
نگاهی به معماری داخلی کاساندرا
کاساندرا با معرفی یک معماری نظیر به نظیر یا Peer to Peer که در آن، هیچ ماشینی ارجحیتی به سایر ماشین ها ندارد، یک سامانه کاملاً توزیع شده معرفی کرد که در آن هیچ نقطه شکست یا گلوگاهی وجود ندارد و با رخداد خطا در هر ماشین، سایر ماشین ها وظایف آنرا برعهده می گیرند. به این صورت که داده های موجود در سیستم معیوب، به سرعت از طریق کپی های موجود در سایر سیستم ها، بازتولید شده و مجدداً در شبکه توزیع میشود و کاربر نهایی به هیچ عنوان متوجه رخداد خطا در یکی از سیستم ها نمی شود.
بنابراین تکرار داده ها در کاساندرا یک امر کاملاً الزامی است هم به دلیل محافظت از داده ها در مقابل خطاهای سیستمی و هم به دلیل افزایش سرعت خواندن داده ها. میزان تکرار داده ها در کاساندرا، هنگام ایجاد یک بانک اطلاعاتی جدید که در فرهنگ کاساندرا به آن فضای نام (Keyspace) میگوئیم، از طریق پارامتر Replication Factor یا فاکتور تکرار یا (RF) تنظیم می شود. RF=3 به این معناست که هر از داده در کاساندرا، سه کپی در سه سیستم مجزا باید نگهداری شود.
تکرار داده ها در سیستم های مختلف، مشکلاتی را هم به دنبال خواهد داشت. فرض کنید شما داده ای را از یک سیستم حذف و یا به روز رسانی کرده باشید، اما در سایر سیستم ها هنوز این تغییرات اعمال نشده باشد، بنابراین، برخی از کاربران، داده های قدیمی و برخی هم داده های جدید را دریافت خواهند کرد. برای رفع این مشکل و تضمین جامعیت داده ها (Consistency) ، قانون زیر هنگام نوشتن و خواندن داده ها در کاساندرا اعمال می شود :
که در آن، CL.READ حداقل تعداد سیستمهایی است که یک داده خاص از تمام آنها باید خوانده شود تا مطمئن باشیم که داده درست را خوانده ایم. CL.WRITE هم حداقل تعداد نودهایی است که یک دستور نوشتن، باید در تمام آنها اعمال شود تا عمل نوشتن با موفقیت به اتمام برسد. RF هم همان ضریب تکرار است . بنابراین فرمول فوق، بیانگر این اصل است که مجموع نودهای لازم برای خواندن و نوشتن اطلاعات باید از ضریب تکرار بیشتر باشد.
یکی از رایجترین پیکربندیهای کاساندرا، پیکربندی زیر است که در آن، برای هر نوشتن و خواندن، دو سیستم در شبکه باید مورد استفاده قرار گیرند.
CL.READ = حدنصاب = RF/2 + 1 = 2
CL.WRITE = حدنصاب = RF/2 + 1 = 2
حدنصاب، برابر نصف + ۱ ضریب تکرار در نظر گرفته می شود.
به این ترتیب حتی اگر یک سیستم دچار نقص شود، داده مورد نیاز از دو سیستم باقیمانده که حاوی تکرارهای آن داده هستند خوانده می شود واگر این دو داده با هم فرق داشتند، داده ای برنده می شود و به کاربر برگردانده می شود که جدیدتر باشد (الگوریتم Last Write Wins یا LWW – برنده، جدیدترین داده است). این پیکربندی، کمترین سربار را برای سیستم ها دارد و تضمین کننده جامعیت و در دسترس بودن داده ها هم هست.

در کاساندرا وقتی رکوردی در پایگاه داده قرار است درج (Insert) شود، یک نسخه از آن در فایل ثبت تراکنشی به نام CommitLog ذخیره میشود و سپس یک نسخه از آن در حافظه و در ساختاری به نام Memtableثبت شده، آماده انتقال به دیسک می گردد. در این مرحله، عملیات نوشتن به پایان می رسد و انتقال داده ها از حافظه به دیسک را خود کاساندرا به تدریج و به صورت پشت صحنه انجام میدهد. نوشتن یک نسخه از رکورد در فایل ثبت تراکنش، تضمین می کند که اگر داده های حافظه از بین برود، نسخه ای از اطلاعات درون دیسک وجود دارد که به کمک آن می توان عملیات بازیابی را انجام داد.
