
شروع کار با اسپارک : راه اندازی محیط کار

اسپارک به عنوان یک جایگزین برای روش سنتی توزیع و تجمیع (MapReduce) در هدوپ، به موتور اصلی پردازش داده های حجیم در اکوسیستم های مبتنی بر کلان داده تبدیل شده است . البته شاید برای بعضی کاربردهای خاص که داده های بسیار حجیم و غیر قابل بارگذاری در حافظه دارند، هنوز هم روش توزیع و تجمیع کارآیی بهتری داشته باشد، اما برای اکثر کاربردهای موجود، اسپارک یک جایگزین مناسب تر و کارآمدتر است؛ امری که باعث رواج و گسترش روز افزون آن شده است .
در این سلسله آموزش ها، قصد داریم اسپارک را به زبان ساده به علاقه مندان معرفی کنیم. برای این منظور از حسابهای کاربری رایگان سایت DataBricks که توسط برنامه نویس اصلی اسپارک راه اندازی شده است، استفاده خواهیم کرد و به کمک کتابچه های پایتون یا اسکالا، با برنامه نویسی اسپارک، به صورت آنلاین و بدون نصب کتابخانه یا نرم افزار خاصی، آشنا خواهیم شد.
توصیهای برای نصب سریع اسپارک
اگر مایل به نصب اسپارک روی سیستم خود هستید، توصیه می کنم از داکر استفاده کنید و به کمک این مستندات، آنرا بر روی یک ماشین مجازی نصب کرده ، کار با آن را شروع کنید. اگر هم روش ساده تری برای نصب محلی آن نیاز دارید، از ایمیج های آماده هدوپ استفاده کنید.
ساخت اکانت و ایجاد اولین کتابچه پایتون برای کار با اسپارک
برای شروع کار با اسپارک، از بخش آزمایش سایت Databricks نسخه رایگان (Community) آنرا انتخاب و با گزینه Sign Up در آن، ثبت نام کرده و یک حساب کاربری ایجاد کنید. ایمیلی به شما زده خواهد شد که با کلیک بر روی لینک موجود در آن، حساب کاربری شما فعال و به صفحه لاگین هدایت خواهید شد. پس از ورود، داشبورد یا پیشخوان شما شبیه شکل زیر خواهد بود :
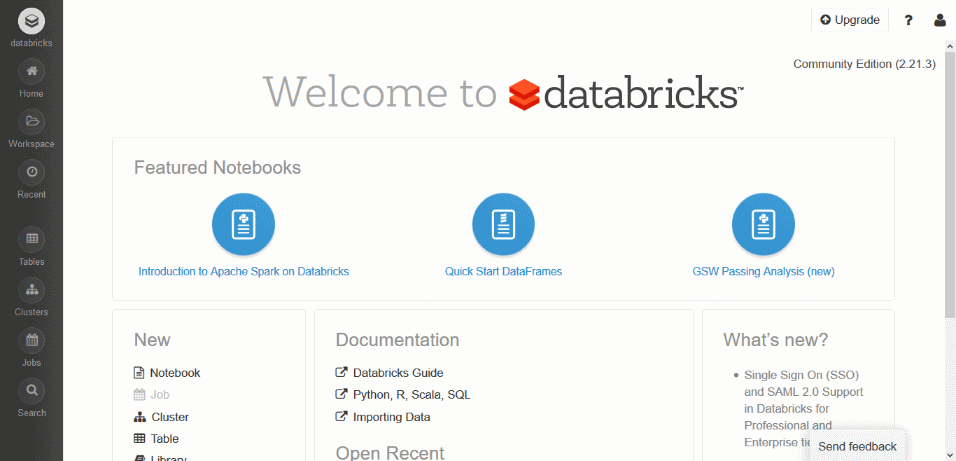
با ساخت یک اکانت رایگان در سایت دیتابریکز، یک فضای شش گیگابایتی درون یک کانتینر به همراه یک هسته CPU به شما اختصاص داده می شود و چون هر کاربر درون کانتینر خودش به اجرای کدها خواهد پرداخت، امکان اجرای هر نوع کد و نصب هر کتابخانه ای را بدون نگرانی از اینکه آسیبی به جایی زده شود را خواهد داشت .
لازم به ذکر است که درون این اکانت رایگان، تنها قادر به ساخت یک کلاستر خواهید بود که این کلاستر هم تنها از یک هسته پردازشی تشکیل شده است که برای کارهای آموزشی و اولیه، کاملاً مناسب و کار راه انداز است.
