

در بخش دوم از سری آموزشهای پردازش متون فارسی با پایتون با توجه به اینکه در ادامه کار، نیاز به مجموعه ای از متون فارسی برای پردازش خواهیم داشت، تصمیم گرفتم نحوه استخراج متون از سایتها را با کتابخانه Scrapy توضیح دهم. سعی کرده ام که کدها بسیار ساده و برای اکثریت جامعه مخاطبان ، قابل فهم و استفاده باشد. در این مقاله، استخراج اطلاعات متنی خبرگزاری ایسنا را توضیح داده ایم .
چرا Scrapy ؟
یکی از منابع اصلی داده در دنیا ، متون و مطالب موجود در سایتهای اینترنتی است مانند نظرات کاربران، اخبار روزانه، فروشگاه ها و محصولات، مقالات تخصصی، شبکه های اجتماعی و مانند آن که نیاز به دسترسی به این منبع بزرگ، ابزارها و کتابخانه های مختلفی را برای استخراج حرفه ای و ساده داده ها از آن ایجاد کرده است. یکی از کتابخانه ها و یا اگر دقیقتر بخواهیم صحبت کنیم، چارچوب های معروف پایتون در خواندن و استخراج اطلاعات مفید از صفحات وب ، کتابخانه Scrapy است که به چند دلیل آنرا برای استخراج متون انتخاب کرده ایم ، اول اینکه یک چارچوب کامل برای خزش در وب (Crawling) با قابلیت دنبال کردن لینک های موجود در هر صفحه و استخراج تمام لینک های یافت شده است . دوم اینکه برای پردازش موازی و همزمان صفحات مختلف و ایجاد خط تولید (pipeline) امکانات مناسب و ساده ای دارد که سرعت کار را بالا می برد و آخرین نکته هم اینکه کار با آن بسیار ساده است و در کمتر از ده خط ، شما یک خزنده وب (برنامه ای که اطلاعات سایت ها را استخراج و لینک های آنها را برای اطلاعات جدید بررسی می کند) تمام عیار می توانید بسازید .
نصب Scrapy
مشابه سایر برنامه های پایتون کافیست با دستور pip install scrapy این کتابخانه را نصب کنید . برای اجرای آن نیاز به نصب بعضی کتابخانه ها و نرم افزارهای موردنیاز آنرا هم داریم که اکثر آنها با دستور فوق به صورت اتومات نصب خواهند شد و تنها چیزی که باقی می ماند نرم افزار PyWin32 است که بعضی امکانات خاص ویندوز را برای برنامه های پایتون، فراهم می کند. اگر با دستور pip install pywin32 در خط فرمان سیستم، نصب نشد، آنرا از این آدرس، دانلود و نصب کنید (برای اکثر شما نسخه ۳۲ بیتی نرم افزار مناسب خواهد بود) . اکنون آماده استخراج اطلاعات هستید. اگر باز هم در نصب اسکرپی به مشکل برخوردید، بخش اول این مقاله را که با شکل و به صورت کامل نحوه رفع آنها را توضیح داده است از دست ندهید.
ساخت آنلاین یک خزنده وب و اجرای آن
به جای نصب اسکرپی و پایتون بر روی یک سیستم، همواره می توانید یک پروژه جدید در فضای کاری کتابچههای مایکروسافت به صورت آنلاین ایجاد کنید و کدهایی که در ادامه میآید را به صورت آنلاین اجرا کنید. فقط برای اجرای دستورات اسکرپی (دستوراتی که در خط فرمان و با کلمه scrapy شروع میشود) یک کتابچه پایتون در آن ایجاد کرده و برای هر دستور یک سلول جدید ایجاد کنید و با گذاشتن علامت ! در ابتدای سلول، دستور اسکرپی را نوشته و دکمه اجرا را بزنید تا دستورات خط فرمان درون فضای کاری شما اجرا شود. لینک همین پروژه درون فضای کاری آنلاین مایکروسافت در انتهای همین آموزش آمده است.
ساخت یک پروژه
در این آموزش، می خواهیم عنوان و متن تعدادی از اخبار سایت ایسنا (خبرگزاری دانشجویان ایران )را استخراج کنیم. بعد از نصب اسکرپی، در خط فرمان، دستور زیر را وارد می کنیم تا ساختار اولیه یک پروژه اسکرپی برای ما ایجاد شود
با این دستور خروجی زیر را خواهید دید :
همانطور که مشاهده می کنید یک پوشه با نام isna_crawler ساخته خواهد شد که ساختار داخلی این پوشه از قرار زیر است :
تنظیمات متعدد اسکرپی، در فایل settings.py قرار دارد که برای مقاصد فعلی، به پیش فرض ها بسنده می کنیم و به این فایل کاری نداریم . فایل items.py ساختار داده هایی که قصد استخراج آنها را داریم مشخص می کند (چه اطلاعاتی از هر صفحه باید استخراج شوند ) . تنظیمات سراسری اسکرپی مانند مکان قرارگیری فایل تنظیمات هم در فایل scrapy.cfg قرار میگیرد که این فایل را هم دست نخورده باقی می گذاریم. فایل pipelines.py برای ساخت یک خط تولید پیشرفته و مرحله به مرحله استفاده می شود که خوانندگان حرفه ای تر به آن نیاز خواهند داشت (مشابه این مثال که خواندن اطلاعات و ذخیره آنها در مانگو را به صورت خط تولید انجام داده است) و نهایتاً در پوشه spiders کدهای خزنده ما قرار خواهند گرفت .