نوشتن در فایل ثبت تراکنش یا همان CommitLog به صورت سریالی و همیشه در انتهای فایل صورت میگیرد و همانطور که می دانید نوشتن در انتهای فایل همیشه سریعترین حالت ممکن ذخیره در فایل است. نوشتن در Memtableهم چون در حافظه اصلی است، بسیار سریع صورت میگیرد و این دو عامل، دلیل اصلی راندمان بالای کاساندرا در عملیات نوشتن هستند. البته معماری اصلی پشت صحنه این ایده، الگوریتم Log Structured Merge Trees است که ایده اصلی آن نوشتن ترتیبی در انتهای فایل و استفاده ترکیبی از حافظه و دیسک برای ذخیره و بازیابی داده ها و در صورت نیاز، ادغام نتایج برای یافتن جدیدترین داده است. عملیات نوشتن در کاساندرا به اتمام میرسد و سایر عملیاتی که در ادامه شرح داده میشود عملیات داخلی است که خود کاساندرا برای مدیریت داده ها و ذخیره و بازیابی آنها در دیسک انجام میدهد که مستقل از عمل نوشتن است. بنابراین دلیل اصلی سرعت و کارآیی بالای کاساندرا در نوشتن هزاران داده در ثانیه مربوط به همین نوشتن در انتهای فایل و نیز نوشتن در حافظه است که هر دو عملیاتی بسیار سریع است.
برای هر جدول در حافظه یک Memtable وجود دارد. زمانی که میزان فضای تعیین شده برای یک Memtableاز مقدار آستانه مشخص شده برای آن (memtable_cleanup_threshold) عبور کند، یک Memtableجدید برای جدول در نظر گرفته می شود و Memtableپر شده در صف انتقال به دیسک قرار می گیرد و در ساختار فایلی به نام SSTable (مخفف Sorted String Table که یک جدول مرتب شده بر اساس کلیدهاست) نوشته میشود. نکته بسیار مهم درباره SSTableها این است که این ساختار، فقط خواندنی است و امکان تغییر آن (جز برای اعمال نشانگر حذف) وجود ندارد . بنابراین اگر Memtableبعدی پر شد، در یک SSTable جدید ذخیره میگردد. راجع به جزییات این مساله و اینکه با این تعداد زیاد SSTableها چگونه رفتار می شود، در ادامه صحبت خواهیم کرد. با انتقال داده ها به دیسک و اطمینان از ذخیره پایدار آنها، داده های مربوطه در فایل ثبت تراکنش هم پاک میشوند تا فضای دیسک به صورت بهینه استفاده شود.
هنگام نیاز به خواندن یک داده در کاساندرا، سطرهای حاوی داده، همزمان از دیسک (SSTable) و نیز حافظه (Memtable) خوانده می شود و چون ممکن است داده های موجود در حافظه نسبت به داده های ذخیره شده، جدیدتر باشند، در انتهای کار وقبل از ارسال داده به کاربر، عملیات ادغام روی داده ها صورت میگیرد و جدیدترین رکورد، به کاربر ارسال میشود.
شکل زیر این فرآیند را نشان میدهد :
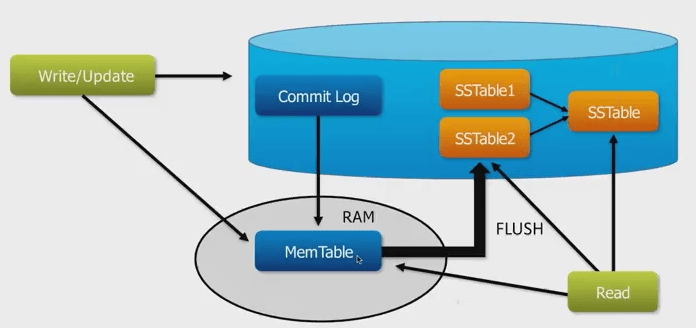
برای توضیح دقیقتر شکل فوق، بهتر است نگاهی جداگانه به فرآیند خواندن و نوشتن در کاساندرا بیندازیم. کاساندرا برای اینکه بتواند سریعترین زمان ممکن را برای نوشتن و خواندن اطلاعات فراهم کند، از ساختاری چندلایه برای نوشتن و خواندن اطلاعات استفاده میکند. نگاهی دقیقتر به این دو فرآیند و لایه هایی که کاساندرا برای انجام بهینه هر یک درنظر گرفته است، دیدی مناسب از ساختار داخلی کاساندرا به ما خواهد داد.
