
۱۳ چارچوب منبعباز برای کسب مهارت در یادگیری ماشین، شبکه های عصبی و یادگیری عمیق
در یک سال گذشته، یادگیری ماشینی به طرز بیسابقهای به جریان اصلی دنیای فناوری تبدیل شده است. جالب اینکه روند توسعه محیطهای ابری ارزانقیمت و کارتهای گرافیکی پرشتاب و قدرتمند، نقش بسزایی در این زمینه داشتهاند. این عوامل منجر به رشد انفجاری چارچوبهایی شده است که اکنون برای یادگیری ماشینی در اختیار کاربران قرار دارند. چارچوبهایی که بخش عمدهای از آنها منبعباز هستند. اما فراتر از منبعباز بودن، توسعهدهندگان به شیوه پیادهسازی انتزاعی آنها بیش از پیش توجه کردهاند.
این چارچوبها، این ظرفیت را ایجاد کردهاند تا دسترسی به پیچیدهترین بخشهای یادگیری ماشینی برای همگان امکانپذیر باشد. همین موضوع باعث شده است تا یادگیری ماشینی در طیف گستردهای از کلاسها در اختیار توسعهدهندگان قرار گیرد. بر همین اساس، در این مقاله تعدادی از این چارچوبهای یادگیری را معرفی خواهیم کرد.
در انتخاب این ابزارها سعی کردهایم چارچوبهایی را که بهتازگی معرفی یا در یک سال گذشته بازبینی شدهاند، بررسی کنیم. چارچوبهایی که در ادامه با آنها آشنا خواهید شد، امروزه به طرز گستردهای در دنیای فناوری استفاده میشوند. این چارچوبها با دو رویکرد کلی طراحی شدهاند. اول اینکه به سادهترین شکل ممکن مشکلات مرتبط با حوزه کاری خود را حل کنند و دوم آنکه در چالش خاصی که در ارتباط با یادگیری ماشینی پیش روی توسعهدهندگان قرار دارد، به مقابله برخیزند.
ApacheSpark MLib
«Apache Spark» به دلیل اینکه بخشی از خانواده هادوپ است، ممکن است در مقایسه با رقبای خود شهرت بیشتری داشته باشد. در حالی که این چارچوب پردازش دادههای درونحافظهای خارج از هادوپ متولد شد، اما بهخوبی موفق شد در اکوسیستم هادوپ خوش بدرخشد. (شکل ۱) Spark یک ابزار یادگیری ماشینی رونده است. این مهم به لطف کتابخانه الگوریتمهای روبهرشدی که برای استفاده روی دادههای موجود در حافظه استفاده میشوند، به وجود آمده است؛ الگوریتمهایی که از سرعت بالایی برخوردار هستند.
شکل ۱: Spack MLib یک کتابخانه یادگیری ماشینی گسترشپذیر است.
الگوریتمهای مورد استفاده در اسپارک دائماً در حال گسترش و تجدیدنظر هستند و هنوز به عنوان موجودیت کاملی خود را نشان ندادهاند. سال گذشته در نسخه ۱٫۵، تعداد نسبتاً زیادی الگوریتم جدید به این ابزار یادگیری ماشینی افزوده شد، تعدادی از آنها الگوریتمهای بهبود یافته بودند، در حالی که تعداد دیگری در جهت تقویت پشتیبانی از MLib که در پایتون استفاده میشود، عرضه شدهاند؛ پلتفرم بزرگی که به یاری کاربران رشته آمار و ریاضیات آمده است. Spark نسخه ۱٫۶ میتواند کارهای Spark Ml را از طریق یک پایپلاین (مجموعهای از عناصر پردازشی دادهای) پایدار به حالت تعلیق (Suspend) درآورده و مجدداً از حالت تعلیق خارج کند و به مرحله اجرا درآورد. آپاچی اسپارک متشکل از ماژولهای یادگیری ماشینی (MLib)، پردازشگراف (GraphX)، پردازش جریانی (Spark Streaming) و Spark SQL است.
Apache Singa
چارچوبهای یادگیری عمیق، بازوی قدرتمند یادگیری ماشینی به شمار میروند و توابع قدرتمندی را در اختیار یادگیری ماشینی قرار میدهند. قابلیتهایی همچون پردازش زبان طبیعی و تشخیص تصاویر از جمله این موارد هستند. Singa بهتازگی به درون Apache Incubator راه پیدا کرده است؛ چارچوب منبعبازی که با هدف سادهسازی آموزش مدلهای یادگیری عمیق روی حجم گستردهای از دادهها استفاده میشود. (شکل۲) Singa مدل برنامهنویسی سادهای برای آموزش شبکههای یادگیری عمیق بر مبنای کلاستری از ماشینها ارائه میکند.
