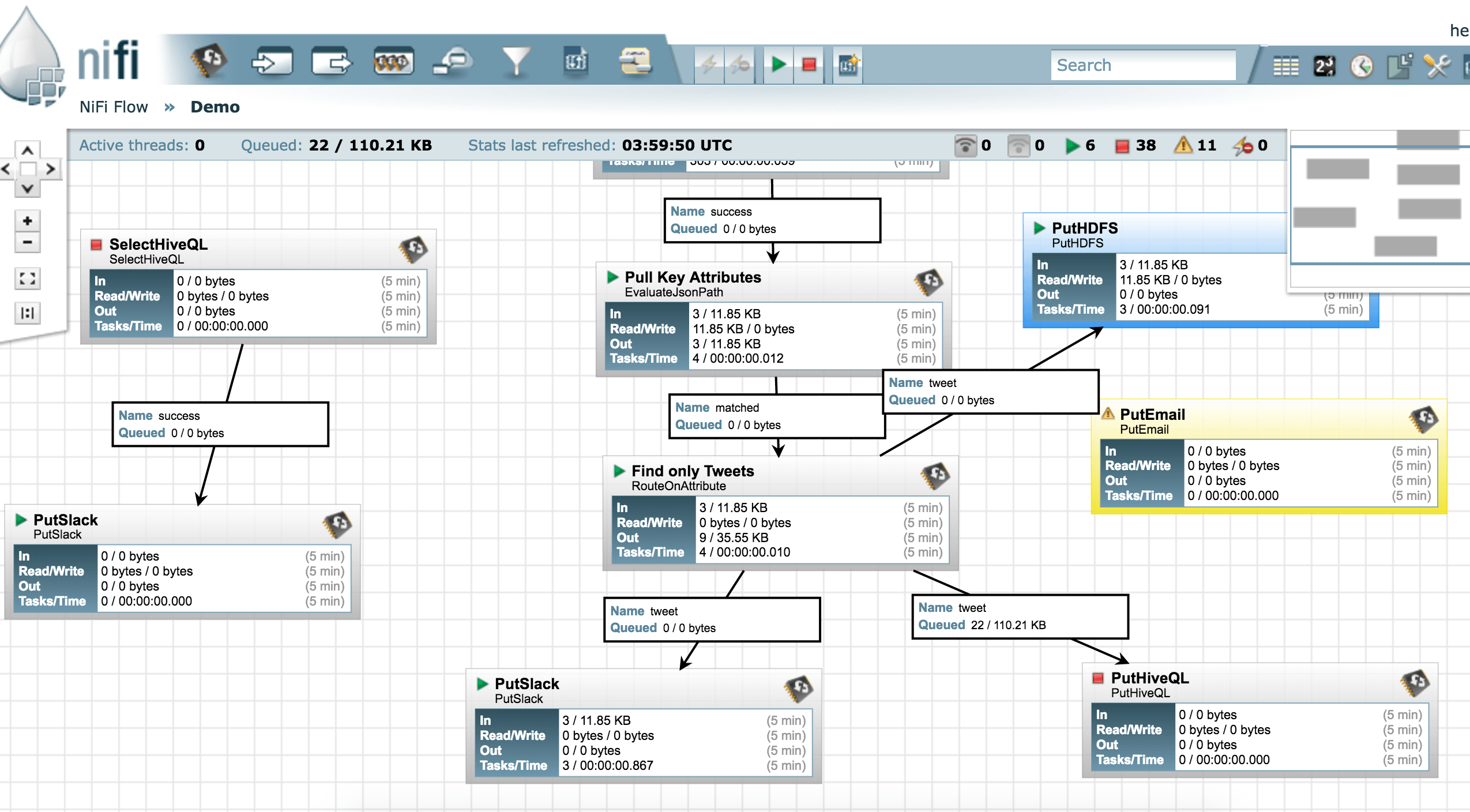
در مقایسه با سایر پروژههای جریانپرداز[۱]، آپاچی نایفای یک پروژه جوان و نوپاست که در سال ۲۰۱۵ به عنوان یک پروژه سطح بالای بنیاد آپاچی پذیرفته شده است.نایفای بر مبنای الگوی تجمیع سازمانی[۲] بنا شده است یعنی مطابق با نیازمندیهای واقعی یک سازمان ایجاد شده است که در طی آن، یک داده از هنگام ورود، وارد مرحلههای مختلف پردازش شده و به شکلهای مورد نیاز و خروجیهای مدنظر کاربران، تبدیل میشود.
آپاچی نایفای با یک محیط بسیار جذاب و خلاقانه عرضه شده است که میتوانید به کمک ابزارهای گرافیکی، به طراحی خط پردازش خود بپردازید که این سهولت طراحی یک سامانه جریان پرداز، از نقاط قوت اصلی نایفای محسوب میشود. امکان اتصال به منابع دادهای ثابت مانند فایلهای HDFS و بانکهای اطلاعاتی و دادههای در حال حرکت یا همان جریانهای دادهای هم جزء نقاط قوت این سامانه است.