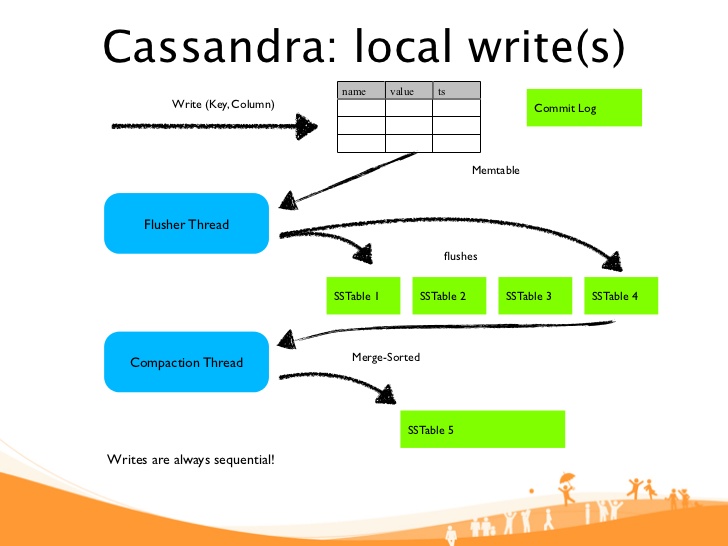
نوشتن در کاساندرا مراحل زیر را طی میکند :
- ابتدا رکورد جدید در فایل
CommitLogنوشته میشود. - در مرحله دوم، این رکورد جدید که در کاساندرا مجموعه ای از کلید/مقدار ها خواهد بود، در حافظه و در ساختاری به نام
Memtableدرج میشود.Memtableیک مجموعه مرتب از کلید/ مقدارهاست که ساختار داخلی بهینه ای برای جستجو و درج اطلاعات دارد. (ساختار LSM tree که مشابه با درختهای +B بوده اما مقیاس پذیرتر است.) - در این مرحله، عملیات نوشتن به اتمام رسیده است و کاساندرا میتواند درخواست بعدی را پاسخ دهد. (البته بسته به تنظیمات کاساندرا، یک رکورد در چندین نود به همین ترتیب نوشته میشود و زمانی که حد نصاب نوشتن اعمال شد، عملیات نوشتن موفقیت آمیز تلقی میگردد.)
- هنگامی که
Memtableپرشد، تمام داده های آن به صورت خودکار بر روی دیسک در ساختاری به نامSSTableذخیره میشود. جهت اطلاع اینکه ساختار داخلی بخش داده یکSSTableمشابه باMemtableو یکLSM treeاست. - در این زمان، فایل CommitLog میتواند خالی شود.
- به صورت دوره ای و برای جلوگیری از ازدیاد تعداد
SSTableها، این جداول با هم دیگر ادغام شده و یکSSTableبزرگتر را تشکیل می دهند.
