
استفاده تیم نقشه اسنپ از Vector و Clickhouse در نسخه جدید بخش تحلیل دادههای قبل از سفر
گزارشی از مقاله "جمع آوری و تحلیل داده های قبل از سفر در تیم نقشه اسنپ"
مقدمه:
اخیرا مقالهای توسط فرزین نصیری در وبلاگ ایشان منتشر شد که در این مقاله به بررسی چالش های جمع آوری و تحلیل داده های قبل از سفر (pre-ride) در تیم نقشه اسنپ می پردازد. حجم زیاد داده ها، پیچیدگی ذاتی آنها و نیاز به حفظ امنیت، از جمله چالش های این فرآیند هستند. در این نوشتار و بعد از توضیح معماری جدید این واحد، بر نقش دو ابزار قدرتمند، Vector و Clickhouse در سیستم جدید جمع آوری و تحلیل داده ها تمرکز شده است.
ضمن تشکر از جناب نصیری بابت به اشتراک گذاشتن این مقاله ارزشمند، در این نوشتار مسایل مطرح شده را از زاویه دید مهندسی داده با هم بررسی میکنیم.
سیستم قبلی:
سیستم قبلی که برای این منظور استفاده می شد، SSP نام داشت و با زبان جاوا نوشته شده بود. این سیستم از Apache Flink برای پردازش داده ها، Logstash برای جابجایی لاگ ها و Elastic Search برای ذخیره سازی داده ها استفاده می کرد. کافکا هم در بخشی از مسیر جابجایی داده، فرآیند انتقال را تسهیل میکرد.
لاگاستش امروزه بسیار کمتر استفاده میشود و خود الستیکسرچ ابزارهای جدیدتری را برای انتقال دادهها پیشنهاد میدهد (Beat ها). از طرفی آپاچی فلینک هم برای پردازش بلادرنگ تکرخدادها مورد استفاده میشود و یکی از فناوریهای به بلوغ رسیده بنیاد آپاچی در حوزه پردازش داده است اما زمانی سراغ آن می رویم که واقعا نیازمند پردازش لحظهای تکرخدادها (مثلا درخواست سفر یک مسافر) با انجام مجموعهای از عملیات پردازشی سنگین و پشت سر هستیم. استفاده از آپاچی فلینک هم نیاز به آموزش تیم فنی دارد و هم نگهداری آن، سربار مضاعفی برای نگهداری خط پردازش داده محسوب می شود که تیم نقشه اسنپ در نسخه جدید، آنرا با برنامههایی که به صورت داخلی با GO توسعه دادهاند جایگزین کردند.
مشکلات سیستم قبلی:
- سربار و پیچیدگی بالا: به دلیل استفاده از چندین ابزار مختلف، سیستم قبلی بسیار پیچیده بود و نگهداری و توسعه آن دشوار بود.
- مصرف زیاد منابع: سیستم قبلی به دلیل عدم کارایی، منابع زیادی را مصرف می کرد.
- عدم مقیاس پذیری مناسب: سیستم قبلی به سختی می توانست با افزایش حجم داده ها مقیاس بندی شود.
راه حل جدید:
سیستم جدید از ابزارهای زیر برای دریافت اطلاعات قبل از سفر و ذخیره و پردازش آنها استفاده می کند:
- Vector: برای انتقال داده ها به صورت کارآمد و مقیاس پذیر
- Go: برای توسعه سرویس های پردازش داده
- Clickhouse: برای ذخیره سازی داده ها به صورت سریع و مقیاس پذیر
مزایای استفاده از Vector:
- سرعت بالا: Vector می تواند داده ها را با سرعت بسیار بالایی جابجا کند.
- مقیاس پذیری: Vector به راحتی می تواند با افزایش حجم داده ها مقیاس بندی شود.
- سادگی: Vector ابزاری ساده و آسان برای استفاده است.
- قابلیت اطمینان: Vector ابزاری قابل اعتماد و پایدار است.