مهم ترین بخش های این داشبورد عبارتند از :
- Workspace (فضای کار): این بخش که حاوی فایلهای کتابچه ها، کتابخانه های جاوا و پایتون مورد نیاز و سایر فایلهای مورد نیاز و مورد استفاده شماست، مثلاْ برای نصب یک کتابخانه پایتون کافیست با کلیک بر روی Workspace از منوی کشویی باز شونده، روی گزینه Create و بعد کتابخانه کلیک کنید و از صفحه ای که ظاهر می شود، گزینه Upload Pyton Egg or PyPi را انتخاب کرده و نام کتابخانه پایتون خود را وارد کنید تا آن کتابخانه به راحتی و به سرعت نصب شود .
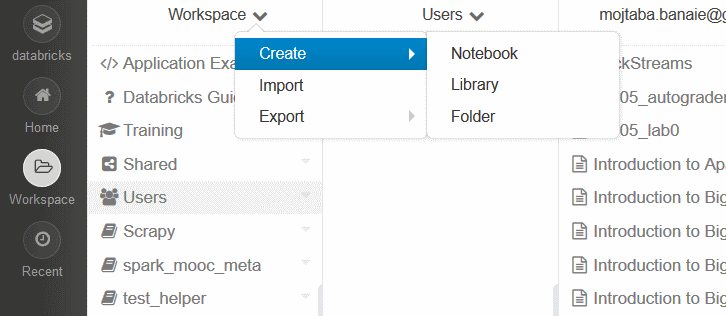
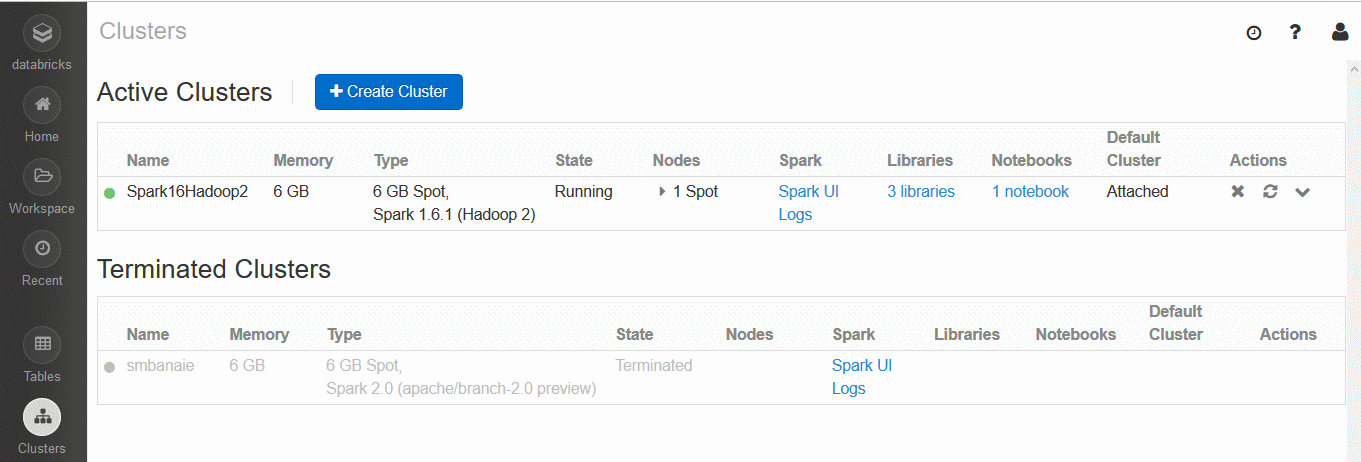
- Clusters : این بخش برای مدیریت و نظارت بر کلاستر یا کامپیوترهای موجود در شبکه برای اجرای اسپارک ، به کار می رود که البته در نسخه رایگان کلاْ یک کلاستر حاوی سیستم و یک هسته را در اختیار خواهید داشت اما هنگام اجرای دستورات اسپارک می توانید به این بخش رجوع کنید و لاگ ها و کارهای در حال انجام را نظارت و مشاهده کنید(از زبانه SparkUI). در ابتدا یادتان نرود که یک کلاستر ایجاد کنید و نسخه اسپارک مورد نیاز را تعیین نمایید.(در حال حاضر نسخه ۲ به صورت پیش نمایش هم در دسترس است که می توانید با اسپارک ۲ که هنوز وارد بازار نشده است هم کار کنید .) با اجرای هر دستور درون یک کتابچه ، آن دستور باید به یک کلاستر متصل شود که البته این کار به صورت خودکار هم انجام میگیرد .