روند کامل این فرآیند را به صورت نمودار توالی در مستندات رسمی آپاچی در این آدرس میتوانید مشاهده کنید. (نماهای ذخیره شده یا Materialized Views را که در این نمودار مشاهده می کنید، قبلاً در سایت مهندسی داده توضیح داده شده است)
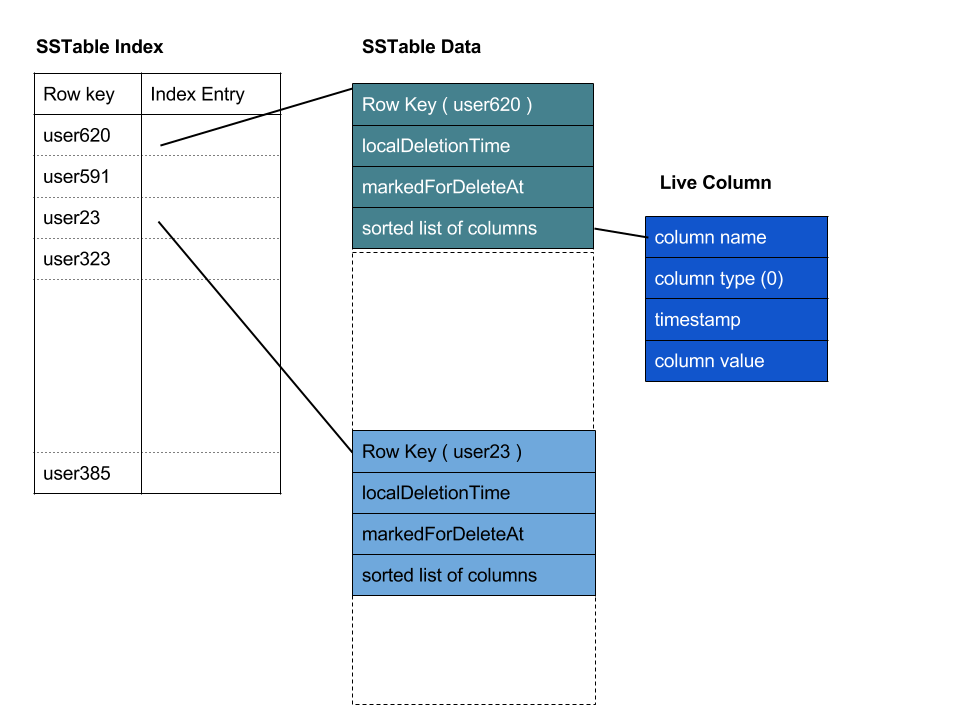
از این پس دیگر آن SSTableتغییر پیدا نمیکند. SSTableیک ساختار فقط خواندنی، مرتب شده بر اساس کلید و تغییرناپذیر (immutable) است که این مرتب بودن، پیمایش سریالی و پشت سرهم داده ها را میسر میکند. برای دسترسی تصادفی به یک داده خاص در این ساختارهم از فایل ایندکس می توانیم استفاده کنیم.
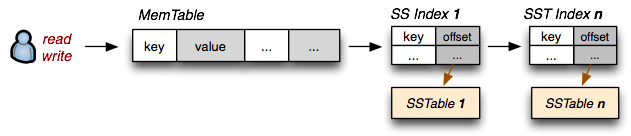
سوالی که اینجا پیش میآید این است که چه تعداد
SSTableبه ازای یک جدول خواهیم داشت ؟ در حقیقت تعدادSSTableها با تعدادMemtableهای منتقل شده از حافظه به دیسک مرتبط است و ممکن است از یک تا چندینSSTableبه ازای هر جدول داشته باشیم. البته با رسیدن تعدادSSTableها به یک حد مشخص و یا در بازه های زمانی یا توسط درخواست کاربر، عملیات کوچک سازی (Compaction) روی اینSSTableانجام میشود و تمامSSTableها به یک عدد کاهش مییابد و در این بین داده های نامعتبر و قدیمی و حذف شده هم پاک میشوند.
هنگامی که یک داده را تغییر میدهیم، این داده در یک Memtable جدید ثبت میشود و در یک SSTableجدید هم نهایتاً ذخیره خواهد شد، بنابراین ممکن است به ازای یک داده خاص، چندین نسخه از آنرا در دیتابیس داشته باشیم که هنگام خواندن اطلاعات باید این مورد را حتماً لحاظ کنیم.
چون تعداد SSTableها به تدریج زیاد میشود و هنگام خواندن یک داده، باید در تمام آنها برای یافتن جدیدترین نسخه از یک داده، جستجویی انجام دهیم، نیاز به ساختارهای کمکی برای افزایش بازدهی فرآیند خواندن داریم.

