
بررسی معیارهای سنجش دستهبندی – بخش اول
مقدمه
در ادامه مباحث آموزشی علم داده به زبان ساده و قبل از پرداختن به الگوریتم های مختلفی که در این حوزه به آنها نیاز خواهیم داشت، بهتر است با معیارهای ارزیابی این الگوریتمها (یا چنانچه قبلاً اشاره کردیم : مدلها) آشنا شویم. در اغلب موارد ما به دنبال ساخت یک مدل بر اساس داده های موجود برای پیشبینی مقدار یک ویژگی از آنها هستیم (تحلیل پیشگویانه) . چه این ویژگی یک مقدار غیر عددی باشد مانند تعیین مشروط شدن یا نشدن دانشجو، ترک کار شرکت توسط کارمند، تعیین موضوع یک توئیت و مانند آن که به آنها مسائل دستهبندی میگوئیم و یا یک مقدار عددی مانند حدس زدن میزان حقوق یک فرد، قیمت یک خانه و مانند آن که به آنها مسائل درونیابی یا رگرسیون می گوییم.
حتی در مسايل و الگوریتمهای بدون ناظر، مانند خوشه بندی نیز به معیارهایی برای تعیین دقت مدل نیاز خواهیم داشت. بنابراین در چند مقاله آتی، معیارهای اصلی مورد استفاده در ارزیابی الگوریتمها و مدلهای مختلف علم داده را با هم مرور خواهیم کرد تا امکان سنجش این مدلها برای تک تک شما به صورت شفاف و قابل فهم، مهیا شود.
اگر بخواهیم نگاهی کلی به این معیارها داشته باشیم، به جدول زیر خواهیم رسید که اصلی ترین معیارهای ارزیابی را شامل شده است :
با توجه به اینکه مسائل دسته بندی و رگرسیون، حجم بیشتری از نیازهای دنیای واقعی را در بردارند، این دو گروه را جداگانه بررسی خواهیم کرد و در انتها هم به معیارهای سنجش روشهای بدون ناظر و چند معیار ارزیابی متفرقه می پردازیم.
نگاهی دقیقتر به مسائل دستهبندی
در مسائل دستهبندی به دنبال پیشبینی دسته یا گروهی هستیم که یک رکورد یا داده به آن تعلق دارد. مثلا میخواهیم با داشتن مشخصات مختلف یک دانشجو مانند رشته، سهمیه قبولی، وضعیت مالی خانواده، تعداد هم اتاقیها ، وضعیت تحصیلی دوران دبیرستان، تعداد واحدهای گذرانده، معدل ترمهای پیش، تعداد ترمهای مشروطی و مانند آن تعیین کنیم که این دانشجو مشروط خواهد شد یا نه . یا به عبارتی به دسته مشروطیها تعلق دارد یا دسته دانشجویان غیرمشروط.
اینکه احتمال دیابت داشتن یک بیمار با توجه به آزمایشهای انجام شده چقدر است یعنی این بیمار جزء دسته دیابتیها قرار میگیرد یا افراد غیردیابتی، باز هم به یک مدل یا الگوریتم دستهبندی نیاز داریم.
همانطور که از دو مثال فوق مشاهده میکنید، دستهبندیهای دوگانه بیشترین کاربرد را در دنیای واقعی دارند و ما هم برای ساده کردن مطلب، تمرکز را بر این نوع دستهبندی خواهیم گذاشت اما تمامی موارد بیان شده، به راحتی قابل تعمیم به دستهبندی های چندگانه هم خواهند بود.
بعد از ساخت یک مدل دستهبندی یعنی یافتن الگوریتمی که با مشاهده یک داده جدید، دسته یا گروه (Class) آنرا مشخص کند (عمل Classification)، برای سنجش میزان کارآیی و دقت مدل پیشنهادی، آنرا بر روی دادههای آموزشی یعنی دادههایی که از قبل دستهبندی آنها را میدانیم، اعمال میکنیم.