ساخت خزنده وب برای استخراج لینکها و دادهها
با مقدمه فوق به مرحله اصلی کار یعنی نوشتن کد خزنده و استخراج اطلاعات می رسیم. دستور زیر را در خط فرمان تایپ و اجرا کنید تا خزندهای با نام Isna برایتان ایجاد شود (خزنده : برنامه استخراج کننده لینکهای یک سایت و اطلاعات آنها) :
با این کار، خزنده اولیه شما با نام Isna.py در پوشه spiders ساخته خواهد شد که ساختاری شبیه به زیر دارد :
همانطور که میبینید یک کلاس با نام IsnaSpider که فرزند scrapy.Spider است، ایجاد می شود. در ابتدای این کلاس، نام اسپایدر که در ادامه برای اجرای خزنده به آن نیاز خواهیم داشت برابر Isna گذاشته شده است که همان نامی است که در خط فرمان وارد کردهایم. متغیر allowed_domains حاوی لیست دامنههایی است که خزنده وب، مجاز به استخراج لینکهای آنهاست که برای اکثر سایتها این لیست فقط حاوی نامه دامنه اصلی است. متغیر start_urls هم حاوی لیستی از آدرسهایی است که شروع استخراج لینکها با آنها خواهد بود.
یک نکته مهم : scrapy.Spider سادهترین خزنده اسکرپی است که بر اساس لینکهای موجود در start_urls کار میکند و ساخت الگوهای پیچیده استخراج اطلاعات به کمک آن به سادگی میسر نیست. بنابراین از کلاس CrawlSpider به جای آن استفاده خواهیم کرد یعنی تعریف کلاس به صورت class IsnaSpider(CrawlSpider) در خواهد آمد. نمونه کامل کد در ادامه آمده است.
تا اینجا هیچ قانون استخراج لینکی ننوشتهایم و تابع parse هم هیچ جا صدا زده نشده است بنابراین خزنده پیشفرضی که برای ما ساخته شده است، تنها اسکلت کلاس اولیه را برای ما ساخته است و دادهای برای ما استخراج نمیکند. با اینحال برای اینکه آزمایش کنیم همین خزنده پایه، بدون اشکال اجرا خواهد شد، در خط فرمان دستور scrapy crawl Isna را وارد کنید تا خزنده وبی که با نام Isna ساختهایم، شروع به کار کند. البته خروجی خاصی برای شما تولید نخواهد شد و فقط بررسی کنید که خطایی تولید نشده باشد.