نگاهی به مدلسازی داده ها در کاساندرا
چند روز پیش یکی از خوانندگان سایت مهندسی داده، سوالی را در خصوص نحوه طراحی جداول برای یک کاربرد شبکه اجتماعی در کاساندرا مطرح کرد با این توضیحات که قرار است فهرست دنبال کنندگان یک کاربر را ذخیره کنیم . برای این منظور دو جدول در کاساندرا در نظر گرفته ایم : جدول followers و …
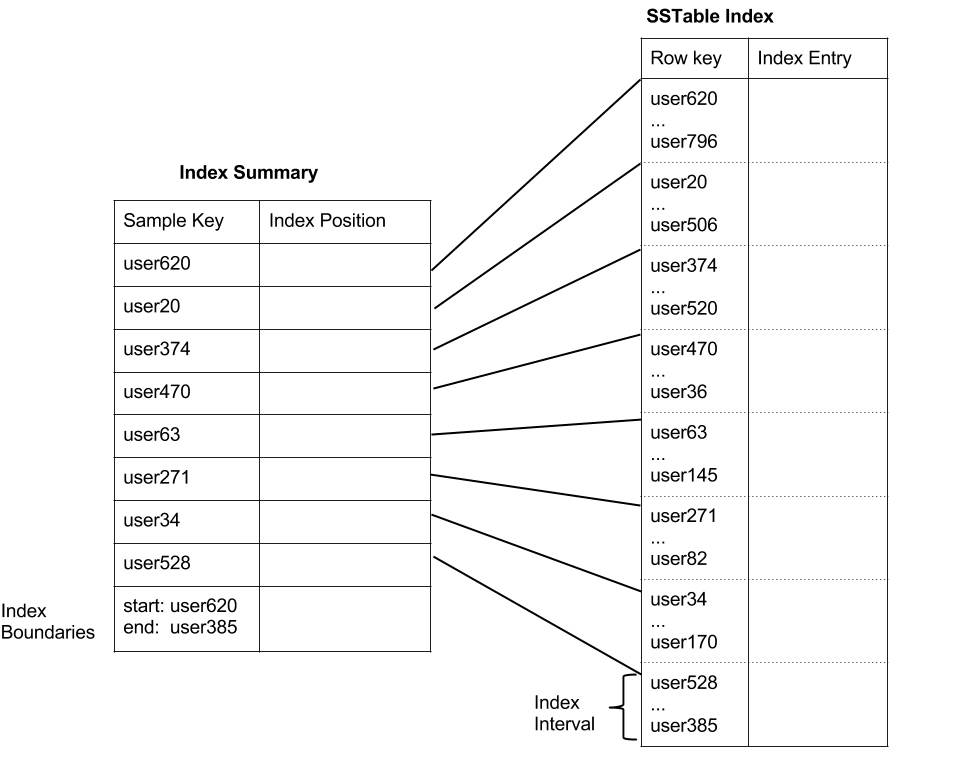
به همین دلیل SSTable Index که مکان شروع هر سطر از یک جدول را در آن مشخص میکند هم جزء ملزومات یک SSTableاست که هنگام انتقال یک Memtable به دیسک و ساخت SSTableجدید به روزرسانی میشود و روی دیسک ذخیره میگردد.
تعداد SSTable Index ها هم ممکن است زیاد باشد، بنابراین یک ساختار مقیم در حافظه هم به نام SSTable Index Summary هم داریم که خلاصه ای از اندیس اصلی را درون خود نگهداری میکند و هنگام جستجوی اطلاعات، ابتدا از این فایلهای مقیم در حافظه شروع میکنیم. به این ایندکس، PartionIndex هم می گوئیم و اگر هم Partition Summary جایی دیدید، اشاره به همین مطلب دارد(خلاصه فایل شاخص یک SSTable).
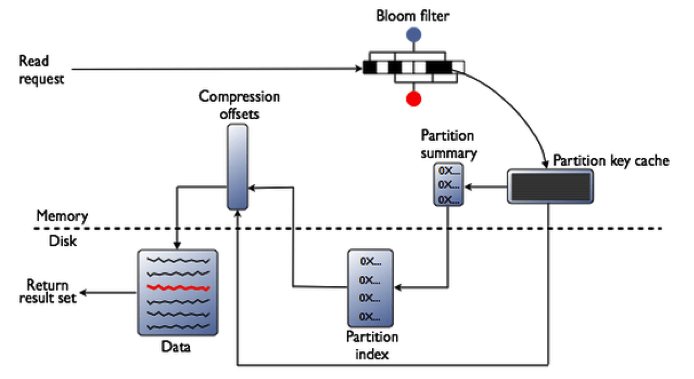
آخرین لایه ای که کاساندرا برای افزایش سرعت بازیابی اطلاعات در نظر گرفته است (غیر از بحث cache برای سطرها و برای کلیدها که قابل فعال شدن است)، فیلتر بولوم است که به ازای هر SSTable(از مجموع SSTable هایی که به ازای یک جدول کاساندرا ایجاد شده است) تعیین میکند که یک داده خاص درون آن، وجود دارد یا نه و معمولاً درون حافظه هم نگهداری میشود که سرعت جستجوی اطلاعات افزایش یابد و خروجی آن هم لیستی از SSTableهاست که ممکن است این داده در آنها وجود داشته باشد و در مرحله بعد، جستجو در خود SSTableها صورت میگیرد که در ادامه، روند کامل آن تشریح شده است.