خروجی این مدل را با خروجی واقعی به صورت زیر مقایسه خواهیم کرد :
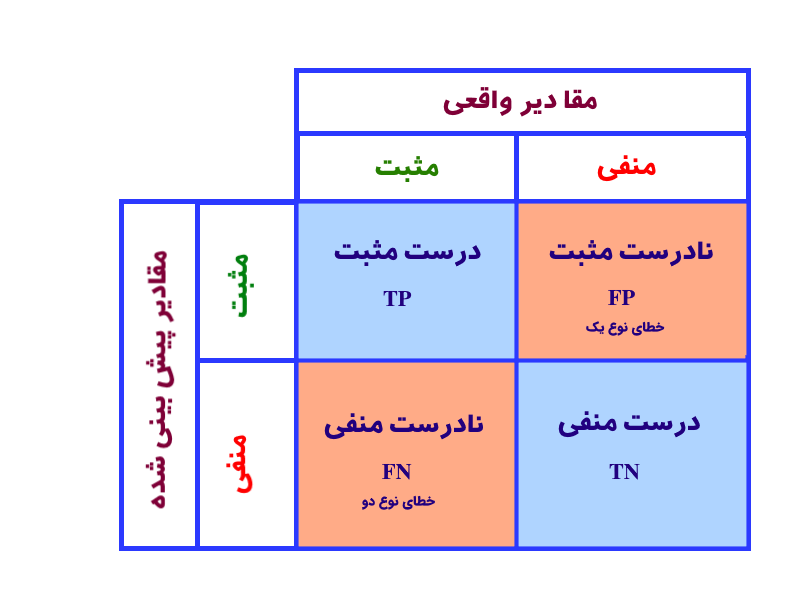
به این جدول مهم که اساس تحلیل و ارزیابی کارآیی یک مدل در مباحث دستهبندی است، ماتریس درهمریختگی یا اغتشاش گفته میشود. اما با توجه به نامفهوم بودن این ترجمه، از عبارت ماتریس پراکنش که پراکندگی توزیع دسته ها را از لحاظ درستی یا نادرستی نمایش میدهد، در ادامه این سلسله آموزش ها برای اشاره به این ماتریس استفاده خواهد شد.
تعداد سطرها و ستونهای این ماتریس به تعداد دستهها وابسته است. جدول فوق یک ماتریس دو در دو را برای یک مساله دسته بندی دوگانی مثلا دیابت داشتن یا نداشتن، مشروط شدن یا نشدن، ترک کار یا عدم ترک کار نشان می دهد. در حالت کلی برای یک مساله دستهبندی n حالته، یک ماتریس پراکنش n*n باید رسم شود.
در حالت کلی به دنبال این هستیم که بخشهای قرمز رنگ این ماتریس یعنی پیشبینی های نادرست ، به حداقل برسد.
با فرض اینکه هدف ما پیشبینی دیابت یک بیمار باشد یعنی اگر پیشبینی مثبت باشد یعنی بیمار، مبتلا به دیابت است و اگر پیش بینی منفی باشد، یعنی بیمار به دیابت مبتلا نیست، به تحلیل سلولهای این ماتریس میپردازیم :
- درست مثبت (True Positive-TP) : اگر بیمار واقعا دیابت داشته باشد و مقدار پیشبینی شده هم دیابت را نشان دهد.
- نادرست مثبت (FP) : اگر بیمار دیابت نداشته باشد اما نتیجه پیش بینی ما، نشانگر دیابت بیمار باشد.
- نادرست منفی (FN) : اگر بیمار دیابت داشته باشد اما پیش بینی ما، دیابت را منفی نشان دهد.
- درست منفی (TN) : اگر بیمار دیابت نداشته باشد و پیش بینی ما هم همین را نشان بدهد.
همانطور که مشخص است ایده آل ما این است که موارد نادرست (نادرست مثبت و نادرست منفی) صفر باشند اما در عمل این اتفاق نمیافتد و نیازمند مکانیزمها و معیارهایی برای بررسی دقت و صحت و کارآیی مدل ایجاد شده از داده ها هستیم.
