
اين مطلب يكي از مقالات بخش ويژه نشريه ماهنامه شبكه در شماره ۱۳۳ با عنوان جنبش NoSQL ميباشد. (البته در حال حاضر به دلیل مشکل فنی از دسترس خارج شده است)
پیدایش
مدت زمانی نه چندان دور، برنامهنویسی رویهاي (Procedural) بسیار رونق گرفته بود و زبانهاي برنامهنویسی C و پاسکال، دانشگاهها و محافل علمی را به شدت تحت سیطره خود داشتند. با این حال، این محبوبیت دیری نپایید و با ارائه راهحلهاي بهتر با افول مواجه شد. مشکل اصلی اين بود که در آن زمان، مسائل جذاب مختلفی وجود داشت که دستور زبان C و Pascal راهحلهای مناسبی برای برطرفكردن آنها نداشتند و تلاش برای پیادهسازی آنها، بسیار مشکل و طاقتفرسا بود. در این برهه از زمان بود که برنامه نویسی شیءگرا پا به عرصه وجود گذاشت و همه به این نتیجه رسیدند که پاسکال و C به نقطه انتهایی خدمت خود نزدیک ميشود. پس از مدتی، با وجود اینکه این دو زبان تغییراتی را برای تطبیق با دنیای جدید تجربهکردند، اما بالاخره دوره آنها به پايان رسيد و دنیا به استفاده از مدلهاي پیشرفتهتر برنامهنویسی روی آورد.
این داستان هم اکنون، در حوزه سیستمهاي مدیریتدادهاي تجاری و وب در حالوقوع است. مدلهاي رابطهای، برای بیش از بيستسال بر سیستمهاي مدیریت دادهاي در سازمانهاي بزرگ حکمرانیکردهاند، به طوری که برای نسلهاي مختلفی از توسعهدهندگان، تصور مدل دادهاي بدون سطر و ستونامری غیرممکن به نظر میرسد. با این حال، این مدل سنتی و کارایی پایین آن دردادههاي عظیم تجاری و برنامههاي بزرگ تحت وب، بسیار مورد هجمه واقع شده و بسیاری را به فکر ارائه راهحلهاي جایگزین انداخته است. بسیاری معتقدند، با اینکه مدل قدیمی ارسال و دریافت سطر و ستونها خود را با نیازهای امروز تطبیق ميدهد، اما این کار همانند تلاش برای جای دادن یک مکعب مستطیل در یک شكاف استوانهاي است! به بیان دیگر، با اینکه در عصر اینترنت و کلان داده، یک پایگاهداده قوی و غنی سنتیميتواند کاربردیباشد، اما مدلی که برای حسابداریهاي ساده در دهه ۱۹۵۰ طراحی شده، نمیتواند به خوبی پاسخگوی نیازهای امروزی باشد. به همین دلیل و برای جواب دادن به نیازهای امروزی، پایگاههاي دادهاي جدیدی پا به عرصه وجود گذاشتهاند که با عنوان Not Only SQL یا NoSQL شناخته ميشوند. کارلو استروزی (Carlo Strozzi) نخستينبار در سال ۱۹۹۸عبارت NoSQL را برای اشاره به پایگاههاي دادهاي سبک و اپنسورس رابطهاي به كار گرفت که از رابط SQL استفاده نمیکردند. هرچند بعدها وی به این نکته اشاره کرد که این عبارت و مفهوم پشت آن، کاملاً از مدل رابطهاي جدا شده و دیگر بهتر است آن را NoREL یا Not Only Relational بنامیم.
در سال ۲۰۰۰ ميلادي، اریک بریور (Eric Brewer) با ارائه نظریه CAP به کمبودها و محدودیتهاي مدل رابطهاي در سیستمهاي بخش بخش شده (Partitioned) اشارهکرد و توضیح داد که ثبات (Consistency) و دسترس پذیری بالا (High Availability)، هر دو در یک پایگاه دادهای موجود در یک شبکه گسترده و وسیع قابل فراهم شدن نیستند.