اگر با پایتون آشنا نیستید ..
اگر با پایتون کار نکردهاید، نگران نباشید. اصولاً کدهای پایتون بسیار ساده و قابل فهم هستند و با بررسی همین مثال میتوانید کار خود را با این زبان شروع کنید. فقط اگر با پیشزمینه زبانهای شبیه C وارد این زبان میشوید در شروع کار حواستان به فضای خالیها باشد که پایتون برای تشخیص شروع و انتهای یک بلاک، از تورفتگیها استفاده میکند و حتی یک فضای خالی نابجا، باعث عدم اجرای کدهای شما خواهد شد.
بررسی صفحات سایت و اتخاذ سیاست مناسب
بعد از راهاندازی اولیه اسکرپی، به بررسی سایتی که قصد استخراج اطلاعات آنرا داریم، میپردازیم و دو موضوع زیر مشخص میکنیم :
- اطلاعات مورد نیاز ما در چه صفحاتی قرار گرفتهاند ؟
- چگونه به آن صفحات برسیم ؟ يا به عبارتی دیگر، لینک رسیدن به آن صفحات را چگونه استخراج کنیم ؟
برای مثال با هم به صفحه اول سایت ایسنا نگاهی میندازیم :
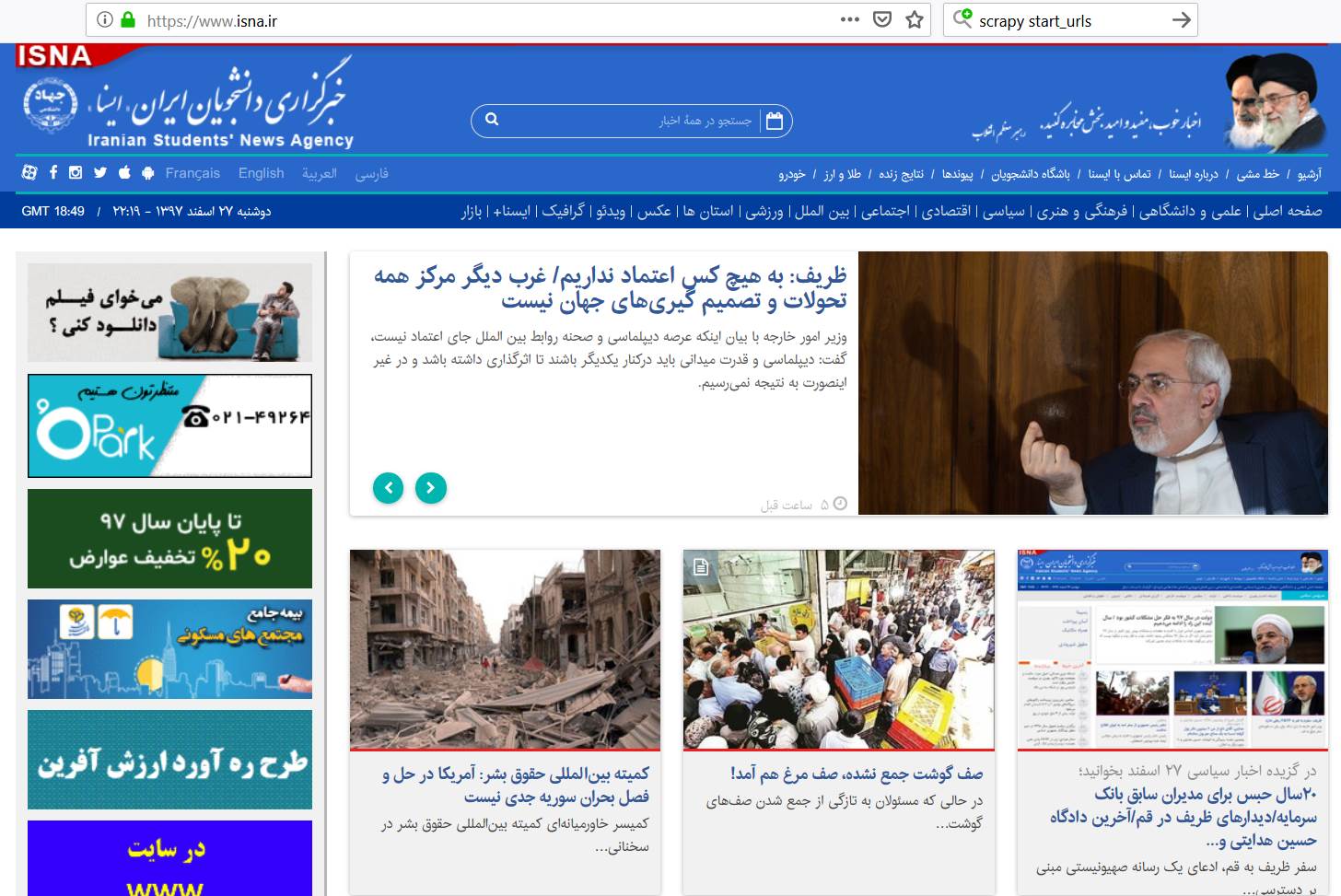
کافی است بر روی هر خبر کلیک کنیم تا به صفحه خبر منتقل شویم :
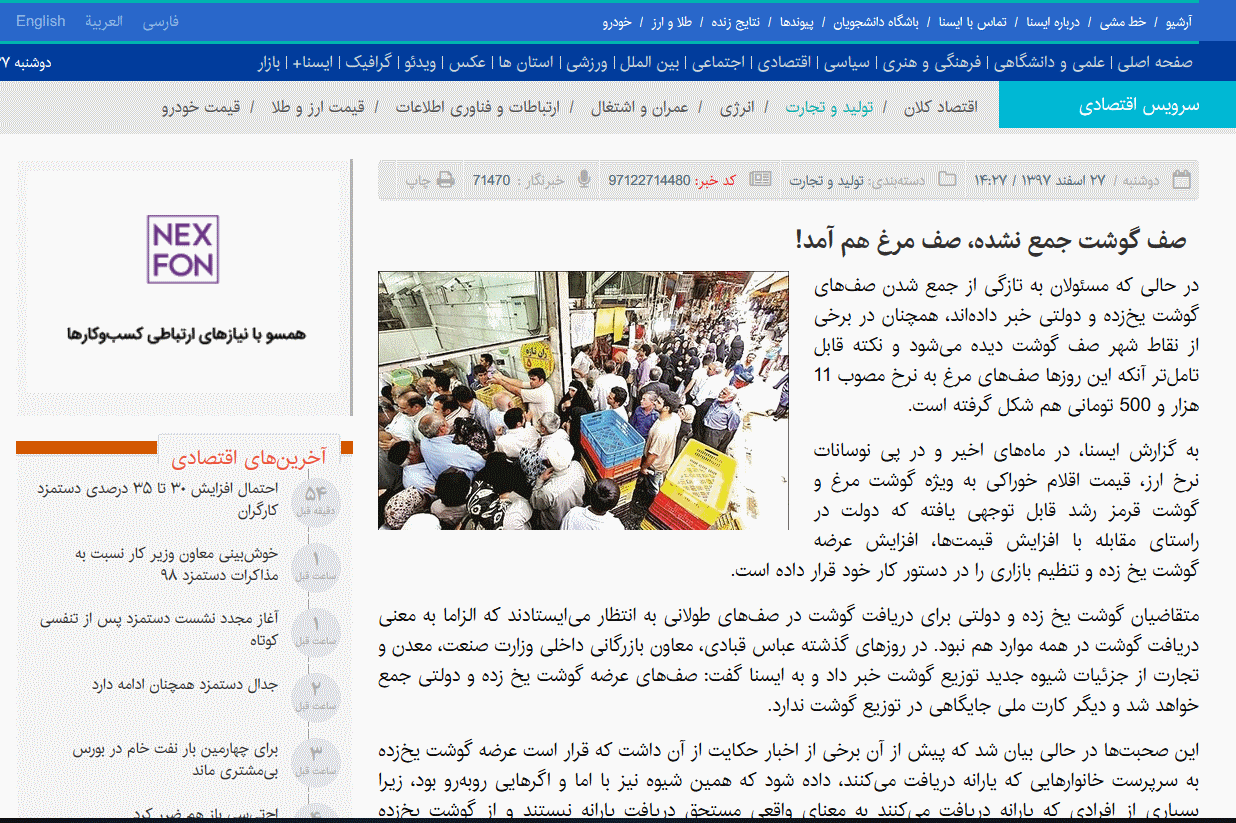
اطلاعاتی که راجع به یک خبر به آنها نیاز داریم مانند عنوان، تاریخ، گروه خبری، برچسبها، متن خبر و مسایلی از این دست همه در این صفحه قرار گرفتهاند. به آدرس بالای صفحه خبر نگاه می کنیم و قالبی مشابه زیر برای یک خبر مشاهده می کنیم :
روی چندین خبر مختلف و در گروههای خبری گوناگون کلیک میکنیم تا مطمئن شویم ساختار لینک هر خبر به همین صورت است و اگر چندین ساختار برای اخبار یافتیم، حواسمان خواهد بود که آنها را در قوانین استخراج لحاظ کنیم.
دست به کد: جمع آوری و تحلیل دادههای توئیتر فارسی در چند دقیقه
اگر قصد جمعآوری و تحلیل دادههای فارسی در شبکههای اجتماعی و بخصوص توئیتر را دارید، به کمک این آموزش گام به گام و به مدد امکانات آنلاین مایکروسافت، در چند دقیقه و بدون نیاز به نصب نرم افزار یا حتی آشنایی با برنامهنویسی، شروع به جمع آوری و تحلیل دادههای توئیتر نمایید.