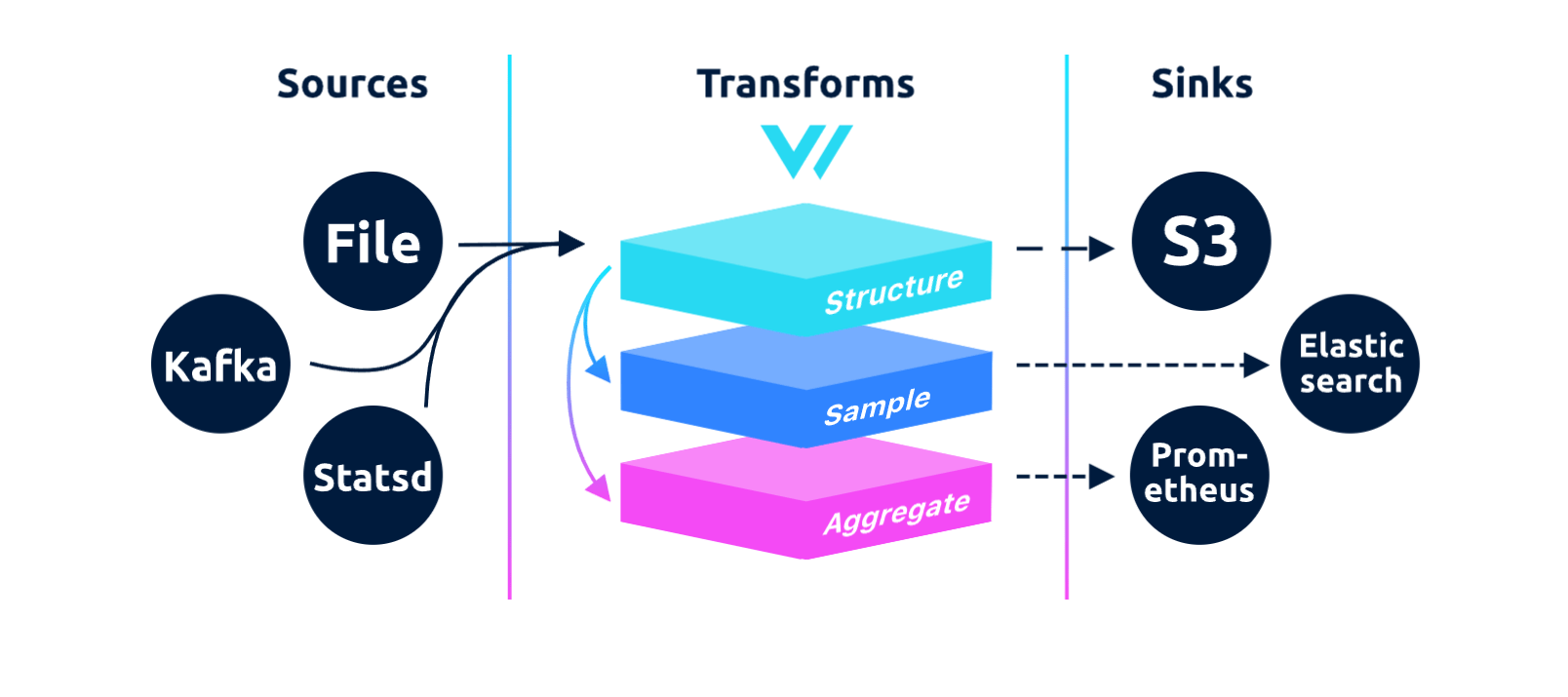
مزایای استفاده از Clickhouse:
- سرعت بالا: Clickhouse می تواند کوئری های پیچیده را با سرعت بسیار بالایی اجرا کند.
- مقیاس پذیری: Clickhouse به راحتی می تواند با افزایش حجم داده ها مقیاس بندی شود.
- فشرده سازی داده ها: Clickhouse می تواند داده ها را به طور فشرده ذخیره کند تا فضای ذخیره سازی کمتری اشغال شود.
- قابلیت اطمینان: Clickhouse ابزاری قابل اعتماد و پایدار است.
