
سایت معتبر kdnuggets در هجدهمین نظرسنجی سالیانه خود از فعالان حوزه تحلیل و پردازش داده در سرتاسر دنیا، ابزار و کتابخانه های مورد استفاده آنها را مورد سوال قرار داده است . نتایج اولیه این نظر سنجی که حدود ۲۹۰۰ نفر در آن شرکت کرده اند، اخیراً منتشر شده است. نگاهی به این نتایج ، می تواند روند رو به رشد ابزار ، کتابخانه ها و گرایشات این حوزه از دانش را برای علاقه مندان ، مشخص کند و آنها را در انتخاب اولیه ابزار مناسب ، یاری نماید.
خلاصه این نظر سنجی را می توانید در شکل زیر مشاهده کنید :
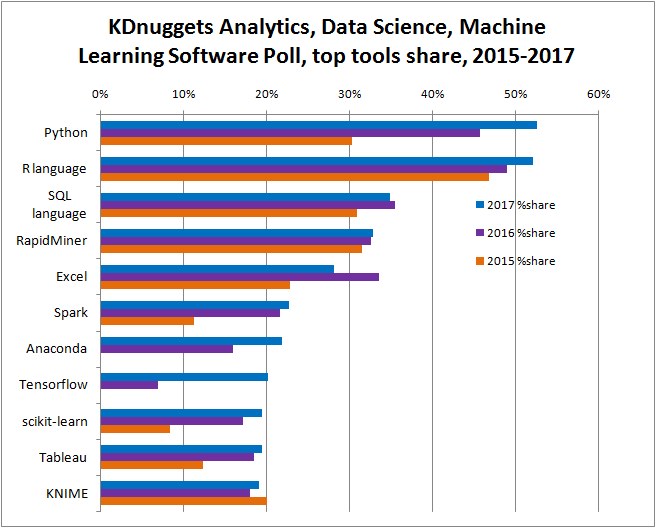
در این گزارش که روند رشد یا کاهش محبوبیت را در سه سال ۲۰۱۵ تا ۲۰۱۷ بررسی کرده است ، نکات زیر قابل مشاهده است :
- برای اولین بار، محبوبیت زبان پایتون از زبان R پیشی گرفته است و پیش بینی می شود رشد محبوبیت پایتون در حوزه علم داده ، به همین منوال ادامه یابد. هر چند محبوبیت R هم در چند سال اخیر ، روندی صعودی داشته است.
- سهم کتابخانه های یادگیری عمیق از ۹ درصد در سال ۲۰۱۵ به ۳۲ درصد در سال ۲۰۱۷ رسیده است که نشان از اقبال جامعه علمی و تخصصی دنیا به این حوزه نوین پردازش داده دارد. کتابخانه TensorFlow هم با محبوبیت حدود ۲۰ درصدی، طلایه دار ابزارهای یادگیری عمیق دنیاست که جزء ده ابزار برتر این نظر سنجی هم قرار گرفته است.
- پنج زبان یا کتابخانه اصلی کار با داده و تحلیل آنها در سال ۲۰۱۷ هم عبارتند از پایتون،R، SQL ، اسپارک و تنسورفلو
- رپیدماینر هم با محبوبیت ۳۳ درصدی، عمومی ترین ابزار داده کاوی و علم داده دنیا شناخته شد.
بررسی آماری نتایج
ابزارهای اصلی علم داده بر اساس درصد محبوبیت زیر مشخص شده اند :
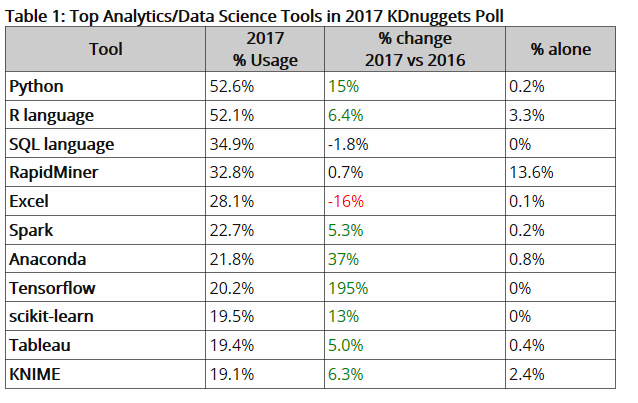
ستون Change در این جدول، میزان رشد استفاده نسبت به سال ۲۰۱۶ را نشان می دهد. دو ابزار Anaconda که یک توزیع محبوب پایتون است و نیز کتابخانه تنسور فلو، برای اولین بار جزء لیست ابزارهای پرطرفدار علم داده قرار گرفته اند.