در ادامه کار باید ببینیم چگونه اخبار مورد نیاز خود را جمع آوری کنیم. در صفحه اول و در بالای صفحه، گروههای خبری مختلف را مشاهده میکنیم و به عنوان اولین سعی، بر روی یکی از آنها کلیک می کنیم. در صفحه دومی که باز می شود لیست اخبار آن گروه خبری و همچنین زیردستههای آن نمایش داده میشوند. آدرس هر گروه خبری هم سرراست و منظم است مثلا https://www.isna.ir/service/Economy. به نظر میتوانیم از همین روش استفاده کنیم یعنی لینک گروههای خبری را در متغیر start_urls بریزیم و از آنجا شروع به خواندن خبرها کرده، لینک اخبار هر گروه و زیر گروه را استخراج کنیم. اما تعداد اخبار این گروهها محدود است و مجبور به زدن دکمه ![]() هستیم. با زدن این دکمه که در انتهای لیست اخبار است، به صفحه دیگری که امکان فیلتر کردن اخبار را دارد، هدایت میشویم :
هستیم. با زدن این دکمه که در انتهای لیست اخبار است، به صفحه دیگری که امکان فیلتر کردن اخبار را دارد، هدایت میشویم :
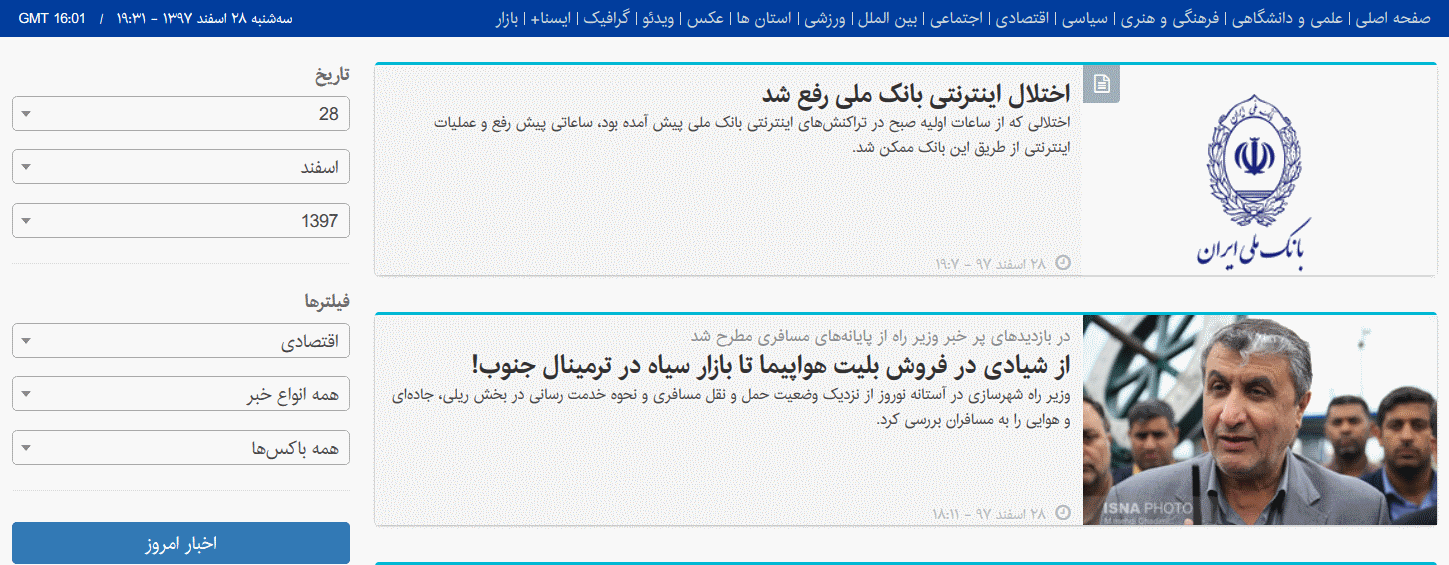
فیلتر سرویسهای خبری را روی همه سرویسها تنظیم میکنیم و متوجه میشویم لینک بالای صفحه عوض میشود. روز چهارم اسفند را انتخاب میکنیم و لینک بالای صفحه به صورت زیر در میآید :
متغیر yrنمایانگر سال و متغیر mnتعیین کننده ماه و dyهم برای تعیین روز است. در پایین صفحه لیست اخبار روز چهارم اسفند، وقتی دکمه رفتن به صفحه ۲ نتایج را می زنیم می بینیم که pi برابر ۲ می شود که نشانگر این است که این متغیر شماره صفحه حاوی نتایج فیلتر را نشان میدهد. متغیر ms را هم که دستی مقدار یک و دو و … میدهیم نحوه نمایش اخبار عوض میشود که برای کار ما اهمیتی ندارد.
بنابراین میتوانیم از این لینک برای تولید بازهای که در آن نیاز به استخراج و پردازش اطلاعات داریم، استفاده کنیم و تنظیمات را به گونهای انجام دهیم که خزنده وب، لینک اخبار را برای پردازش نهایی از این آدرسها برای ما تولید کند. کافیست در چند حلقه تو در تو سال و ماه و روز را برای خزنده تولید کنیم و بقیه کار را خود خزنده برای ما انجام خواهد داد. شماره صفحات را هم خود خزنده از انتهای صفحه میتواند بردارد و نیاز به تولید مجدد آن نخواهیم داشت.