در شکل زیر، مفاهیم فوق را به صورت بصری می توانیم مشاهده کنیم :

در شکل فوق، ناحیه سمت چپ دادههایی است که برچسب واقعی آنها مثبت است مثلا تمام کسانی که دارای بیماری دیابت هستند و ناحیه سمت راست دادههایی است که برچسب واقعی آنها منفی است مثلاً تمام کسانی که بیماری دیابت ندارند و هدف اصلی ما از طراحی یک مدل، این است که این دو ناحیه به درستی از هم تفکیک شوند.
اما در عمل، داده هایی را که به عنوان بیماران دیابتی شناسایی می کنیم (دایره وسط شکل) دارای دو ایراد اصلی است : هم حاوی داده های نادرست است و هم تمام داده های درست را شناسایی نکرده است. ناحیه های سبزرنگ، بخش هایی است که مدل ما به درستی عمل کرده است و نقاط شناسایی شده آبی رنگ، داده هایی را نشان می دهد که به درستی برچسب گذاری شده اند. از طرفی، داده های نارنجی رنگ، داده هایی هستند که به اشتباه برچسب گذاری شده اند یعنی افرادی که دیابت نداشته اند و مدل ما هم آنها را دارای دیابت تشخیص داده است (FP) و یا دیابت داشته اند و دسته بند ما هم آنها را سالم فرض کرده است (FN).
انتظار ما این است که نقاط درست تشخیص داده شده (T) در مقایسه با داده هایی که به اشتباه تشخیص داده شده اند (N)، بسیار بیشتر باشد. بنابراین نیاز به معیارهایی داریم که بتوانیم کارآیی و دقت مدل های دسته بندی خود را با آنها بسنجیم. در ادامه این معیارها (metrics) یا سنجهها را به تفصیل بررسی خواهیم کرد.
دقت – صحت – بازخوانی
اولین معیار یا سنجهای که به ذهن مان میرسد، معیار دقت یا میزان تشخیص درست مدل است. یعنی نسبت تشخیص های درست (TP+TN) به کل داده ها :

با هم این معیار را برای یک مثال دستهبندی با مشخصات زیر بررسی میکنیم :
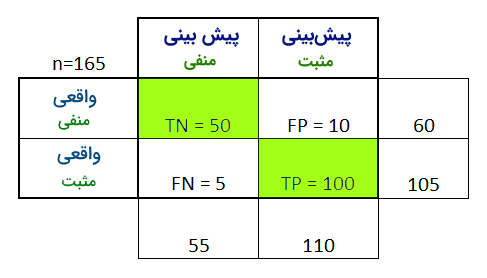
همانطور که مشاهده می کنید در مثال فوق که یک جمعیت ۱۶۵ تایی از دادهها را شامل میشود، تعداد دادههای درست تشخیص داده شده یعنی آنهایی که در واقعیت و در پیش بینی، یک مقدار داشته اند (ناحیه سبزرنگ)، به نسبت سایر داده ها، بسیار بزرگتر است بنابراین انتظار می رود دقت این مدل ما بالا باشد. آنرا محاسبه می کنیم :
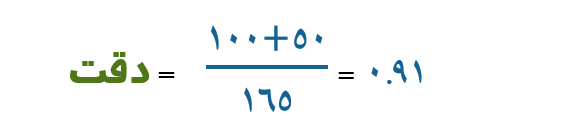
که دقت بسیار خوبی است. برای بسیاری از مسائل دستهبندی دنیای واقعی این معیار، بسیار کارآمد است چون هم دادههای در نظر نگرفته شده را لحاظ کرده است (مخرج کسر) و هم دادههای شناسایی شده را (صورت کسر). هدف ما هم رسیدن این عدد به مقدار یک یا همان صد در صد است. اما اگر با ادبیات یادگیری ماشین آشنا باشید این معیار چندان برایتان آشنا نخواهد بود و امروزه کمتر مورد استفاده قرار میگیرد. چه نقصی در این معیار باعث عدم رواج آن شده است ؟
این معیار، برای داده های نامتعادل یعنی داده هایی که تعداد برچسب های مثبت و منفی آن در دنیای واقعی از لحاظ عددی اختلاف بسیار زیادی دارند، معیار مناسبی نیست. بسیاری از مسائل دنیای واقعی هم دقیقاً جزء این گروه قرار می گیرند. اگر قرار باشد ابتلا به ایدز را از روی آزمایشات مختلف برای هزار نفر تشخیص دهید، شاید یک یا دونفر از این بین، به ایدز مبتلا باشند که اختلاف زیادی بین دسته مثبت (افراد دارای ایدز) و دسته منفی (افراد سالم) حاکم است. مسایلی مانند تشخیص هرزنامه بودن یک ایمیل، تروریست بودن یک مسافر هواپیما، شناسایی دانشجویان مشروط ، پیشبینی خروج یک کارمند از شرکت و مانند آن، نمونههای دیگری از مسايل دستهبندی با دستههای نامتعادل در دنیای واقعی هستند. این اختلاف معنی دار بین دستههای مختلف دادهها، باعث عدم کارآیی معیار دقت میشود. به مثال زیر توجه کنید.