با این توضیحات، فرآیند خواندن اطلاعات در کاساندرا به صورت زیر است :
- ابتدا سریعترین یا نزدیکترین نود حاوی داده در شبکه تعیین می شود و در خواست خواندن داده به آن نود یا نودها ارسال میشود.
- قبل از هر چیز، اگر قابلیت cache سطر فعال باشد (
Row Cache)، داده مورد نظر در این حافظه جستجو شده و در صورت وجود، به کاربر برگشت داده میشود و عملیات خواندن به اتمام میرسد. توضیح اینکه، با فعال بودن این قابلیت، با خواندن هر سطر توسط کاربر ازSSTable، داده های آن برای مراجعات بعدی در حافظه cache به صورت موقت قرار میگیرد. - سپس بولوم فیلتر موجود در حافظه به ازای هر
SSTableبررسی میشود تا مشخص شود کلید مورد نظر در کدامینSSTableها ممکن وجود داشته باشد. (وجود کلید را تخمین میزند اما عدم وجود را با قطعیت بیان می کند : ویژگی اصلی بولوم فیلتر) - سپس حافظه نهان کلیدها چک می شود (Key cache) تا مکان دقیق آن داده در
SSTableها مشخص شود و به سرعت قابل واکشی باشد. (در صورتی که قابلیت Cache کلیدها را فعال کرده باشید. ) . - درصورتیکه در مرحله قبل، داده ها پیدا نشدند فایل
Partition Summaryیا همانPartiton Cache(موجود در حافظه به ازای هرSSTable) بررسی می شود تا مکان تقریبی جستجو در فایلPartition Indexمشخص شود. سپس فایلPartition Index(همانSSTable Index) از دیسک خوانده شده ، مکان نهایی داده مورد نظر درSSTableمشخص میشود.
- اگر داده ها فشرده سازی شده باشند، ابتدا فایل راهنمای فشرده سازی خوانده میشود و به کمک آن، داده ها از دیسک خوانده شده و بخش مورد نظر، از حالت فشرده خارج میشود تا بتوان داده های مورد نیاز را بازیابی کرد.
- فایلهای داده پویش شده و پس از یافتن سطر مورد نظر، ستونها و دادههای درخواستی کاربر بازیابی میشود.
- در آخرین مرحله، داده های موجود در
Memtableآن جدول هم خوانده شده، در صورتیکه چندین مقدار مختلف به ازای یک داده موجود باشد، براساس مهر زمان یا نشانگر مرگ(Tombstoneکه در ادامه توضیح داده شده است) تصمیم گیری نهایی صورت میگیرد. - نتایج به کاربر برمیگردد و بسته به تنظیمات
Cacheکلید و سطر هم به روز رسانی میشود.
شکل زیر این روند را به صورت شماتیک نمایش می دهد :
نمودار توالی عملیات خواندن در کاساندرا طبق مستندات رسمی سایت آپاچی به شرح ذیل است :

عملیات حذف در کاساندرا
قبلاً اشاره شد که SSTable ها تغییرناپذیرند. با این فرض، زمانی که رکوردی را از دیتابیس حذف میکنید چه اتفاقی میافتد؟
در اغلب پایگاه داده بلافاصله آن رکورد از روی دیسک حذف میشود. اما در اینجا، در کاساندار چنین اتفاقی رخ نمیدهد! کاساندار با دستور DELETE همانند یک دستور insert یاupsert رفتار میکند! به این صورت که رکوردی، با یک مارکر حذف به نام tombstone(نشانگر مرگ یا سنگ قبر)، به SSTable اضافه میشود(این یک استثنای کوچیک در ساختار فقط خواندنی SSTable هاست که یک نشانگر مرگ به یک داده اضافه میشود) و مشخص میکند که یک رکورد حذف شده است. .tombstone در حین فرایند compaction از SSTable ها حذف میشوند.
چرا هنگام حذف یک داده در کاساندرا این اتفاق رخ میدهد؟ چرا همان رکورد مورد نظر حذف نمیشود؟ در ادامه علت این کار را با یک مثال نشان خواهیم داد.