تعیین قوانین استخراج
حال میتوانیم قوانین استخراج خود را مشخص کنیم. یک قانون برای استخراج اخبار و یک قانون برای خواندن صفحات آرشیو اخبار. در این قسمت از کلاس LinkExtractor و Rule استفاده میکنیم و برای هر قانون، یک Rule به لیست rules اضافه خواهیم کرد. به ازای هر قانون هم مشخص میکنیم، در صورت استخراج یک لینک مطابق با آن قانون، چه تابعی صدا زده شود (پارامتر callback) و آیا درون آن صفحه هم باید لینکها بررسی شوند یا نه ( پارامتر follow). مجموعه قوانین ما به صورت زیر خواهد بود:
در خط اول قانون استخراج لینک هر خبر را ذکر کرده ایم و گفتهایم دنبال لینکهایی بگردد که با /news شروع شود، یک یا چند عدد \d+بعد از آن آمده باشد، و در ادامه هم هر کاراکتری غیر از /به هر تعداد ظاهر شود [^/] و سر آخر به انتهای رشته برسد $ . برای پردازش هر خبر که با این قانون مطابق باشد تابع parse_news فراخوانی شود و نیاز به بررسی لینکهای داخل صفحه و استخراج آنها هم نیست follow=False
برای اینکه تا اینجا را تست کنیم و ببینیم لینک اخبار به درستی استخراج میشوند، متغیر start_urls را برابر یک روز خاص در صفحه آرشیو اخبار می گذاریم و در تابع parse_news که جایگزین تابع parse شده است یک پیغام تولید میکنیم تا با اجرای خزنده، بتوانیم بررسی کنیم که این تابع صدا زده میشود یا نه . قبل از اجرای خزنده هم برای اینکه فقط پیام خودمان را ببینیم و سایر پیامهای اسکرپی نمایش داده نشود این خط را به فایل settings.py اضافه میکنیم :
فایل نهایی Isna.pyما تاکنون به این شکل در آمده است :
در خط فرمان دستور scrapy crawl Isna را وارد میکنیم و باید خروجیهایی مشابه زیر مشاهده کنیم که حاکی از درست بودن روال کار تا اینجای کار است:
با زدن Ctrl+C خزنده را متوقف میکنیم . حال کد فوق را طوری بازنویسی می کنیم که لینک تمام اخبار یک بازه زمانی مشخص مثلاً ماه اسفند را برای ما استخراج کند. فقط کافی است این خطوط را قبل از تعیین قوانین به کد فوق اضافه کنیم تا متغیر start_urls حاوی لینک صفحه اول اخبار هر روز در آن بازه مشخص باشد :
حال اگر خزنده را در خط فرمان اجرا کنید، مجدداً باید شاهد استخراج لینکها و پرینت خروجی تابع parse_news باشید. با زدن Ctrl+C خزنده را متوقف کنید. حال آماده ذخیره اطلاعات هر خبر هستیم.
کد تولید لینک آرشیو اخبار، مطابق با اصول برنامه نویسی شیگرا نیست چون درون بدنه کلاس به صورت مستقیم مجاز به نوشتن کد نیستیم و باید از توابع برای این منظور استفاده کنیم. ما این کار را به دلیل ساده شدن فرآیند توضیح کار نوشتهایم و کاربران حرفهای بهتر است این کار را درون یک تابع بنویسند و آنرا در سازنده کلاس فراخوانی کنند.
تعریف ساختار داده ها
برای این آموزش، از هر خبر ، به متن ، تاریخ ، گروه و عنوان خیر بسنده میکنیم. فایل items.py را که در پوشه اصلی پروژه قرار گرفته است باز می کنیم و به کلاس IsnaCrawlerItem که فرزند کلاس scrapy.Item این چهار فیلد را اضافه می کنیم (نام این کلاس ممکن است متفاوت باشد اما میتوانید نام دلخواه خود را به آن بدهید فقط داخل کدهای خزنده حواستان باشد که این نام را import کنید) . حاصل کار شبیه به زیر خواهد بود
کار ما در این بخش تمام است .
انتخاب عناصر مورد نیاز یک خبر به کمک XPath
اسکرپی برای انتخاب و استخراج اطلاعات مورد نیاز یک صفحه، در حالت استاندارد، از گرامر XPath که در XML استفاده می شود بهره می برد. اگر با برچسب های HTML آشنا هستید، گرامر ساده آنرا به سرعت درک خواهید کرد و اگر احیاناً در این زمینه هم تازه کار هستید، توصیه می کنم که مروری بر این زبان ساده ای که دنیای وب را تسخیر کرده است ، بیندازید.