فرض کنید هزار نمونه آزمایش خون داریم که تنها دو نفر از آنها به ایدز مبتلا هستند. می خواهیم مدلی (الگوریتم) پیشنهاد کنیم افراد دارای ایدز و افراد سالم را شناسایی کند. این مدل اگر نمونه ای را مثبت اعلام کرد، آن فرد به ایدز مبتلاست. مدل زیر توسط یک نفر برای این مساله پیشنهاد می شود:
الگوریتم (مدل) پیشنهادی = تمام نمونه ها را منفی اعلام کن !
با این مدل ما ۹۹۸ نمونه منفی درست تشخیص داده شده داریم (TN = 998) و نمونه مثبت هم کلا نداریم (TP=0) بنابراین طبق فرمول فوق، دقت الگوریتم پیشنهادی برابر است با :

نتیجه کمی غافلگیرکننده است. مدلی که هیچ کاربرد عملی ندارد و کسی آنرا در دنیای واقعی به کار نخواهد برد، حاوی دقتی بالای ۹۹ درصد و تقریبا نزدیک صددرصد است.
مشکل اصلی هم نامتعادل بودن داده ها و تفاوت معنی دار تعداد نمونه های هر دسته است که باعث میشود یک مدل متمایل به دسته پرتعداد، دقت کلی را بالا نشان دهد. بنابراین نیاز به معیاری دقیق تر برای سنجش دقت و کارآیی الگوریتم های پیشنهادی دسته بندی هستیم.
در این گونه مسایل بهتر است بر تعداد نمونه های مثبت شناسایی شده به کل نمونه های مثبت تمرکز کنیم. یعنی ببینیم از دونفر بیمار مبتلا به ایدز، چند نفر شناسایی شده اند. معیار بازخوانی را برای این منظور به صورت زیر تعریف می کنیم :

توضیح اینکه کل نمونه های واقعاً مثبت شامل نمونه هایی است که درست، مثبت شناسایی شده اند(TP) و نمونه هایی که مثبت بوده اند اما نادرست، منفی شناسایی شده اند (FN).
سنجه بازخوانی برای روش پیشنهادی تشخیص ایدز، صفر است (چون هیچ نمونه مثبتی را شناسایی نکرده ایم – صورت کسر برابر صفر است) که نشانگر ضعیف بودن مدل پیشنهادی است و بنابراین آنرا می توانیم به راحتی رد کنیم.
اما این معیار هم مشکل بزرگ دیگری دارد. اگر مدل زیر را برای مساله تشخیص ایدز پیشنهاد کنیم :
الگوریتم (مدل) پیشنهادی = تمام نمونه ها را مثبت اعلام کن !