این نظریه، باعث شد تا توجهها به سمت دادههاي گسترده در سطح شبکه جلب شده و مدلهايي با تأکید بر بخش بخشسازی (Partitioning) و دسترس پذیری بالا (High Availability) بهعنوان نیازمندی اصلی و با در نظرگرفتن ثبات بهعنوان اولویت بعدی، که امکان به تأخیر انداختن آن در مقایسه با سایر اولویتها نیز وجود دارد، معرفی شوند. به همین دلیل، عبارت NoSQL مفهومی است که برای مشخص کردن پایگاههاي دادهاي بهکار ميرود که به شدت با پایگاههاي دادهاي رابطهاي سنتی متفاوت هستند. این پایگاههاي دادهاي اغلب با مفاهیم سنتی نظیر جدولها، سطر و ستونهاي ثابت بیگانه هستند و در بيشتر موارد، عملیات Join در آنها بیمعنی بوده و بهصورت افقی مقیاسپذیرهستند.
محققان دانشگاهی این پایگاههاي دادهاي را با عنوان ذخیرهسازی ساخت یافته یا Structured Storage ميشناسند که مفهومیکلی بوده و دربرگیرنده پایگاههاي دادهاي رابطهاي نیز هست. در سال ۲۰۰۹، یکی از کارمندان Rackspace این عبارت را «باز-معرفی» کرد و از آن برای اشاره به مجموعهاي از پایگاههاي دادهاي غیررابطهاي و گسترده در شبکه استفاده کرد که در نقطه مقابل پایگاههاي دادهاي رابطهاي قدیمی مانند IBM DB2, MySQL, Microsoft SQL Server, PostgreSQL, Oracle RDBMS, Informix, Oracle Rdb و… قرار ميگرفتند. پس از بروز نیازهای جدید و معرفی تئوریهاي مورد نیاز برای پیادهسازی چنین پایگاههاي دادهاي نوظهوری، محصولات مختلفی در این زمینه پا به عرصه وجود نهادند که هر یک از جهاتی مهم بوده و قابلیتهاي بسیار سودمندی به همراه دارند. درباره این محصولات در قسمتهاي بعدی بیشتر توضيح خواهیم داد. فعالیتهاي مرتبط با توسعه پایگاههاي دادهاي NoSQL در محافل علمی و عملی به شدت افزایش یافت تا جایی که در سال جاری میلادی، کار روی پروژهاي با نام UnQL (سرنام Unstructured Query Language) آغاز شده که هدف آن، تدوین استاندارد زبان پرسوجو در پایگاههاي دادهاي NoSQL است. این زبان به گونهای طراحی خواهد شد تا بهجای جدولهاي سنتی و سطر و ستونهاي دادهای، به ترتیب مجموعهها (collection)، اسناد (Documents) و فیلدهای مشخصی را مورد پرسو جو قرار دهد. این زبان در اصل مجموعهاي ورای SQL به شمار آمده و زبان SQL را ميتوان نمونه بسیار محدود شده آن به شمار آورد. با این حال، زبان UnQL عبارتهاي DDL یا Data Definition Language (عبارتهايي مانند CREATE TABLE یا CREATE INDEX)را پوشش نخواهد داد.
اهمیت و کاربرد
عبارت NoSQL یک مفهوم برای مشخصسازی یک موج خلاقانه است که در دنیای پایگاههاي دادهاي در حال وقوع است. با مطرح شدن این مفهوم، طوفانی از تبادل نظر، هیجان و بحث و گفتوگو در محافل فنی به راه افتاد که به يقين تا مدتها باقی خواهد ماند. اما چرا NoSQL این همه سروصدا به پا كرده است؟ این مفهوم برای یک توسعهدهنده برنامههاي کاربردی چه معنايی دارد؟ همانطور که قبلاً نیز ذکرشد، زبان SQL و پیادهسازیهاي مختلف SQL RDBMS (Relational Database Management Systems) مانند MySQL، PostgreSQL، Oracle و… دهههاي متمادی برای تمام نیازهای ذخیرهسازی و بازیابی داده کاربران و توسعهدهندگان یک راه حل اساسی بودهاند. اما در سال ۲۰۱۰، نیازمندیهاييمطرح شده و مورد توجه قرارگرفتند که با استفاده از مدل رابطهاي سنتی قابل دستیابی نبودند. از آنجا که مسائل جدید به ابزارهای جدید نیازدارند، مجموعهاي بزرگ از ابزارها پا به عرصه وجود گذاشته و موردتوجه بسیاری قرارگرفتند. دسترسپذیری بالا، مقیاسپذیریافقی، قابلیت تکثیر (Replication)، طراحی بدون Schema و قابلیت Map Reduce از جمله زمینههايي هستند که توسط مجموعهاي جدید از پایگاههاي داده و تحت عنوان کلی NoSQL در حال توسعه و آزمایش هستند.