یکی از صفحاتی که قصد استخراج اطلاعات آنرا دارید، باز کنید (یعنی روی یک خبر کلیک کنید) و با کلیک راست روی آن و انتخاب گزینه Inspect Element ، پنجره انتخاب و مشاهده عناصر HTML را باز کنید . حال به ازای هر بخشی که اطلاعات آنرا نیاز دارید باید یک آدرس منحصر بفرد پیدا کنید. مثلاً در سایت ایسنا :
- تیتر خبر : در یک
h1قرار گرفته است که کلاس آنfirst-titleاست. بنابراین آدرس XPath آن عبارتست ازh1[@class="first-title"]که البته تابعtextبرای انتخاب متن قرار گرفته در آن عنصر استفاده شده است . لازم به ذکر است در آدرس دهیXPathرابطه فرزند و پدری با//نمایش داده می شود و فرزند بدون واسطه با/. یعنی عنصری که//نمایش داده می شود ممکن است مستقیما فرزند یک عنصر نباشد بلکه نوه یا نسل چندم آن در سلسله مراتب ساختار صفحه باشد اما/به معنای فرزند مستقیم و بلافاصله یک عنصر است . - متن خبر : متن خبر درون یک
divبا کلاسitem-textقرار گرفته است که هر پاراگراف خبر خود درون یک برچسبpاست. برای اینکه مجبور به پردازش تک تک پاراگراف ها و استخراج متن آنها نشویم از آدرس//textاستفاده می کنیم که متن تمام فرزندان آنرا برگرداند اما این تابع تمام آنها را درون یک لیست بر می گرداند که برای ایجاد یک متن پشت سر هم و بدون خطوط خالی ، آنها را با دستور strip از فضاهای خالی ابتدا و انتهای رشته ها، پالایش کرده و با دستور join همه رشته ها را به هم می چسبانیم . نمونه کد نهایی را ادامه خواهید دید. - گروه خبر : گروه هر خبر در بالای متن خبر و جلوی عبارت دستهبندی درون یک
spanبا کلاسtext-metaقرار گرفته است اما با کمی دقت متوجه میشویم سایر مشخصات خبر که در همان ردیف قرار گرفتهاند هم همین کلاس را دارند. بنابراین باید دنبال یک خصوصیت منحصر بفرد برای آن باشیم (البته میتوانیم تمام برچسبهای حاویtext-metaرا بیابیم و اندیس مثلاً دوم آنرا استخراج کنیم). اگر بهspanحاوی دستهبندی نگاه دقیقتری بیندازیم متوجه میشویم که خصوصیتی به نامitempropو با مقدارarticleSectionدارد. همین خاصیت را برای انتخاب اینspanاستفاده خواهیم کرد یعنی آدرس XPath آن نهایتاً این عبارتspan[@itemprop="articleSection"]خواهد شد. - تاریخ خبر : تاریخ خبر درون یک
li با کلاسfa fa-calendar-oقرار گرفته است که درون آن روز هفته خود داخل یکspanبا کلاسtitle-metaو تاریخ و ساعت درونspanبعدی با کلاسtext-metaاستو چون تنهاspanای که این کلاس را دارد، همان تاریخ خبر است کار ما ساده میشود و مشابه با موارد فوق یک سلکتور ساده رویspanبا کلاسtext-metaبه این صورت مینویسیم:".//span[@class='text-meta']/textالبته اگر کمی دقت کنیم، تاریخ لاتین خبر به صورت در یک تگ meta ذخیره شده است و از آن هم می توانیم استفاده کنیم. - برچسبهای خبر : برچسبها درون تگ
footerبا کلاسtagsقرار دارند که داخل آن باز یک برچسبulمشاهده میکنیم کهliهای آن، هر یک حاوی یک برچسب هستند. بنابراین می توان از این سلکتور استفاده کرد :footer[@class="tags"]//ul/li
اگر با انتخابگرهای CSS آشنا هستید، می توانید برای انتخاب عناصر از آنها هم استفاده کنید یعنی به جای تابع xpath از تابع css روی انتخابگر صفحه استفاده کنید بنابراین آدرس دهی زیر هم در اسکرپی معتبر است :
response.css(‘span.title a::attr(href’))
برای بررسی مستندات کامل اسکرپی در باب انتخابگرها به این آدرس می توانید مراجعه کنید .
شکل نهایی خزنده وب ما به صورت زیر خواهد بود :
استفاده از خط فرمان اسکرپی
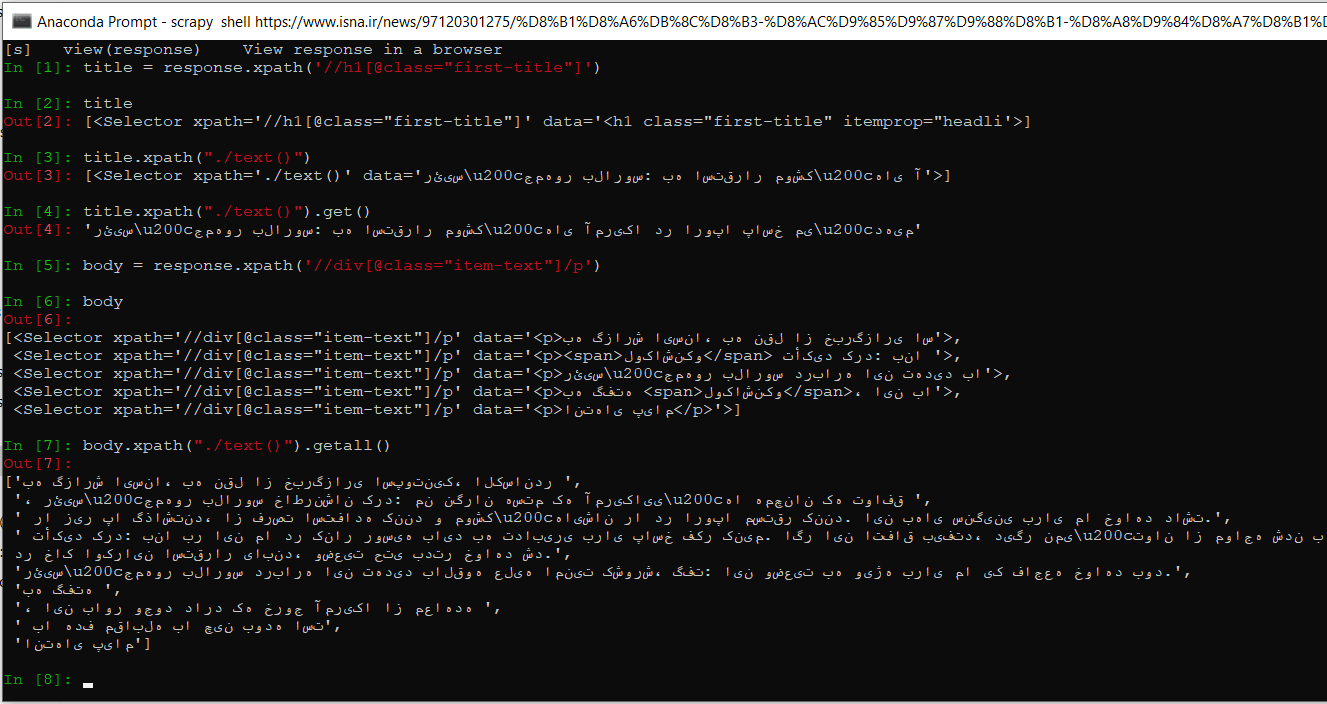
برای استخراج آدرس اطلاعات، راه بهتر و حرفهای تر استفاده از خط فرمان اسکرپی است که با دستور scrapy shell sample-link در خط فرمان، اجرا میشود. به جای sample-link آدرس یکی از صفحاتی که قصد استخراج اطلاعات و یافتن آدرس عناصر حاوی آنها را دارید وارد کنید. با اجرای این دستور، لینک داده شده در محیطی شبیه خط فرمان پایتون توسط اسکرپی پردازش شده و می توانید دستورات response.xpathو یا response.css را درون آن اجرا کنید و بعد از یافتن آدرس درست هر عنصر، آنرا به کد خزنده خود بیفزایید. در زیر نمایی از این خط فرمان نشان داده شده است :
اجرای خزنده و استخراج اطلاعات
برای اجرای این خزنده که نام Isna را به آن داده ایم باید دستور زیر را در خط فرمان وارد کنیم :
برای ذخیره اطلاعات در یک فایل csv می توانیم از دستور scrapy crawl Isna -o news.csv -t csv استفاده کنیم .