در این صورت تمام دو نفر بیمار ایدز را تشخیص داده ایم . یعنی بازخوانی ما برابر حداکثر ممکن یعنی ۱ شده است. توضیح اینکه تعداد داده های درست تشخیص داده شده برابر ۲ و تعداد داده های نادرست منفی اعلام شده (کسانی که ایدز دارند اما نتیجه آزمایش ایدز آنها را منفی اعلام کرده ایم – FN) ، برابر صفر است و تقسیم دو بر دو هم که یک می شود. یعنی گاهی بازخوانی ما به خاطر ضعیف بودن مدل پیشنهادی، بالاست. این ضعیف بودن را با معیار دیگری باید اندازه بگیریم.
برای حل این مشکل، در کنار معیار بازخوانی معیار دیگری را به نام صحت (Precision)، برابر تعداد نمونه های تشخیصی درست مثبت به کل نمونه های مثبت اعلام شده به صورت زیر تعریف می کنیم تا میزان مثبت های اشتباه را هم در نظر گرفته باشیم :
در این فرمول، وجود FP در مخرج باعث می شود که اگر تعداد تشخیص های اشتباه مان بالا باشد، صحت الگوریتم عددی نزدیک به صفر نشان دهد و بنابراین کارآیی مدل، زیر سوال برود.
با این توضیحات، معیارهای بازخوانی و صحت به جای معیار اولیه دقت، کاربرد وسیع تری در دنیای امروز یادگیری ماشین پیدا کرده است.
در اغلب موارد، این دو معیار با هم رشد و حرکت نمی کنند. گاهی ما صحت مدل را با الگوریتم های دقیقتر بالا می بریم، یعنی آنهایی را که مثبت اعلام می کنیم، اکثراً درست هستند و موارد نادرست مثبت ما بسیار کم هستند یعنی صحت الگوریتم ما بسیار بالاست اما ممکن است جنبه یا ویژگی خاصی از داده ها را در نظر نگرفته باشیم و تعداد کل نمونه های مثبت، بسیار بیشتر از نمونه های اعلام شده ما باشد یعنی بازخوانی بسیار پایینی داشته باشیم.
از طرفی ممکن است کمی الگوریتم تشخیصی خود را ساده تر بگیریم تا تعداد مثبت های تشخیصی خود را بالا ببریم، در این صورت میزان اشتباهات ما زیادتر شده، صحت الگوریتم عدد پایین تر و بازخوانی آن، عدد بالاتری را نشان می دهد.
اگر بتوانیم معیاری ترکیبی از این دو معیار برای سنجش الگوریتم های دستهبندی به دست آوریم، تمرکز بر آن معیار به جای بررسی همزمان این دو، مناسبتر خواهد بود مثلا از میانگین این دو به عنوان یک معیار جدید استفاده کنیم و سعی در بالا بردن میانگین حسابی این دو داشته باشیم. اگر بخواهیم میانگین معمولی دو معیار بازخوانی و صحت را ملاک کار درنظر بگیریم، برای حالت هایی که صحت بالا و بازخوانی پایینی داریم (و یا بالعکس)، میانگین معمولی عددی قابل قبول خواهد بود در صورتی که الگوریتم پیشنهادی نباید نمره قبولی بگیرد. برای رفع این نقیصه و تولید یک معیار واحد که متمایل به عدد کوچکتر باشد، از میانگین هارمونیک و با فرمول زیر استفاده می کنیم :
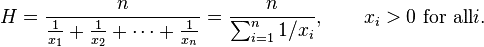
این میانگین هارمونی برای دو مقدار بازخوانی و صحت را با نام F1-Score می شناسیم که طبق فرمول فوق برابر است با :
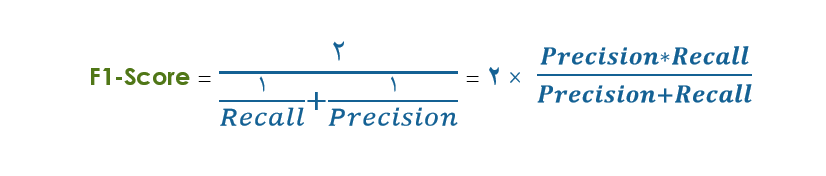
در این فرمول همانطور که مشاهده می کنید اگر یکی از دو مقدار عددی کوچک باشد، یا حتی صفر باشد، نتیجه نهایی عددی کوچک و یا صفر خواهد بود. توضیح این امر هم ساده است چون دو معیار بازخوانی و صحت اعدادی بین صفر تا یک هستند و در صورت کسر در هم دیگر ضرب شده اند بنابراین نتیجه نهایی به سمت عدد کوچکتر، متمایل خواهد بود و اگر هر دو با هم، عددی بزرگ (نزدیک ۱) باشند، نتیجه نهایی به سمت یک حرکت خواهد کرد. (اطلاعات بیشتر راجع به انواع میانگین)
در دنیای واقعی یک حد آستانه پذیرش هم میتوانیم برای F1-Score تعیین کنیم مثلا ۰٫۹ و اعلام کنیم که مدلهایی با نمره بالاتر از این آستانه، مورد تایید نهایی قرار خواهند گرفت.در فرمول میانگین هارمونیک ، وزنی مساوی به هر دو پارامتر داده ایم و بسته به نیاز می توانیم میانگین هارمونیک مرتبه های بالاتر یعنی F2 ، F3 و غیره را هم به کار ببریم (رجوع کنید به این آدرس برای جزییات بیشتر).