برای درک بيشتر اهمیت NoSQL بايد به چالشهاي موجود امروزی بر سر راه پایگاههاي داده بيشتر توجه کرد. هماکنون با توسعه فناوريهاي مختلف و قابلیت نمونهبرداری و تولید حجم عظیمی از دادهها، امکان ذخیرهسازی و تحلیل آنها چالشی بزرگ به شمار ميآيد.
کارایی بسیار بالا در ذخیرهسازی و ارائه دادههاي باینری مانند اسناد PDF و فایلهاي MP3، در مقیاس وسیع، یکی از بهترین کاربردهایی است که پایگاههاي دادهاي NoSQL شایستگی خود را در فراهمکردن آن به اثبات رساندهاند. یک نمونه مناسب در این زمینه، خدمات Amazon S3 است. با این اوصاف، موارد ذکر شده تنها چالش پیش روی توسعهدهندگان و سرویسدهندگان نیست. ذخیرهسازی، مدیریت و بازیابی دادههاي گذرا که در بعضی موارد در مقیاس بالایی در برنامههاي کاربردی امروزی تولید ميشوند نیز یکی دیگر از چالشهاي امروزی است که راه حل مدیریت مناسب آنها را پایگاههاي دادهاي NoSQL ارائهکردهاند. این پایگاههاي داده، در مدیریت دادههايي نظیر متغیرهای یک Session در وب، قفلهاي دادهاي و آمار کوتاه مدت، جایگاه بسیارخوبي کسب کردهاند. نمونه مناسبی برای این کاربرد، پایگاه دادهاي Memcached است. اما نکتهاي که باید در این میان به آن توجه کرد آن است که یک توسعهدهنده، باید برای کاری که ميخواهد انجام دهد، ابزار مناسب را انتخابکند. به این معنا که برای بسیاری از کاربردهای معمولی، هنوز پایگاههاي دادهاي سنتی بهترین راه حل هستند و نباید آنها را تمام شده تصور كرد. همانطور که قبلاً نیز گفته شد، پایگاههاي دادهاي NoSQL برای مواردی خاصمناسب هستند که در بالا به آنها اشاره شد و موجب افزایش کاراییکل مجموعه نرمافزاری ميشوند. در بسیاری از موارد، انتخاب یک پایگاه داده NoSQL برای کاربردی خاص موجب افت شدید عملکرد و عدم پایداری مجموعه و قابلیت اطمینان بسیار پایین ميشود. به همین دلیل و به علت تعدد ابزارهای توسعهداده شده در این زمینه، گاهی اوقات تشخیص محدودیتها و مصالحههايي که باید در استفاده از یک ابزار درنظر گرفت، بسیار مشکل شده و انتخاب راه حل مناسب در محیطهاي رابطهاي یا غیر رابطهاي یک یا چند سروری، سردرگم کننده خواهد بود. به همین منظور، یک دیاگرام مناسب برای انتخاب راه حل مناسب توسط ناتان هورست (Nathan Hurst ) براساس نظریه CAP طراحی شده که در شكل ۱ آن را مشاهده ميكنيد.