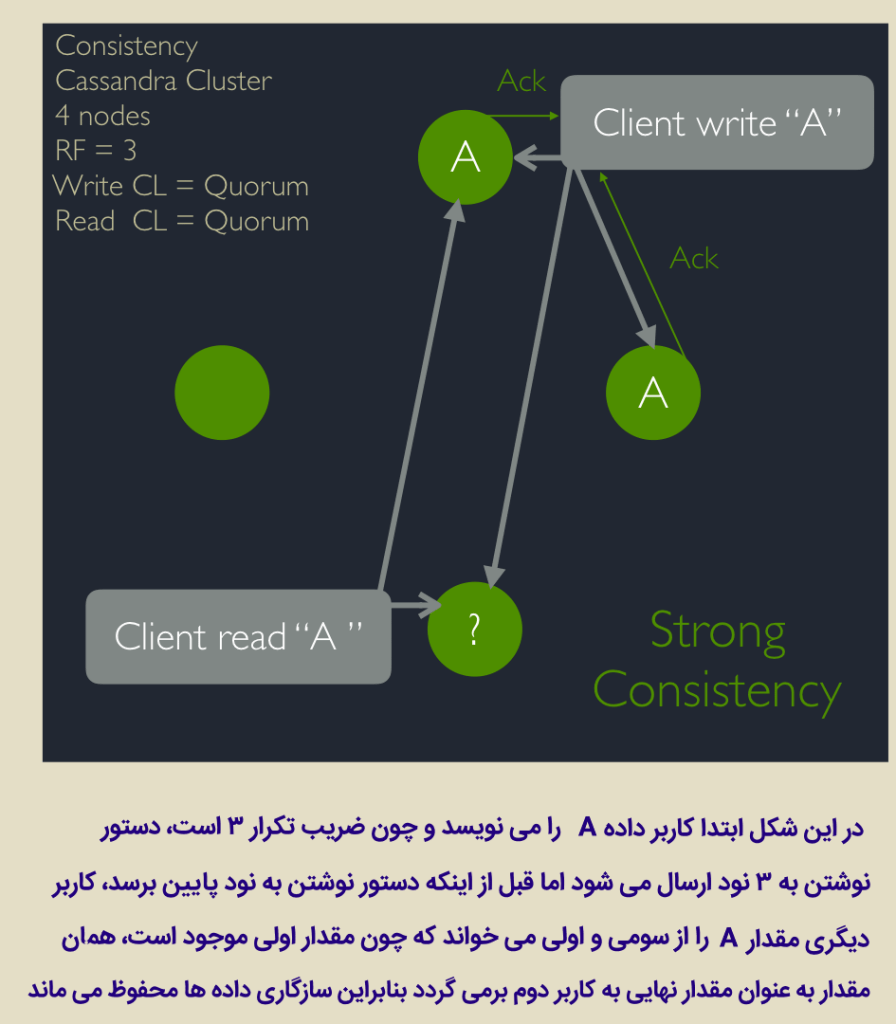
کلاستری با ۴ گره و با تنظیمات زیر مشابه با فوق فرض کنید :
فرض کنید در ابتدا داده A بر روی یکی از گرهها نوشته شود. همانطور که انتظار داریم، داده مورد نظر به سه ماشین دیگر نیز باید فرستاده شود (ضریب تکرار ۳ است) اما به هر دلیلی این دستور به گره (ماشین) سوم نمی رسد یا در بین اینکه به گره سوم برسد و از دو گره قبلی حذف شده است، دستور خواندن A به کاساندرا ارسال میشود که کاساندرا هم آن دستور را به گره سوم که هنوز داده A در آن حذف نشده است و نیز یکی از گرههای قبلی ارسال می کند.چه اتفاقی رخ میدهد؟
یکی از گرهها مقدار A و گره دیگر مقدار تهی را بازخواهد گرداند. کدام داده صحیحی است؟A یا تهی؟! در این حالت، مقدار A به عنوان نتیجه به کاربر برگردانده میشود که یک تصمیم اشتباه است .