- Tables : گاهی اوقات لازم است که داده های خود را آپلود کنید و مشابه یک جدول، داده های درون آنرا مشاهده و بررسی کنید. در این بخش می توانید هم داده های خود را آپلود کنید که آدرس داخلی از سرورهای دیتابریکز به شما داده می شود و درون کدهای اسپارک می توانید مستقیماْ DataFrame های خود را از روی این داده ها بسازید و هم می توانید بعد از آپلود ، ساختار داده ها و خود داده ها را مشاهده و بررسی کنید.
- سایر منوها را به تدریج و در حین کار فراخواهید گرفت و نیاز چندانی به توضیح ندارد. برای آشنایی بیشتر با این محیط ، کافیست از منوی فضای کار، گزینه DataBricks Guide را انتخاب کنید و با منوها و امکاناتی که سرویس آنلاین دیتابریکز در اختیار شما می گذارد، بیشتر آشنا شوید .
تنظیمات اولیه
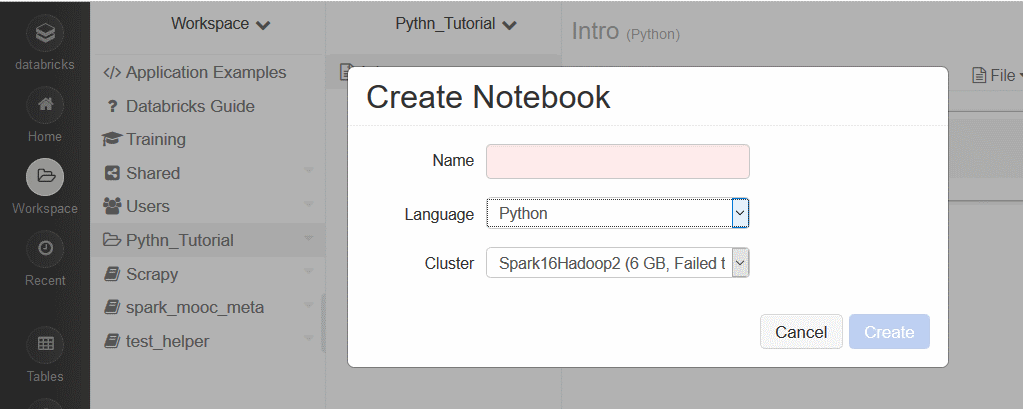
با توضیحات فوق ، حتماً دستتان آمده است که ابتدا باید یک کلاستر ایجاد کنید. این کار را با مراجعه به منوی Clusters انجام دهید و نوع کلاستر را اسپارک ۱.۶ انتخاب کنید. سپس پوشه ای را درون فضای کار خود ساخته و با کلیک راست روی آن پوشه و یا از منوی ظاهر شونده در بخش فوقانی صفحه بعد از کلیک روی پوشه، یک کتابچه درون آن ایجاد کنید (Create Notebook). زبان کتابچه را برای این آموزش، پایتون انتخاب کنید. با اینکار یک کتابچه خالی خواهید داشت که می توانید کار کدنویسی و آزمایش اسپارک را به کمک آن آغاز کنید.
نحوه کار با سلول ها در کتابچه ها
کتابچه شما در ابتدای کار، مشابه شکل زیر خواهد بود و اولین سلول به طور خودکار ایجاد شده و آماده نوشتن کدها توسط شماست :
در جایی که علامت < ظاهر شده است می توانید شروع به نوشتن کدهای خود نمایید . برای شروع چند دستور پایتون را خواهیم نوشت (اگر هم پایتون کار نکرده اید اصلا نگران نباشید با دیدن همین نمونه کدها راه خواهید افتاد اما اگر می خواهید یک مرور کلی و سریع بر پایتون داشته باشید از این آموزش ساده استفاده کنید.)
در هر خانه یا سلول کتابچه ،یا می توانیم کد بنویسیم یا می توانیم با فرمت مارک داون، توضیحات و یادداشت بنویسیم . ترکیب متن و کدها که به کتابچه ها قابلیت اجرا شدن در کنار مستندات و توضیحات را میدهد، کتابچه ها را به ابزاری ایده آل برای اشتراک دانش و نمایش نتایج تبدیل کرده است.