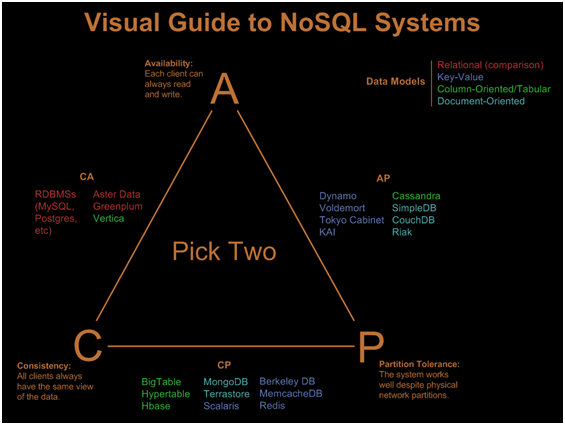
شکل ۱- دیاگرام انتخاب پایگاههاي داده بر اساس نیازمندیها
در این دیاگرام سه گوشه اصلی نشانگر ثبات (Consistency)، در دسترس بودن (Availability) و قابلیت بخش بخش سازی (Partition Tolerance) هستند. ثبات در اینجا يعني همه کلاینتها همواره به دادههاي مشابه دسترسی داشته باشند، در دسترس بودن يعني همه کلاینتها امکان خواندن و نوشتن را داشته باشند و قابلیت بخش بخش سازی نیز به معنای این است که سیستم کلی بتواند در تمام بخشهاي شبکه فیزیکی کارکند. بر اساس نظریه CAP، تنها دو عنصر از این سه عنصر در سیستمهاي واقعی قابل انتخاب هستند و بر همین اساس، برای داشتن هر جفت مشخصه، ميتوان راهحلی را که روي ضلع مشترک آنها آورده شده است، انتخاب كرد. بررسی کامل این دیاگرام خود محتاج توضیح و تبیین بسیاری است که در حوصله این مقاله نمیگنجد. راهکارهای NoSQL، برای مسائلی بسیار فراتر از دنیای سنتی پایگاههاي دادهاي بهکارميروند و عملکردی به شدت بهتر از همتایان سنتی خود ارائهميكنند. لازم به تأکید است که گذار به سمت راهکارهای NoSQL، به دلیل مشکلات و محدودیتهاي زبان SQL نبوده است، بلکه بهدليل محدودیتهاي مدل رابطهاي پایگاه دادهاي است. زمینههايي که این پایگاههاي دادهاي مناسب آنها هستند و از خود شایستگی بیشتری در آنها نشان ميدهند، به ترتیب در ادامه آورده شدهاند:
دادههاي با توالی نوشتن بالا و توالی خواندن کم:
همانند شمارندههای بازدید صفحات وب، دستگاههاي وقایعنگار یا تلسکوپهاي فضایی. در این حالت، ذخیره دادهها یا بهصورت جفتهاي دادهاي key-value (همانند آنچه در Redis اتفاق ميافتد) انجام ميگیرد یا به صورت Document Oriented (همانند مدل مورد استفاده MongoDB) صورت ميپذیرد.
دادههاي با توالی خواندن بالا و توالی نوشتن بسیارکم:
همانند دادههايگذرا و کش شدهاي از تصاویر، اسناد و HTML رندر شده با دسترسی تکراری. چنین دادههايي در پایگاهداده Memcached که برای ذخیره موقت دادههاي گذرا مورد استفاده قرار ميگیرد، به خوبی مورد پردازش قرار ميگیرند. پایگاههاي دادهاي Cassandra و HBase نیز در زمینه جستوجوي دادههاي عظیم شایستگیهاي بسیاری دارند و راهحلهاي پیشرفتهاي نظیر Hadoop و Hive نمونههايي مناسب برای استفاده در زمینه تحلیل دادهها به شمار ميروند.
کاربردهايی با نیازمندیهاي در دسترس بودن بالا (High Availability) و با توقف خدمات (Downtime) بسیارکم:
این موارد به شدت در مدل سنتی با کمبودهایی مواجه هستند و پایگاههاي دادهاي NoSQL از عهده اجرای آنها بهخوبی برميآیند. چنین سیستمهايي که از طریق مجموعههاي خوشهسازی شده و با پیکربندی Redundant پیاده سازی ميشوند، بیش از هر چیز به مقیاس پذیری افقی و امکان توسعه روی ماشینهاي مختلف شبکه نیاز دارند. با مدلهای ارائه شده جدید توسط پایگاههاي دادهاي مانند Riak و Cassandra انطباق بیشتری داشته و کارایی بالاتری ارائه ميكنند.
دادههايي که باید در نقاط مختلف جغرافیایی با هم همگامسازی شوند:
چنین دادههايي که در کلاسترهای مختلف یک شبکه بزرگسازمانی با دفاتر مختلف پراکنده در سطح جغرافیایی وسیع موجودند و نیاز است تا همواره و با بالاترین سرعت و کمترین هزینه ممکن با هم همگام سازی شوند، به خوبی در مجموعههاي سنتی رابطهاي قابل پیادهسازی نیستند و در صورت انجام این کار، هزینههاي بسیاری را در برخواهند داشت. در نقطه مقابل، پایگاه دادهاي Memcached به خوبی از عهده اجرای چنین عملیاتی با کمترین هزینه و بالاترین کارایی برميآید.