مهاجرت:
مهاجرت به سیستم جدید به صورت گام به گام انجام شد و در حال حاضر این سیستم به طور کامل در تیم نقشه اسنپ مورد استفاده قرار می گیرد.
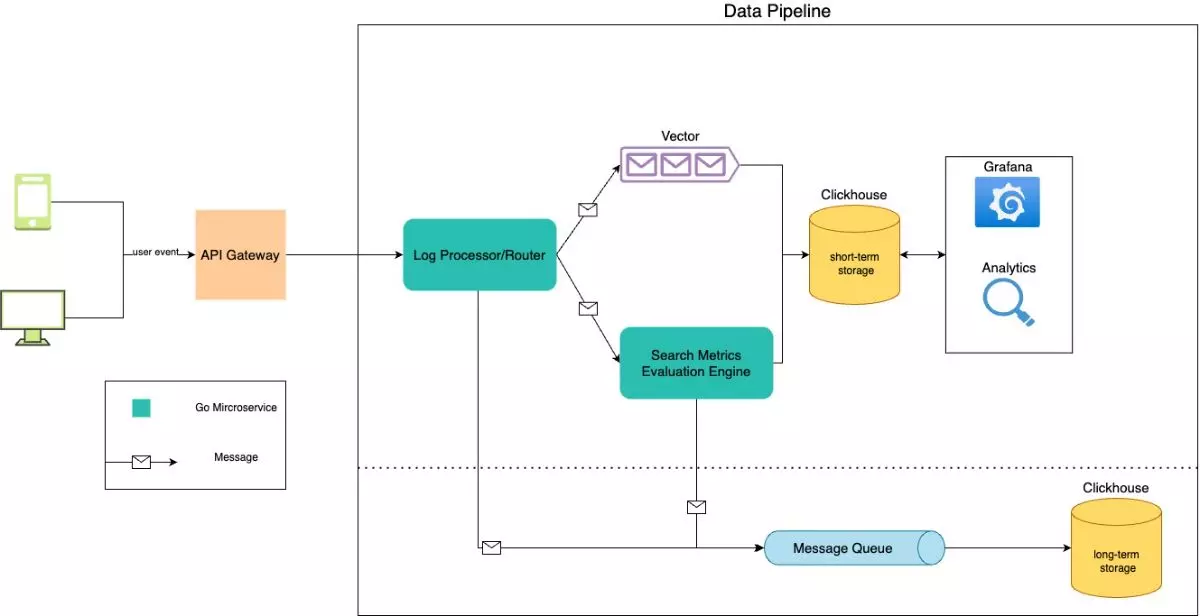
نتیجه:
استفاده از Vector و Clickhouse در سیستم جدید جمع آوری و تحلیل داده های قبل از سفر، مزایای قابل توجهی را به ارمغان آورده است، از جمله:
- کاهش چشمگیر سربار و پیچیدگی
- کاهش مصرف منابع
- افزایش مقیاس پذیری
- افزایش سرعت پردازش داده ها
- افزایش قابلیت اطمینان
نکات برجسته:
- استفاده از دو ابزار مدرن و قدرتمند Vector و Clickhouse
- ایجاد یک خط پردازش داده داخلی بدون استفاده از ابزارهای رایج
- تمرکز بر مقیاس پذیری، سرعت و reliability
- مهاجرت گام به گام به سیستم جدید
این مقاله می تواند به عنوان یک الگو برای تیم های دیگر که به دنبال جمع آوری و تحلیل داده های حجیم هستند، مورد استفاده قرار گیرد.
جمع بندی:
این مقاله به طور جامع و دقیق به بررسی چالش ها و راه حل های جمع آوری و تحلیل داده های قبل از سفر در اسنپ می پردازد. تمرکز این مقاله بر نقش دو ابزار Vector و Clickhouseو زبان GO در سیستم جدید است. توضیحات ارائه شده در این مقاله می تواند برای مهندسان داده و سایر افراد فعال در این حوزه مفید باشد.