بعضی دستورات خاص در کتابچه ها وجود دارند که به آنها دستورات جادویی گفته میشود و با علامت % شروع می شوند. با نوشتن دستور lsmagic% می توانید فهرست این دستورات را مشاهده کنید. (بسیاری از دستورات لینوکس را هم در بین این لیست مشاهده می کنید.) مهمترین این دستورات جادویی که اینجا به آن نیاز خواهید داشت دستور md% است که ابتدای هر سلول که قصد نوشتن توضیحات و متون مارک داون را دارید باید نوشته شود.
نکته مهمی که درباره اجرای یک سلول باید بدانید این است که کل یک کتابچه مانند یک فایل عمل می کند و متغیرهای یک سلول درون سلول بعدی قابل استفاده است. بنابراین اگر قصد اجرای یک سلول را دارید که به متغیرهای قبل از خود وابسته است، تمام سلولهای مورد نیاز آن ابتدا باید اجرا شوند؛ در غیر اینصورت، هر سلول به صورت مستقل و جداگانه می تواند اجرا شود. برای اجرای کل کتابچه می توانید از گزینه Run Alll در بالای آن استفاده کنید.
برای اجرای هر سلول هم کافیست درون سلول قرار گرفته و کلیدهای ترکیبی Ctrl+Enter یا Shift+Enter استفاده کنید (دومی پس از اجرا یک سلول جدید در ادامه کتابچه و بعد از این سلول ایجاد می کند ). لیست کلیدهای میانبر را با کلیک بر روی Shortcuts در زیر یک سلول می توانید ببینید . (شاید بهتر باشد قبل از ادامه کار نگاهی به فوت و فنهای کار با کتابچهها به قلم محمد چناریان هم بیندازید)
نوشتن دستورات معمول پایتون
چند دستور معمول و اولیه پایتون را می نویسیم و خروجی آنها را مشاهده می کنیم . اگر اولین کدهای پایتون شماست دو نکته را دقت کنید که اولاْ پایتون به تورفتگی دستورات بسیار حساس است و دستورات هم سطح مانند دستورات داخل یک حلقه باید کاملا زیر هم قرار گیرند و از دستور پدر هم حداقل یک فضای خالی ، فاصله داشته باشند و دوم هم اینکه در پایتون تعریف متغیر نداریم و هر متغیری هر نوع داده ای را می تواند در خود ذخیره کند. دستورات زیر را نوشته و سلول را اجرا کنید. اگر دفعه اول است که قصد اجرای یک سلول از یک کتابچه را در دیتابریکز دارید، احتمالا با پنجره زیر مواجه می شوید:
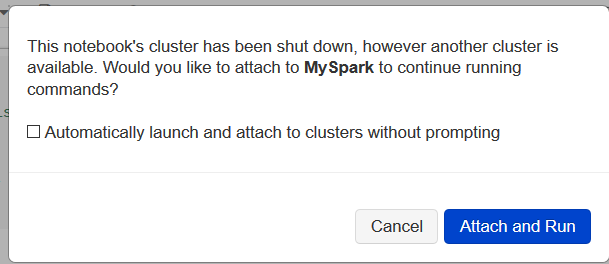
که بیان می کند برای اجرای این کتابجه و این سلول ، باید آنرا به یک کلاستر (مجموعه گره های محاسباتی یا همان رایانه های تحت شبکه که اسپارک بر روی آنها اجرا میشود) ، متصل کند که اگر کلاستر خود را ساخته باشید نام آنرا به شما نشان داده و از شما سوال می کند که این کتابچه را به کلاستر مورد نظر متصل کند یا نه . دکمه آبی رنگ را بزنید تا بعد از زمان کمی که بابت متصل کردن کتابچه به کلاستر صرف خواهد شد، نتیجه اجرای آنرا مشاهده کنید .