دادههاي بزرگ تجاری یا مرتبط با تحلیل وب که شما ( schema)ی خاصی ندارند:
چنین دادههايي تقریباً شکل و قالب از پیش تعیین شدهاي ندارند و براساس محتوای متغیر موجود روي وب تولید ميشوند و در بيشتر موارد به فعالیتکاربران و سیستمهاي نرمافزاری مرتبط وابستههستند. اغلب نیاز است تا چنین دادههايي به خوبی ذخیرهسازی شوند (ترجیحاً بهصورت موازی) و امکانات پرسوجوپذیری غنی در اختیار بگذارند تا به خوبی قابل تحلیل باشند. مشخص است که سیستمهاي سنتی دادهاي که برای ذخیرهسازی و بازیابی نیاز به داشتن یک شمای از پیش تعیین شده و ثابت دارند به خوبی از عهده چنینعملیاتی برنمیآیند و به استفاده از راهکارهای جدید در این زمینه نياز است. راه حل هادوپ یکی از بهترین گزینهها برای کارکرد بهعنوان مدیر چنین دادههايي است.
راهحلهاي NoSQL در بسیاری از شرکتهايي که خدمات «وب اجتماعی» ارائه ميكنند، به کار گرفته شده و به سرعت در حال گسترش است. این امر به دلیل سختی زیاد و محدودیتهاي سیستمهاي کاملاً رابطهاي در برآوردهکردن نیازهای دادهاي آنها است. با نگاهی به نیازمندیهاي مقیاس پذیری یکی از شبکههای اجتماعی به راحتی ميتوانیم به این امر واقف شویم. این نیازمندیها عبارتند از:
– ۵۷۰ میلیون مشاهده صفحات در ماه
– آپلود بیش از سه میلیارد عکس در ماه
– پردازش و ارائه بیش از ۱,۲میلیون عکس در ثانیه
– ارائه ۲۵ میلیون نوع محتوا که با استفاده از ۳۰ هزار سرور انجام ميپذیرد.
با این نیازمندیها، که به يقين با نیازمندیهاي یک دپارتمان حسابداری در دهه ۱۹۵۰ تفاوتهاي بسیاری دارد، این شبکه اجتماعی خود را با مجموعهاي غنی از ابزارها تطبیقداده است که هر کدام یکی از بهترین نمونههاي پیشرو در حوزه پایگاههاي دادهاي NoSQL محسوب ميشوند:
Memcached:
این شبکه اجتماعی با استفاده از هزاران سرور Memcached، دهها ترابایت داده کششده گذرا را در هر لحظه پردازشكرده و خدمات مرتبط را به کاربران خود ارائه ميكند.
Cassandra که هم اکنون با HBase جایگزینشده است:
با استفاده از این پایگاههاي دادهاي این شبکه اجتماعی عملیات ذخیرهسازی گسترده طیف وسیعی از دادهها بدون داشتن هیچ نقطه خطا دار یا مشکل داری در مجموعه عظیمی از ماشینهاي محاسباتی را به بهترین نحو به اجرا در ميآورد.
Hadoop و Hive:
با استفاده از این ابزارهای پیشرفته، این شبکه اجتماعی تحلیل دادههاي عظیم و تحلیلهاي بازاری و تبلیغاتی را با کارایی بالایی به انجام ميرساند.
با توجه به موارد ذکر شده در بالا، ميتوان معماری دادهاي جدید و کارا را کلید رشد و توسعه سریع این شبکه اجتماعی دانست که بهعنوان دلیل اصلی مقیاس پذیری خوب آن نیز به شمار آورد. عاملي که زمینه رشد و توسعه شرکتهاي بزرگ دیگری مانند یاهو، Foursquare و Twitter را نیز به ارمغان آورده است. با اینکه اینگونه شرکتها در زمینه استفاده از این فناوري پیشگام هستند، اما هسته اصلی فناوری NoSQL به کار گرفته شده در بسیاری از کاربردهای موجود بهصورت کلی در دسترس همگان قرار دارد که در بیشتر موارد بهصورت اپن سورس نیز توسعه داده شدهاند. به همین دلیل، طیف وسیعی از توسعه دهندگان در برنامههايکاربردی و تجاری خود در حال آزمایش و تطبیق با این فناوري نوپا هستند و به زودی شاهد موج عظیمی از بهکارگیری چنین فناوریهايي در گوشه و کنار دنیای نرم افزارها خواهیم بود.
