
نگاهی مقایسه ای به پروژه های پردازش جریان آپاچی
در حوزه پردازش داده، دو نوع اصلی پردازش داریم : پردازش بلادرنگ (Real Time) یا همان پردازش جریان (Stream Processing) و پردازش انبوه (Batch Processing) که فناوریهای اصلی حوزه کلان داده ، مانند روش توزیع و تجمیع (MapReduce)، و جدیدا اسپارک برای پردازش انبوه داده ها طراحی شده اند و برای پردازش بلادرنگ داده ها هم برای سالها، استفاده از صفهای توزیع شده و پروژه های محدودی مانند Storm راه حل اصلی مهندسین داده بود.
در سالهای اخیر ، فناوریهای پردازش بلادرنگ و داده های جریانی مانند داده های دریافتی از حسگرها و تصاویر ترافیک و ماهواره، داده های شبکه های اجتماعی و مانند آن که یکسره در حال تولید هستند و جریان آنها به صورت پیوسته درحال تزریق به برنامه های پردازشی است، پیشرفت زیادی کرده اند و فقط در اکوسیستم آپاچی (مجموعه پروژه های بنیاد آپاچی) امروزه بیش از ده پروژه مختلف متن باز مختلف در این حوزه داریم بعضی از آنها، تفاوت بسیار کمی با یکدیگر دارند که این امر، انتخاب درست ابزار و کتابخانه های مورد نیاز برای پردازش جریان را امری زمان بر و تخصصی نموده است.
با هدف سهولت تصمیم گیری مهندسین داده، وبلاگ DataBaseLine در اقدامی تحسین برانگیز، این فناوریها را در یک جدول با هم مقایسه کرده است که آنرا در زیر می توانید مشاهده کنید .
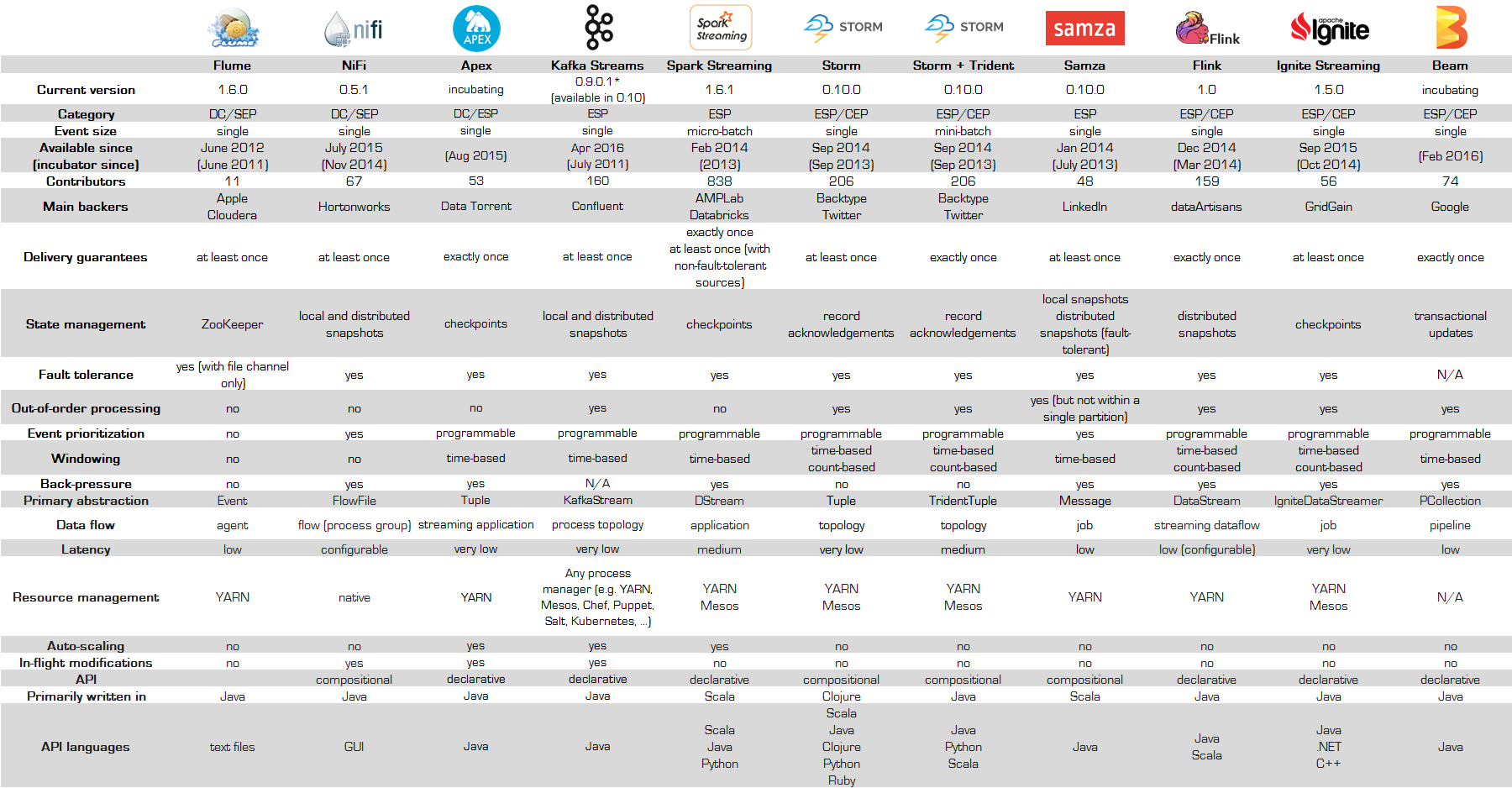
برای مشاهده دقیق تر عکس بر روی آن کلیک کنید .