(اگر بخواهیم کنترل کاملتری روی این فایل و خروجی خود داشته باشیم ، می توانیم در تابع parse_news و در انتهای عملیات استخراج اطلاعات ، خودمان آنها را در یک یا چند فایل ذخیره کنیم .)
اجرای آنلاین پروژه و کمک به توسعه آن
همانطور که در بالا اشاره شد، میتوانید کل این پروژه را در فضای کاری آنلاین مایکروسافت clone کرده و به صورت آنلاین به اجرای کدها و تغییر در آن بپردازید. برای راحتی کار شما، درون هر زیرپروژه استخراج اطلاعات، یک فایل با نام start_crawler.ipynb هم ایجاد شده است که برای اجرای دستورات خط فرمان و اجرای خزنده وب متناظر با آن پروژه، میتوانید از آن استفاده کنید. اگر پروژه جدیدی را بر مبنای این کدها تولید کردید، ممنون میشوم پروژه اصلی در گیتهاب را fork کرده و کدهای خودتان را به آن اضافه نموده و با یک دستور pull request ساده به ما اطلاع دهید که پروژه اصلی گیتهاب و فضای کاری آژور مایکروسافت را به روز رسانی کنیم .
سخن آخر
سعی کرده ام که مطالب را در ساده ترین حالت ممکن بیان کنم . توصیه می کنم اگر جایی ابهامی دارید یا آنرا درست متوجه نشده اید، از آموزش رسمی خود اسکرپی استفاده کنید و مثالهای مختلف اسکرپی را هم ببنید مثل این مثال که اطلاعات را پس از استخراج در مانگو دی بی ذخیره می کند .
این مقاله مفید را هم از دست ندهید :
https://dzone.com/articles/modern-python-web-scraping-using-multiple-librarie
با سلام و تشکر از سایت فوق العاده خوبتون.
مهندس جان من یه سوأل داشتم ممنون میشم اگه راهنماییم کنین.
میخاستم بدونم میشه بسته ی هضم رو روی یکی از توزیع های پایتون به نام آناکوندا نصب کرد؟؟؟
سلام و عرض ادب
اگر با دستوراتی که توی سایت خود کوندا اومده ، هضم را نصب کنید :
https://anaconda.org/pypi/hazm
نسخه ۰.۳ هضم نصب می شود و طبق توصیه خود سازندگان هضم :
https://github.com/sobhe/hazm/issues/42
بهتر است نسخه ۰.۴ آنرا با دستور زیر نصب کنید :
python -m pip install hazm==0.4 nltk==3.0.0 –upgrade
اگر پایتون مورد استفاده در دستور فوق، پایتون موجود در آناکوندا باشد، هضم به راحتی روی کوندا نصب خواهد شد و قابل استفاده خواهد بود .
خیلی ممنون از راهنماییتون.
من از دستور خود سایت کوندا نصب کردم و بدون خطا وبه طور کامل نصب شد اما موقع فراخونی پیغام خطای زیر رو میده:
AttributeError: ‘module’ object has no attribute ‘POSTagger’
توی اینترنت گشتم ولی علت این خطارو پیدا نکردم. به نظر شما مشکل کجاست؟
ممکنه اشکال از بسته ی nltk باشه؟
ببخشید سوألم ادامه دار شد.
بسیار مفید و عالی…
راستی یادم رفت بگم مهندس جان سیستم من win 32 bit هستش و ورژن پایتونم هم ۲٫۷ و تا حالا تمامی بسته های مورد نیازمو خیلی راحت نصب کردم و ازشون استفاده کردم ولی هرکاری میکنم هضم فراخونی نمیشه!
خیلی گشتم ولی دقیقاً نمیدونم هضم درست نصب نشده که این خطارو میده یا اینکه درست نصب شده و اشکال از جای دیگه است!
AttributeError: ‘module’ object has no attribute ‘POSTagger’
ممنون میشم راهنمایی کنین. چون به شخص دیگه ای تو این زمینه دسترسی ندارم.
با سلام
من خودم این مشکل را داشتم یادمه هم pyWin32 نسخه ۳۲ بیتی را نصب کردم و هم هضم را پاک کردم (چون توی سایت کوندا نسخه ۳ هضم موجوده و توی خود ریپوزیتوری اصلی نسخه ۵ اما نسخه ۴ این مشکل را حل میکنه) و با این دستور نصبش کردم . مشکلم حل شد :
python -m pip install hazm==0.4 nltk==3.0.0 –upgrade
مهندس جان این دستورم اجرا کردم ولی موقع نصب خطا میده!