همزیستی مسالمت آمیز
یکی از سؤالهايي که ممکن است توسعهدهندگان با آن مواجه شوند آن است که کدام یک از پایگاههای داده موجود را انتخاب کنیم تا بهترین کاربرد را در اختیار داشته باشیم؟ جواب سؤال این است که واقعاً لازم نیست تنها یک پایگاه داده را برای ذخیرهسازی انتخاب کنیم. با استفاده از مفهوم Polyglot Persistence، یک برنامه کاربردی ميتواند برای انجام امور مختلف از پایگاههاي داده مختلف استفاده كند. عبارت Polyglot به معنای دانستن زبانهاي مختلف بوده و Persistence نیز به معنای ادامه حیات است. با این اوصاف، مفهوم Polyglot Persistence يعني ادامه حیات با استفاده از شناختن زبانهاي مختلف (در اصل و در اینجا، پایگاههاي داده مختلف) است. به بیانی سادهتر، مفهوم Polyglot Persistence، همانند Polyglot Programming، انتخاب بهترین گزینه برای ادامه حیات موضوعی است که روي آن کار ميکنیم. با استفاده از این مفهوم، یک برنامه کاربردی ميتواند به استفاده از پایگاههاي دادهاي سنتی رابطهاي ادامه دهد و برای بهبود عملکرد خود، از پایگاههاي دادهاي NoSQL نیزبهرهببرد. بهعنوان مثال، یک برنامه کاربردی ميتواند از پیکربندی پایگاههاي دادهاي زیر برای انجام امور مختلف استفاده کند:
MySQL برای ذخیرهسازی دادههای با ارزش و کمحجمی چون پروفایلکاربران یا اطلاعات صورت حساب آنها
MongoDB برای ذخیرهسازی دادههاي باارزش و حجیم مانند شمارندههاي صفحات و وقایع نگاریها (log)
Amazon S3 برای ذخیرهسازی دادههاي آپلود شده توسط کاربران مانند تصاویر و اسناد
Memcached برای ذخیرهسازی شمارندههاي موقت و صفحات HTML رندر شده
شكل ۲ نمایی از یک برنامه کاربردی با این پیکربندی را نمایش میدهد. مفهوم Polyglot Persistence علاوهبر فراهمکردن راهی مناسب برای توسعه برنامههای کاربردیجدید این امکان را فراهم ميسازد تا توسعهدهندگان بتوانند برنامههاي کاربردی کنونی خود را براساس آن تغییرداده و از مزایای هر دو نوع پایگاه داده استفاده كنند. به همین دلیل، توسعهدهندگان ميتوانند در برنامههاي کاربردی کنونی خود، اطلاعات کم ارزش و موقت اما حجیم و کند کننده خود مانند اطلاعات Session و آمارها را به پایگاههاي دادهاي مانند Redis یا Tokyo Tyrant محول کنند. بنابراين، همه توسعهدهندگان برای تولید برنامههاي جدید باید در کنار استفاده از مدل سنتی رابطهای، به طور جدی به استفاده از امکانات پایگاههاي دادهای NoSQL در راه حلهای خود فکر کنند.