حال بیایید و همین سناریو را با tombstone یا مهر حذف (یا نشانگر مرگ) بررسی کنیم. زمانی که دستور حذف به یک ماشین ارسال میشود، داده A با یک tombstone علامت گذاری میشود. حال اگر بلافاصله دستور Read به یکی از گرهها که هنوز فرصت علامتگذاری حذف را پیدا نکرده است، ارسال گردد، یکی از گرهها مقدار A را باز خواهد گرداند، و گره دیگر اعلام خواهد کرد که داده A حذف شده است. حال با قطعیت میتوان گفت که داده A حذف شده است.
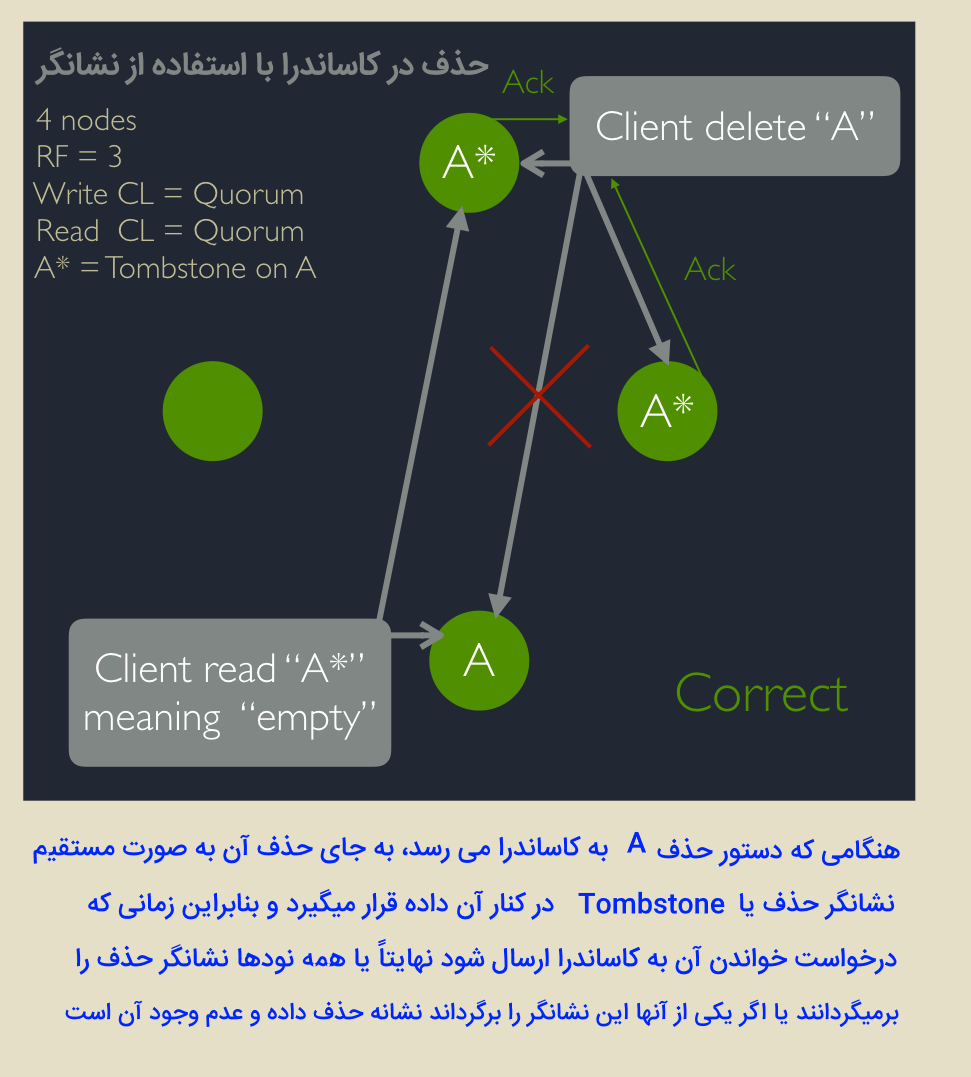
برای مشاهده جزییات بیشتر عمل حذف در کاساندرا که دو شکل فوق و نیز دوشکل ابتدایی مقاله از آن گرفته شده است، به این آذرس مراجعه کنید.
پی نوشت
متن فوق به پیشنهاد یکی از خوانندگان عزیز سایت، جناب آقای فرزین باقری نوشته شده است که بخش انتهایی مقاله که فرآیند حذف در کاسانداراست، توسط ایشان آماده و ارسال گردیده است.