دیگه نمیدونم والا، هرکاری می کنم نمیشه! من خودم نرم افزار تخصصیم R هستش و دارم روی رمزنگاری کار میکنم ولی متأسفانه R زبان فارسی رو پشتیبانی نمیکنه.
به هر حال بی نهایت سپاس از اینکه وقت با ارزشتون گذاشتین و راهنماییم کردین.
Thank you for having taken your time to provide us with your valuable information relating to your stay with us.we are sincerely concerned.., Most importantly, you Keepit the major.
سلام
با تقریب خوبی میتونم بگم تنها مقالهای هست که درباره اسکرپی به زبان فارسی نوشته شده. واقعا دستتون درد نکنه. فقط یه مورد اینکه اسکرپی در واقع یه فریمورک هست.
سلام تشکر از زحماتتون ، مهندس من این مراحل رو دقیقاً به همین نحو انجام دادم منتهی در پایان فایل csv من خالی هست و اطلاعاتی استخراج نکرده .. ممکنه آدرس های کنونی که در قسمت xpath باید بدیم تغییر کرده باشه؟ چون من ادرس های موجود در آموزش رو زدم
با سلام .
دقیقا همین سایت ذکر شده در مقاله را کار کردین ؟
سلام کد خروجی نمیده راهنمایی میفرمایید.
سلام
چگونه متن اصلی خبر هر سایتی را فقط با وارد کردن آدرس آن سایت بیرون بکشیم با استفاده از فریموورک scrapy؟
توضیحات کامل توی متن داده شده و کافیه آدرس نسبی بدنه هر خبر روی یک سایت به کمک کلیک راست و زدن گزینه inspect element پیدا کنید و توی تنظیمات اسکرپی (در اینجا isna_spider.py) وارد کنید.
Scrapy یک فریمورک هست نه کتابخانه در متن گفته اید کتابخانه این دو با هم متفاوت هستند.
متن اصلاح شد.
سلام! کار ام تحلیل احساسات روی زبان دری است. ولی من خیلی تازه کار استم در این بخش. حالی روی بیش بردازش داده کار می کنم. میشه کمکم کنید درین بخش.
مشکل من اینجاست که نمی دانم ازین normalizer در دیتا سیت خود کار بگیرم در مثال هرگونه ورودی به این نورملایزر میدم. دوباره خود جمله را بریم نشان میده
با سلام اول تشکر میکنم بابت آموزش اما بکسری ایراد هایی به محتوای کار هست مثلا عکس ها کامل نیست نصف کد اصلا در عکس نیفتتاده یا عکس درست آپلود نشده فایل گیت هاب هم ارور ۴۰۴ میده این ها کیفیت کار پایین میاره ولی در کل مطلب عالی بود
ممنون از اینکه ایرادات کار را به ما منتقل کردید. آدرس گیت هاب پروژه اصلاح شد اما در مورد عکسها و کدها مجددا چک شد و مشکلی از سمت ما مشاهده نشد. کدها البته عکس نیست و کافیه اسکرول کنید تا کل کدها قابل مشاهده باشد
خیلی ممنون از پیگیریتون ..در مورد کد ها هم درست میفرمایید
سلام و ممنون از سایت خوبتان
من با scrapy خزنده نوشتم در خزیدن در سایت های انگلیسی زبان مشکلی ندارم
ولی در سایتهای فارسی زبان فونت فارسی را نمی تواند بخواند
ممنون می شوم اگر راهنمایی فرمایید
سلام. دو تا مثالی که الان توی مخزن کد ذکر شده در متن مقاله است (این آدرس) هر دو تا برای سایتهای فارسی نوشته شده و تا الان مشکلی توی خوندن اونها برای بنده پیش نیومده.
پروژه فوق را کلون بفرمایید و به صورت آنلاین تست کنید ببینید مشکل برطرف میشه یا نه. اگر منظورتون نمایش متون فارسی در کنسول هست که نگران نباشید، با ذخیره آنها در یک فایل با فرمت utf8 مشکل حل میشه و به راحتی داده ها خونده خواهند شد (نمونه کدهای آن در این آدرس آمده است. )
سلام با تشکر از مطالب عالی سایتتون
ایا میشه تعداد بازدید کننده ها رو با وب اسکرپینگ (Web Scraping) با پایتون و کتابخانه Beautiful Soup انجام داد (البته برای هر سایتی نه برای سایت خودمان )
ممنون از نظر لطفتون. اگر تعداد بازدیدکنندگان توی صفحه مطلب نمایش داده شده باشه (که توی اکثر موارد این طوری هست) به راحتی با BS می تونید تگ اچ تی ام ال حاوی تعداد بازدید را بخونید و داده مورد نیازتون را استخراج کنید.
ممنون به خاطر پاسختون
ولی منظور من اطلاعات کلی درباره بازدید کنندگان مانند چیزی که در افزونه گوگل انالیز سایت ها میده میخواستم استخراج کنم
آمار بازدیدکنندگان سایت و مطالبی از این قبیل جزء آمار خصوصی هر سایت هست و امکان دسترسی آن برای عموم، جز از طریق سایتهایی مثل الکسا که آماری بسیار کلی و عمومی درباره هر سایت دارند، امکان پذیر نیست.
سلام
چرا نمیشه با beautifulsoup گوگل رو پردازش کرد
ممنون
اگر منظورتون صفحات جستجوی گوگل هست، کافی است لینک بالای صفحه بعد از جستجو را به BS بدهید و تک تک لینک های آنرا، به دلخواه پردازش کنید
scrapy crawl Isnaسلام این خط کد که میزنم پیغام میده :
Unknown command: crawlلطفا راهنماییم کنید.ممنون
کافیه در خط فرمان وارد پوشه پروژه بشید و این دستور را اجرا کنید. این دستور جزء دستورات مخصوص هر پروژه است و حتما باید درون پوشه پروژه ای که ساخته اید اجرا شود.