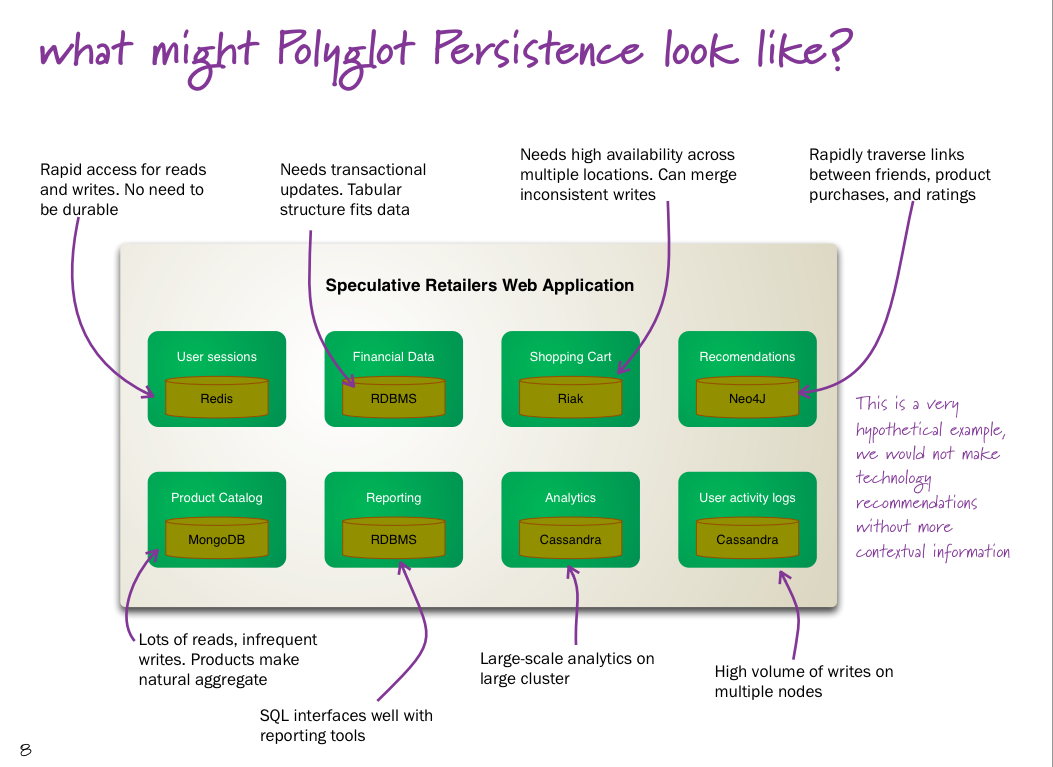
شکل ۲- یک برنامه کاربردی که با استفاده از مفهوم Polyglot Persistence از مجموعههاي متنوعی از پایگاههاي داده استفاده ميکند.
No SQL و رایانش ابری
همانطور که قبلاً نیز گفته شد، پایگاههاي دادهاي کنونی در دهههاي قبل طراحی شدهاند و حاصل طراحی در زمانی هستند که فناوريهاي ذخیرهسازی ارزان و حافظه و سیپییو گران بودند. اما ماشینهاي امروزی پارامترهای متفاوتی نسبت به اجداد خود دارند. امروزه، هزینه در اختیارگیری حافظه رم و سی پی یو ارزان است و به راحتی و با مقیاس پذیری خوبی ميتوان با استفاده از سرویسهايي مانند Amazon EC2 توان پردازشی و حافظه را بر مبنای نیاز افزایش داد. با این حال، به دلیل اینکه چنین خدماتی اغلب ازطریق مجازی سازی ارائه ميشوند و گلوگاه سرعت عملکرد سیستمهاي مجازیسازی شده، خدمات I/O است، بنابراين محدودیت بسیاری در زمینه استفاده از فضای ذخیرهسازی در سیستمهاي امروزی وجود دارد. به عبارت دیگر، در مقایسه با دهه گذشته، محدودیت هزینهاي بین حافظه رم و حافظه دیسک جابهجا شده است و بر این اساس، خیلی هم عجیب نیست که پایگاههاي دادهاي قدیمی نتوانند به خوبی از عهده وظایف محوله در پردازش ابری بر آیند. در نقطه مقابل پایگاههاي دادهاي NoSQL، در اصل برای کار در حافظه رم طراحی شدهاند. پایگاههاي Redis و Memcached فقط از حافظه رم برای ذخیرهسازی استفاده ميکنند. Cassandra نیز به صورت پیش فرض و با استفاده از Memtable ها، از رم بهعنوان محل اصلی ذخیرهسازی و نوشتن داده استفاده ميكنند. در این پایگاه داده، در یک فرآیند غیر همزمان، دادههاي حافظه روي دیسک نوشتهميشوند تا از ایجاد گلوگاههاي عملکردی بهخاطر سرعت نوشتن جلوگیری به عملآید. همچنين، به این دلیل که پایگاههاي دادهاي NoSQL با تاکید روي مقیاس پذیری افقی براساس بخش بخشسازی (Partitioning) توسعهیافتهاند، عملکرد بسیار خوبی را در فراهمسازی مزیت ابرهای پردازشی، یعنی قابلیت الاستیک بودنکلاود فراهم ميسازند. در واقع پایگاههاي دادهاي NoSQL یک تطبیق ذاتی با پردازش ابری دارند.