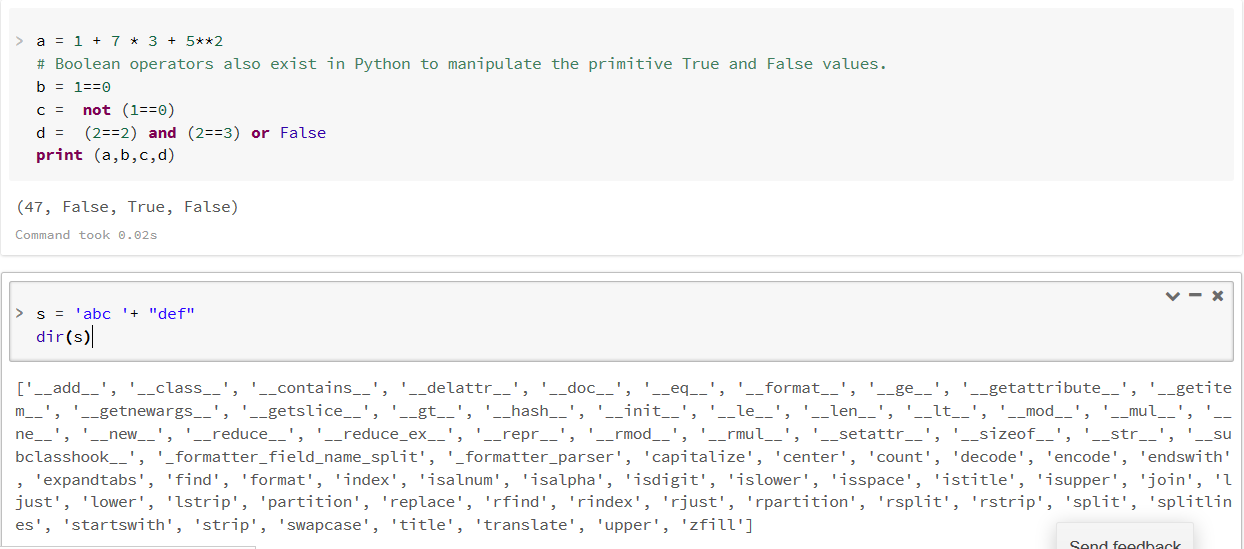
در سلول دوم ، متغیری از نوع رشته تعریف کرده ایم و با دستور dir(s) تمام توابعی که روی رشته می توانیم صدا بزنیم را لیست کرده ایم . فرض کنید از بین این توابع ، می خواهیم راجع به تابع find اطلاعات بیشتری به دست آوریم . کافیست با دستور help(s.find) جزییات آنرا مشاهده کنیم.
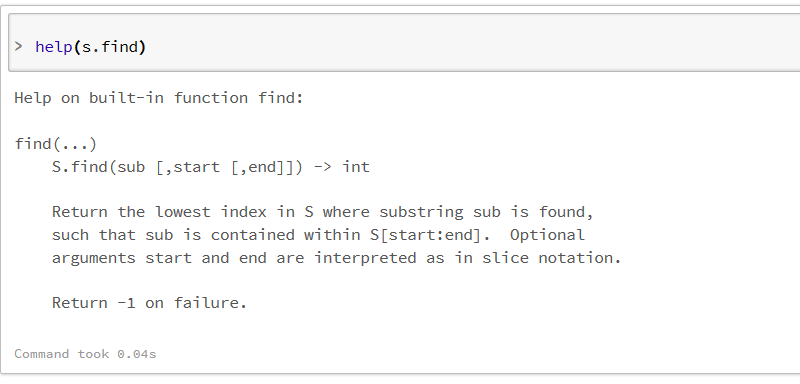
این روند را برای توابع و کلاسهای مورد استفاده در اسپارک هم می توانیم انجام دهیم و در لحظه، راهنمایی مورد نیاز را دریافت کنیم .
می توانیم از کتابخانه های استاندارد پایتون هم با دستور import استفاده کنیم و یا کتابخانه های مورد نیاز را با ایجاد یک کتابخانه در فضای کاری و وارد کردن نام استاندارد کتابخانه به فضای کاری اضافه کرده و ابتدای کتابچه یا هر سلول مورد نیاز، آنرا import کنیم . مثلاً قطعه کد زیر از کتابخانه DateTime تاریخ و زمان جاری سیستم را به دست آورده ، چاپ می کند :
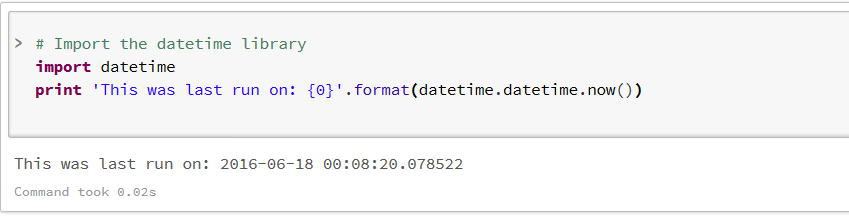
قبل از ادامه آموزش، اگر با پایتون قبلاْ کار نکرده اید، این آموزش مختصر پایتون را بررسی کرده و کدهای آنرا در این کتابچه، حتماً اجرا کنید . بخصوص بخش لیست ، تاپل، مجموعه و دیکشنری که جزء ساختمان داده های اصلی پایتون و نیز پردازش داده محسوب می شوند.