این ورودیها میتواند از سیستم فایل محلی، HDFS ، شبکههای اجتماعی، کافکا، FTP، HTTP و JMS خوانده شود و خروجی هم در الاستیک سرچ، آمازون S3 ، AWS ، اسپلانک، سلر و بانکهای اطلاعاتی SQL و NoSQL ذخیره شود. در این بین، انواع تبدیلات و پردازشها میتواند روی دادهها صورت گیرد. تنوع این پردازشگرها و ورودی و خروجیها در نایفای بسیار بالاست . در شکل زیر، همانطور که می بینید ۲۵۱ پردازشگر در تولید خط پردازش داده شما قابل استفاده است :

این پردازشگرها که تعداد آنها به صورت مداوم در حال افزایش است، در گروههای زیر دستهبندی می شوند:
کاربرد عملی آپاچی نایفای
نقش اصلی آپاچی نایفای در تولید سریع خط تولید و پردازش داده به کمک ابزارهای تعبیه شده در آن است.
از طرفی با رواج اینترنت اشیاء، نیاز به سامانههای دریافت و پردازش داده قابل مدیریت، بیش از پیش احساس میشود.آپاچی نایفای، گزینه مناسبی برای کاربردهای اینترنت اشیاء است که سهولت طراحی گرافیکی آن و منابع مختلف ورودی و خروجی آن، برای بسیاری از فعالین این حوزه که دانش عمیقی از بانکهای اطلاعاتی ممکن است نداشته باشند، یک مزیت بسیار مهم است .
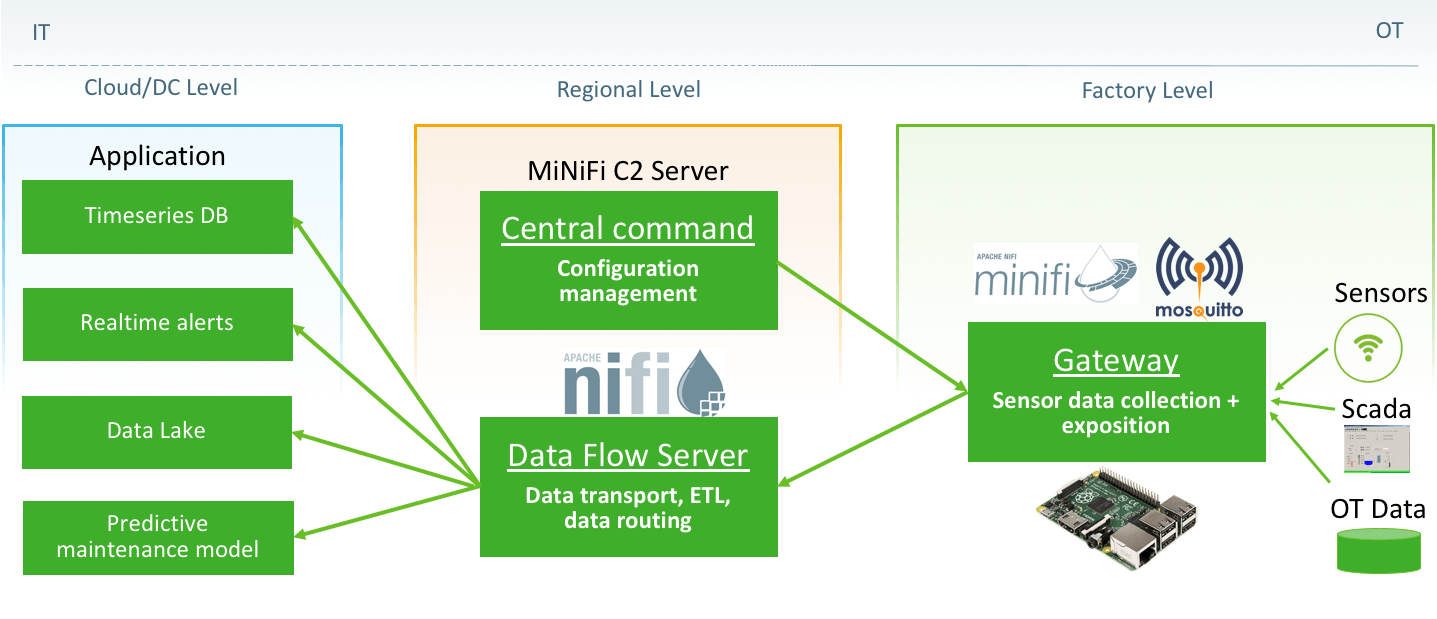
از دیگر سناریوهایی که میتوان با NiFi پیاده سازی کرد، ایجاد مسیر سرد و داغ در تحلیل داده است. توضیح اینکه در سامانههای مدیریت و پردازش اینترنت اشیاء، برخی از دادههایی که توسط حسگرها تولید میشود باید به صورت بلادرنگ پردازش شده، تصمیم مناسب به صورت لحظهای برایشان اتخاذ شود. این دادهها در طراحی یک خط پردازش داده، مسیر داغ را تشکیل میدهند. از طرفی، بسیاری از دادههای ارسالی از حسگرها اهمیت حیاتی و لحظهای ندارند و برای پردازشهای زمانمند باید ذخیره شوند. این نوع از دادهها، در مسیر سرد پردازش قرار میگیرند. ایجاد خطوط پردازش داده موازی و جداگانه برای این دو نوع داده، به راحتی در نایفای امکانپذیر است.