ابزارهای جدیدی هم که رشد بالای دودرصدی داشته اند هم از قرار زیرند :
Keras (9.5%), PyCharm (9%), Microsoft R Server (4.3%), IBM DSX (3.0%), PyTorch (3.0%), and Teradata (2.4%)
اگر بخواهیم ابزارهایی که بیشترین رشد را نسبت به سال ۲۰۱۶ داشته اند و گرایشات جهانی به استفاده از آنها رو به افزایش است را مشاهده کنیم به لیست زیر می رسیم :
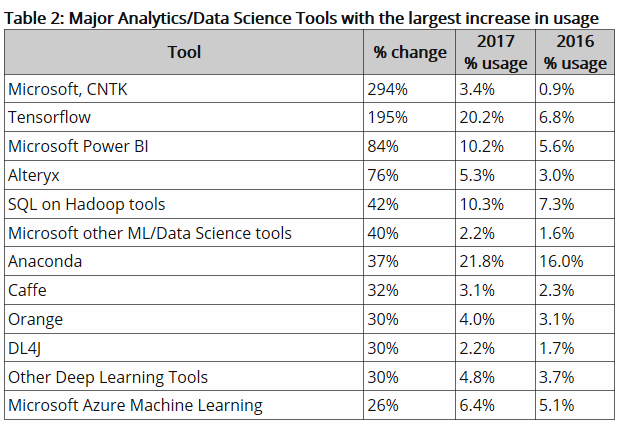
حضور مایکروسافت با چهار ابزار مختلف در این لیست ابزارهای نوین، نشاندهنده جهت گیری خوب این شرکت به سمت ایجاد بسترهای مناسب و کاربردی تحلیل داده است. Microsoft Cognitive Toolkit (CNTK) که بیشترین رشد را داشته است، یک کتابخانه متن باز یادگیری عمیق است .
ابزارهایی که با کاهش محبوبیت مواجه شده اند را در جدول زیر می توانید مشاهده کنید :
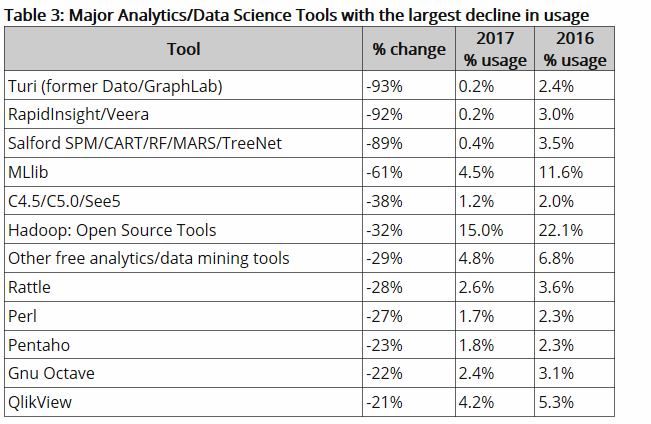
که در این بین، کاهش محبوبیت ابزارهای هدوپ، کمی شگفتی ساز است هر چند رشد اسپارک تا حدودی این روند را توجیه می کند.
ابزارهای یادگیری عمیق
یادگیری عمیق که شکل نوین شبکه های عصبی است و قادر به حل بسیاری از مسائل دسته بندی دنیای معاصر است، امروزه بسیار محبوب شده است و ابزارهایی که امکان استفاده از آنرا فراهم می کنند هم روز به روز محبوب تر میشوند. محبوب ترین این ابزار با درصد رواج هریک عبارتند از :
- Tensorflow, 20.2% usage
- Keras, 9.5%
- Theano, 5.8%
- Other Deep Learning Tools, 4.8%
- Microsoft CNTK, 3.4%
- Caffe, 3.1%
- PyTorch, 3.0%
- DL4J, 2.2%
- mxnet, 1.8%
- Torch, 1.2%
- Lasagne, 0.9%
ابزارهای کلان داده / هدوپ
میزان رواج ابزارهای مرتبط با کلان داده و هدوپ در سال ۲۰۱۷ هم به شرح ذیل می باشد :
- Spark, 22.7%
- Hadoop: Open Source Tools, 15.0%
- SQL on Hadoop tools, 10.3%
- Hadoop: Commercial Tools 7.6%
زبانهای برنامه نویسی
محبوبیت زبانهای برنامه نویسی حوزه علم داده هم از قرار زیر است :
- Python, 52.6% usage (was 45.8% in 2016), 15% up
- R language, 52.1% (was 49.0%), 6% up
- SQL, 34.9% (was 35.5%), 2% down
- Java, 13.8% (was 16.8%), 18% down
- Unix shell/awk/gawk, 9.6% (was 10.4%), 7% down
- C/C++, 6.3%, (was 7.3%), 13% down
- Perl, 1.7%, (was 2.3%), 27% down
- Julia, 1.1%, (was 1.1%), no change
جدول کامل درصد استفاده و رواج هر یک از ابزار و کتابخانه های فوق را می توانید در این آدرس مشاهده کنید.
آیا اسپلانک(SPLUNK) جز این ابزارها برای حوزه بیگ دیتا نمیباشد؟
اسپلانک یک ابزار بسیار حرفه ای برای مانیتورینگ، بررسی و ذخیره لاگ های تولید شده توسط سرورها و حسگرهاست و چون خاص منظوره است، جزء ابزار اصلی کلان داده لحاظ نشده است.