آشنایی با مفهوم بستراجرایی و نحوه اجرای دستورات در اسپارک
روند اجرای دستورات و کارها در اسپارک به این صورت است که به ازای هر برنامه کاربر، یک هماهنگ کننده و مدیریت کار به صورت خودکار ایجاد می شود که به آن Driver می گوییم . این مدیربرنامه، داده ها را بین کلاستر توزیع کرده و سپس کارهایی که قرار است روی این داده ها انجام شود را به اجراکننده ها یا Executors تحویل می دهد و بعد از اجرای برنامه ها در تک تک سیستم های تشکیل دهنده کلاستر، نتایج را جمع آوری و به کاربر نمایش می دهد. برای اینکه در برنامه های ما ، تمام اینکارها به صورت خودکار انجام شود، کتابخانه هایی ایجاد شده است که این عملیات را به صورت خودکار و پشت صحنه برای ما انجام می دهد که ما برای هر برنامه ، بستراجرایی اسپارک یا همان کتابخانه اصلی مورد استفاده خود را تعیین می کنیم تا دستورات بتوانند به درستی اجرا شوند.
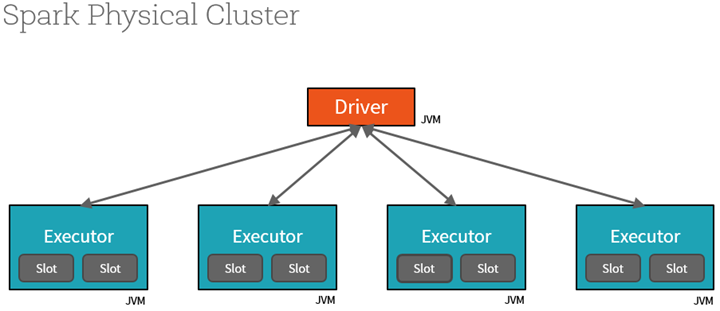
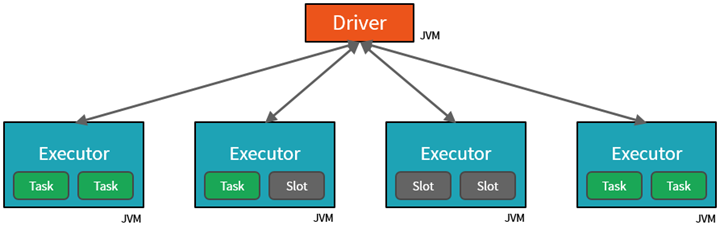
البته در نسخه ای که به رایگان در اختیار شما در سایت Databricks قرار گرفته است،تنها یک مدیر برنامه محلی و یک اجراکننده دارید که تمام کارها توسط همین دو مولفه، بدون توزیع در شبکه انجام خواهد گرفت و حتی دستورات مبتنی بر شبکه هم به صورت محلی اجرا خواهد شد.
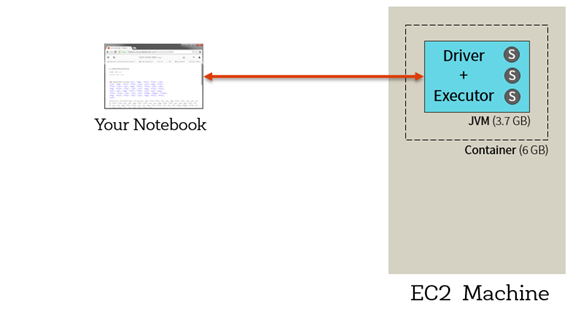
اصلی ترین و معروفترین این کتابخانه ها در اسپارک سری یک، SparkContext که با نام مخفف sc در دسترس ماست . البته در نسخه ۲ اسپارک که جدیداً به بازار آمده است، نام بستراجرایی اسپارک به Spark تغییر کرده است. کافیست دستور help(sc) را در یک سلول نوشته و آنرا اجرا کنید تا هم از وجود این مدیر برنامه مطمئن شوید و هم توابع مختلف آنرا مشاهده کنید.