نقاط قوت اصلی نایفای به عنوان یک بازیگر نوپا در حوزه جریانپردازی از قرار زیر است :
- امکان طراحی گرافیکی خطوط پردازش داده
- پردازش همزمان دادههای جریانی / دادههای زمانمند
- اجرا به صورت محلی / تحت شبکه
- کاملاً مقیاسپذیرو قابل توسعه
- مدیریت یکپارچه خطاهای خط پردازش داده
- تضمین تحویل داده به هر گره پردازشی
- بافرینگ دادهها و امکان نظارت بر منابع و جریانهای ورودی
- اولویتبندی صفها
- وجود قالبهای از پیش تعیین شده رایج در پردازش جریان
- ایجاد پرونده داده برای هر داده ورودی با تمام تبدیلهایی که روی آن صورت میگیرد.
نصب و راهاندازی
نصب نایفای نیاز به وجود هدوپ و کامپوننتهای کلانداده ندارد و می تواند مستقلاً نصب و مورد استفاده قرار گیرد اما در محیط های واقعی، برای اتصال به منابعی مانند HDFS، استفاده از اسپارک و مانند آن، نیاز به راه اندازی و نصب هدوپ خواهید داشت.
برای شروع میتوانید از ایمیجهای آماده هورتونورکز استفاده کنید و یا نسخه داکر نایفای را نصب کنید که بدون هیچ پیکربندی خاصی و به سرعت بتوانید کار با آنرا شروع کنید.
بعد از نصب آپاچی نایفای، از این مثال ساده می توانید کار با آنرا شروع کنید. کتاب کمحجم راهنمای شروع به کار نایفای را هم میتوانید به صورت رایگان دانلود کنید و با راهنمایی آن شروع به نصب و کار با این نرم افزار مفید نمایید.

از راهنمای ویدئویی زیر هم برای نصب و راهاندازی نایفای می توانید بهره ببرید :
نایفای در کنار سایر پروژههای آپاچی
از آپاچی نایفای برای ساخت دریاچههای داده یا مدیریت گرافیکی جریانهای داده در یک سازمان هم استفاده کرد. شکل زیر یک مثال عملی از کاربرد نایفای برای خواندن و پردازش توئیت ها را نشان میدهد که حرفهای ترین جریان کار، سطر اول این شکل است که استفاده از آپاچی بیم ما را قادر میسازد در صورت تمایل به تغییر زیر ساخت پردازش داده از مثلا اسپارک به فلینک یا اپکس، این کار را به سرعت و به راحتی بدون تغییر در کدهای نوشته شده، انجام دهیم. درباره آپاچی اپکس و آپاچی بیم در ادامه این سری مقالات توضیح خواهیم داد.
[۱] Stream Processing Systems
[۲] Enterprise Integration Pattern
یکی از قابلیت های خوب و کاربردی دیگه نایفای، وجود پراسسوری با نام ExecuteScript هست که به شما این امکان رو میده با پایتون، جاوا اسکریپت، روبی و چند تای دیگه، پراسسور دلخواه خودتون رو بنویسید و به پایپ لاین اضافه کنید.
https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-scripting-nar/1.8.0/org.apache.nifi.processors.script.ExecuteScript/index.html
https://community.hortonworks.com/articles/75032/executescript-cookbook-part-1.html
با سلام و وقت بخیر.ممنون از مطالب خوب و عالی تون.
یک سوال داشتیم،تفاوت این سیستم های پردازش جریان apache با هم ، در چیست؟
از کجا میشه فهمید که در هر موقعیت، باید از کدوم استفاده کرد؟اسپارک؟نای فای؟ و ….
سلام. این موضوع انتخاب تکنولوژی ، کمی نیاز به تجربه داره و بررسی همه جانبه همه موارد. مثلا اگر تیم در دسترس شما، محدود بوده و نیاز به طراحی خطوط پردازش داده زیادی دارید،نایفای می تواند گزینه مناسبی باشد اما اگر از لحاظ نیروی انسانی مشکلی ندارید ، شاید بهتر باشد برای پردازش جریان داده ها از ترکیب کافکا و اسپارک و یا کافکا و Ray استفاده کنید.
اگر در بین انتخاب چند گزینه، تردید داشته باشید ، همینجا یا به ایمیلی که در تماس با ما گذاشته شده، پیامی بفرستید تا در حد امکان، راهنمایی مورد نیاز انجام شود.