بررسی معیارهای سنجش دستهبندی – بخش دوم
در مقاله قبلی به تشریح ماتریس پراکنش ( Confusion Matrix ) و نیز بررسی دو معیار مهم در سنجش کارآیی مدلهای دستهبندی یعنی معیار صحت ( Precision ) و بازخوانی ( Recall ) و نهایتا معیار ترکیبی F1-Score که میانگین هارمونیک این دو معیار است، پرداختیم و بیان شد که هدف اصلی ما در یافتن …
آخرین مطلب درباره این معیارهای اصلی دسته بندی این است که این معیارها کاملاً بستگی به بستر و حوزه دستهبندی دارند. مثلاً در تشخیص ایدز یا تشخیص کلاه برداری در تراکنش های بانکی، ما نیاز به شناسایی تمامی موارد ایدز و کلاهبرداری داریم یعنی نیاز داریم که بازخوانی ما بسیار بالا باشد و اگر خطایی هم تولید شد مثلاً بیماری به اشتباه ایدزی تشخیص داده شد و یا یک تراکنش سالم، متهم به کلاه برداری شد، کافی است با کمی آزمایش بیشتر، نتایج را بهبود خواهیم بخشید و موارد خطا را از لیست تشخیص داده شدهها حذف خواهیم کرد.
اما گاهی اوقات به دنبال صحت بیشتر هستیم مثلاً با خواندن توئیت های روزانه، قرار است آنالیز احساسات روی آنها انجام دهیم. در این حالت، صحت الگوریتم یعنی تشخیص درست و دقیق احساسات هر توئیت خوانده شده و نه همه توئیت ها (با فرض اینکه تعداد توئیتهای بررسی شده زیاد باشد) برای ما اهمیت زیادتری از بررسی تمامی توئیتها دارد. بنابراین همیشه و در همه موارد، ما از F1-Score استفاده نمی کنیم، بلکه با بررسی نیازمندیها، بهترین معیار را برای کار خود انتخاب خواهیم کرد.
در مواردی که دستهها، متعادل هستند، مثلاً تعیین جنسیت ارسال کننده یک توئیت، میتوانیم همان معیار دقت که معیار اول مورد بحث بود را هم به کار ببریم . در هرصورت باید بدانیم که دنبال چه هستیم.
در ادامه آموزش، به سایر معیارهایی که می توانیم از جدول پراکنش استخراج کنیم و نیز نحوه رسم نمودارهای مرتبط با این معیارها، خواهیم پرداخت.
سلام جناب مهندس بنایی عزیز
مطلب مفصل ، با ادبیاتی روان و شیوا،
سپاسگذارم از شما
ارادت داریم جناب هوشمند عزیز
با سلام و خسته نباشید خدمت اساتید محترم
تشکر بخاطر اشتراک مطالب یونیک و تجربیات ارزشمندتان