دستور زیر را اجرا کنید تا نسخه فعلی اسپارک را مشاهده کنید :
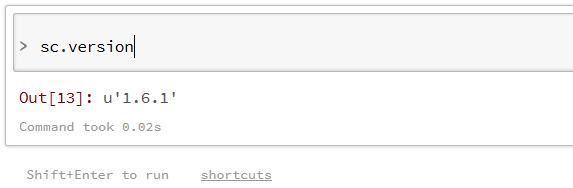
اگر تا اینجا همه چیز به خوبی پیش رفته است، برای بخش دوم آموزش که شروع کار با اسپارک و انجام چند مثال عملی خواهد بود، آماده شده اید.
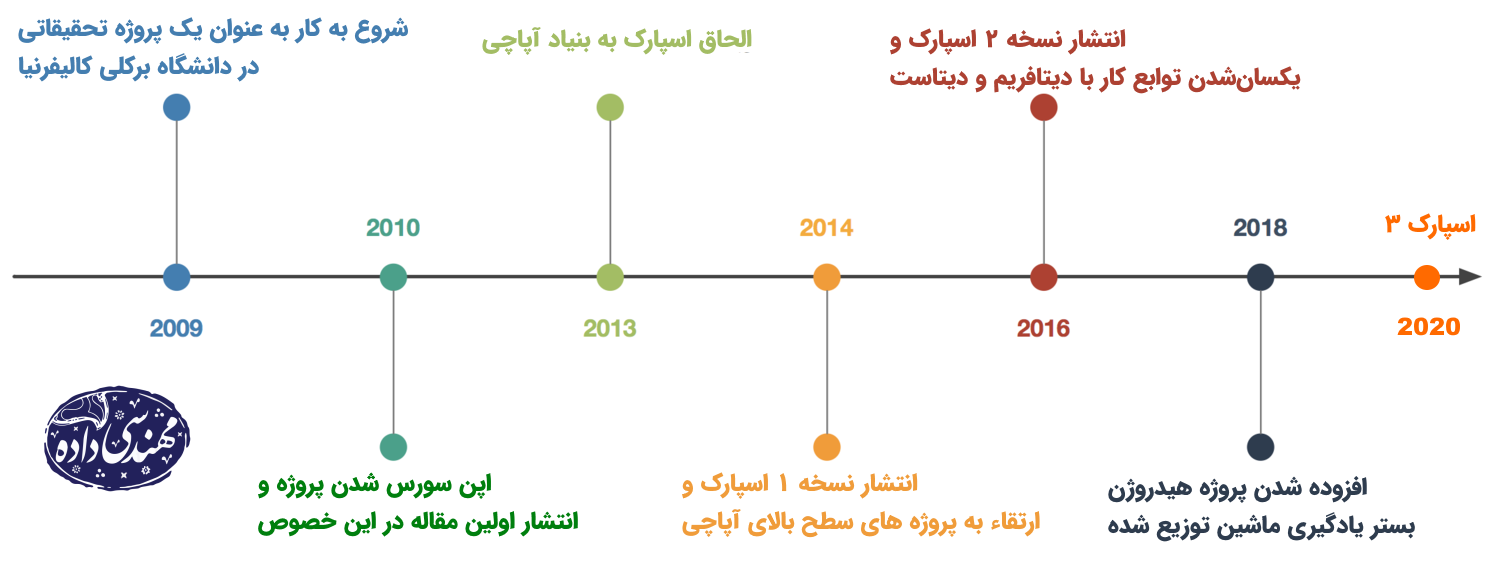
مروری بر تاریخچه اسپارک
با سلام
بنده دانشجوی ترم آخر کارشناسی ارشد رشته الگوریتم و محاسبات دانشگاه تهران هستم و از مطالب سایت شما بسیار لذت بردم و استفاده کردم. به عنوان عضو بسیار کوچکی از جامعه مهندسین از شما بخاطر مطالب مفیدتان که در سایر سایتهای فارسی زبان کمتر پیدا می شود تشکر می کنم.
سلام.
بسیار عالی/ خلاصه و مفید