آینده: پایگاه داده به عنوان سرویس
بسیاری از ما، «زیر ساخت بهعنوان سرویس» را که خدمات Amazon EC2 و Rackspace نمونههاي خوبی از آن هستند، بهعنوان مصداق کامل کلاود ميشناسیم. یکی از تأثیرات این ابرهای بسیار بزرگ عمومی، آن است که تأخیر بین برنامههاي کاربردی به شدت کاهش یافته و از بالای پنجاه میلی ثانیه در فضای اینترنت به يك میلی ثانیه در فضای کلاود رسیده است. این اختلاف تأخیر، فرصتهاي بسیار مناسبی را برای خدمات دهندگان ۳rd Party فراهم کرده است تا به ارائه خدمات مبتنی بر پایگاه داده بپردازند. پایگاه داده بهعنوان سرویس، یکی از مدلهاي تجاری بسیار مهم دههآینده خواهدبود. هم اکنون نیز خدماتی نظیر MongoHQ (بر اساس MongoDB)، Cloudant (براساس CouchDB) و Amazon RDS (بر اساس MySQL)، پایگاههاي دادهاي میزبانی شده و مدیریت شده کاملی را برای برنامههاي موجود در EC2 ارائه ميکنند که شاید بتوان آنها را گامهاي اولیه برای DaaS (Database As a Service) دانست. این خدمات، همانند IaaS
(سرنام Infrastructure As a Service) ميتواند به شدت در کاهش هزینههاي پیادهسازی و نگهداری تأثیرگذار باشد و کارایی مناسبی در مقیاسپذیری و اختصاصی سازی ارائه كند. با اینکه چنین خدماتی بسیار جوان و نوپا هستند، اما امکان برون سپاری درگیریها و مشکلات اجرایی و مقیاس دهی پایگاه دادهای برنامهها برای توسعهدهندگان بسیار سودمند و قابل توجه است و به همین دلیل، این خدمات به شدت رشد خواهند كرد. علاوه بر موارد ذکر شده، خدمات DaaS با استفاده از مفهوم Polyglot Persistence تأثیر شگرفی بر دنیای ذخیرهسازی دادهها خواهد گذاشت زيرا توسعهدهندگان ميتوانند راهبری پایگاههاي دادهاي مختلف خود را به ارائه کننده خدمات واگذارکرده و از مسائل و مشکلات مربوط به آنها رها شوند. همچنين، یکی از دلایلی که پایگاههاي دادهاي یک نوع وابستگی قبیله مانند برای افراد ایجاد ميکنند، زمان و هزینه یادگیری وکسب تخصص در استفاده و راهبری آنها است. توجه داشته باشيد كه افراد بسیاری، در پایگاههاي دادهاي MySQL و عدهاي دیگر در PostgreSQL و بعضی ديگر نیز در اوراكل تبحر و تخصص دارند. اما به ندرت کسی پیدا ميشود که از عهده مدیریت هر سه پایگاه داده برآید. پایگاه داده بهعنوان خدمات این مانع را حذفکرده و فرصتهاي جدیدی را جهت استفاده در بخش تولید برای توسعه دهندگان فراهم خواهد كرد.
نتیجه
همانند برنامه نویسی رویهاي که جای خود را به راههاي بهتری برای حل مسائل مختلف داد، انتظار ميرود که غنی بودن و انعطاف راهحلهاي مبتنی بر NoSQL نقش فزایندهاي را در راهکارهای تجاری مدیریت دادهها در حال و آینده بازیکنند. با این فناوری، بسیاری از کاربردهای پیشرفته تجاری ذخیرهسازی دادهها، مانند تحلیلهاي پیش بینانه، به صورت گسترده در دسترس قرارخواهندگرفت و این تنها، ارمغان ذخیرهسازی پیشرفته دادهها است. در حالی که راهکارهاي مبتنی بر NoSQL تکامل ميیابند، مسائلی که ما توانایی حل آنها را خواهیم داشت نیز غنیتر شده و اهمیت تجاری بیشتری پیدا ميکنند. در حال حاضر، حدود یک دو جین ابزار مهم در زمینه NoSQL در حال توسعه بوده و به شدت مورد توجه صنایع هستند. در حالی که این فناوری در حال رسیدن به فراگیری و بلوغ است، ميتوان مطمئن بود که راهکارهای NoSQL بهعنوان جهتی جدید در راه حلهاي تجاری و فناوریهاي پایگاه داده مطرح شده و به رشدی سریع خواهند رسید.
۰
میانگین امتیاز
شما هم امتیاز بدهید!