اگر بخواهیم سیستم های پردازش جریان را گروه بندی کنیم، می توانیم طبقه بندی زیر برای آنها در نظر بگیریم :
- جمع آوری داده مانند NiFi و Flume که به آنها اختصاراً DC می گوییم .
- پردازش تک رخداد (SEP)
- پردازش جریان رخدادی (ESP)
- سامانه های حرفه ای پردازش رخداد (CEP – Coplex Event Processing)
البته، سامانه های حرفه ای پردازش داده که علاوه بر پردازش رخداد، پردازش انبوه را هم در بر میگیرندو یک راه حل جامع برای پردازش انواع داده ها پیشنهاد می کنند مانند Apache Spark,Apache Ignite,Apache Apex هم می توانند به لیست فوق اضافه شوند.
Kafka Streams هم هر چند هنوز قانونی عرضه نشده است اما چون تا اردیبهشت ۹۵ وارد بازار خواهد شد در جدول فوق ، آمده است .
برخی ستون ها یا مواردی که در جدول بالا آمده است از قرار زیر است :
- Back Pressure : منظور میزان فشار و باریست که برای پردازش جریان ، بر سیستم وارد می شود و مجموعه میزان مصرف رم و سی پی یو و … را تشکیل می دهد.
- Auto-Scaling : یا مقیاس پذیری افقی ناظر به گسترش افقی سامانه است یعنی بسته به نیاز ما، با افزودن یک سیستم به سامانه ، به طور خودکار و بدون دردسر ، مجموعه گره های پردازشی یک عدد اضافه شود و پردازش، این سیستم را هم سریعاً در بر گیرد.
- In Flight Modification : قابلیت تغییر داده ها قبل از شروع پردازش بدون نیاز به ارسال مجدد آنها یا توقف سیستم . Spooker از طلایه داران این قابلیت است .
- Event Size: منظور این است که هر رخداد جداگانه بررسی می شود (Single)یا هر چند تا رخداد با هم دیگر یک دسته را تشکیل می دهند و بعد برای پردازش آماده می شوند (MicroBatch)
- Delivery Gurantees که نحوه تضمین پردازش هر رخداد را بیان می کند که بسته به نیاز و نوع کاربرد، باید حتما این پارامتر مد نظر باشد. مثلا برای پردازش سنسورهای غیر حیاتی ، حداکثر یک بار هم کفایت می کند اما برای داده های حساس ، حداقل یک بار باید هر رخداد، بررسی و پردازش شود .
برای اطلاعات بیشتر می توانید به منابع زیر ، رجوع کنید .
- Cake Solution’s two–part comparison of streaming technologies.
- MapR’s overview of streaming technologies.
- Google’s comparison of DataFlow and Spark Streaming, which I have summarized on Read That For Me.
- Taylor Goetz’s Storm vs Spark Streaming slides.
- A discussion on StackOverflow about Flink vs Storm.
- Databricks’ post on improved fault tolerance in Spark Streaming thanks to WALs.
- data Artisans’ article on Flink’s design.
- MapR’s in-depth article on Flink.
- An article by MapR on Apex.
- Hortonworks’ information on NiFi’s fault tolerance in site-to-site data flows as well as a follow-up piece.
- Confluent’s documentation of Kafka Streams.
- Guozhang Wang’s presentation on Kafka Streams.