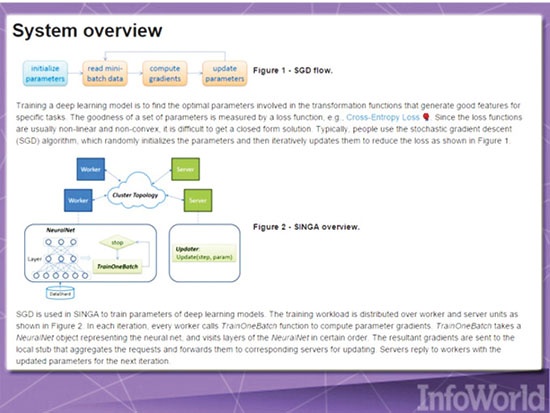
شکل ۲: نمایی از یادگیری ماشینی Singa
این چارچوب از انواع رایجی از آموزشها همچون شبکه عصبی پیچیده (Convolutional neural network)، ماشین بولتزمن محدود (Restricted Boltzmann machine) و شبکه عصبی بازگشتی (Recurrent neural network) پشتیبانی میکند. مدلها میتوانند همزمان یکی بعد از دیگری یا در زمانهای مختلف و پهلوبهپهلو (side by side) آموزش ببینند. انتخاب هر یک از این روشها به این موضوع بستگی دارد که کدامیک برای حل مشکل بهتر جواب میدهند. Singa میتواند فرایند کلاستربندی با Apache Zookeeper را سادهتر کند.
Caffe
چهارچوب یادگیری عمیق Caffe بر مبنای بیان (expression)، سرعت (speed) و پیمانهای بودن (modularity) ساخته شده است. گفتنی است در دنیای کامپیوترها، modularity اشاره به طراحی کامپیوترها در قالب بلوک ساختمانی دارد. این کار با هدف افزایش کارایی و کیفیت تجهیزات انجام میشود. این پروژه اولین بار در سال ۲۰۱۳ و به منظور تسریع در پروژه بینایی ماشینی طراحی شد. (شکل ۳) Caffe از آن زمان به بعد توسعه پیدا کرده و از برنامههای دیگری همچون گفتار و چندرسانهای پشتیبانی کرده است.
شکل ۳: چارچوب یادگیری ماشینی Caffe، قدرتمند و ساده
مهمترین مزیت Caffe در سریع بودن آن خلاصه میشود. بر همین اساس Caffe به طور کامل در زبان سیپلاسپلاس و با پشتیبانی از شتابدهنده کودا نوشته شد. چارچوب یادشده میتواند هر زمان که نیازمند پردازش خاصی هستید، میان پردازشگر مرکزی کامپیوتر و پردازشگر گرافیکی سوییچ کند. این توزیع شامل مجموعهای از مدلهای مرجع منبعباز و رایگانی است که بهخوبی با دیگر مدلهای ساختهشده توسط جامعه کاربران Caffe هماهنگ میشود.
Microsoft Azure ML Studio
با توجه به دادههای حجیم و نیاز به مکانیزم قدرتمند محاسباتی، کلاود محیط ایدهآلی برای میزبانی برنامههای یادگیری ماشینی به شمار میرود. مایکروسافت از مکانیزم پرداختی خاص خود در ارتباط با سرویس آژر و یادگیری ماشینی استفاده میکند؛ بهطوری که کاربران در بیشتر نسخههای ماهیانه، ساعتی و رایگان میتوانند از Azure ML Studio استفاده کنند. شایان ذکر است پروژه HowoldRobot نیز بر مبنای همین سامانه ساخته شده است. Azure ML Studio به کاربر اجازه ساخت و آموزش مدلهای مطبوعش را میدهد. (شکل ۴) در ادامه توابعی در اختیار کاربران قرار میدهد که با استفاده از آنها از سرویسهای دیگر استفاده کنند.
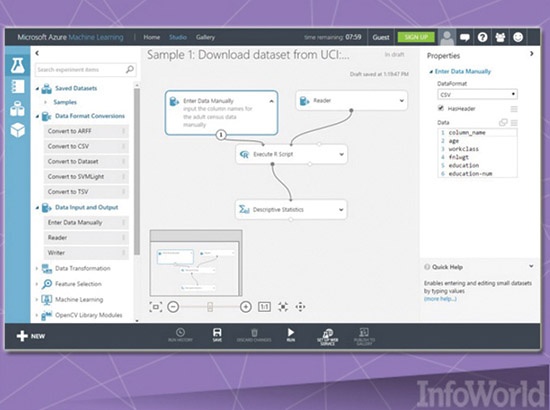
شکل ۴: نمایی از محیط Microsoft Azure ML Studio
کاربران به ازای هر حسابی که برای یک مدل در اختیار دارند، به ۱۰ گیگابایت فضا دسترسی خواهند داشت. در کنار این فضای ذخیرهسازی، مایکروسافت دسترسی به طیف گستردهای از الگوریتمها را برای کاربران امکانپذیر ساخته است؛ الگوریتمهایی که از سوی مایکروسافت یا شرکتهای ثالث ارائه شدهاند. البته به این نکته توجه کنید برای دسترسی به این چهارچوب لزوماً به حساب کاربری نیاز ندارید. مایکروسافت مکانیزمی را طراحی کرده است که در آن کاربران میتوانند بهطور ناشناس وارد شده و از Azure ML Studio به مدت هشت ساعت استفاده کنند.
Amazon Machine Learning
رویکرد کلی آمازون در خصوص سرویسهای ابری بر مبنای الگوی خاصی قرار دارد. در این رویکرد آمازون سعی کرده است اصول زیربنایی را در اختیار مخاطبان خود قرار دهد تا کاربران با استفاده از آنها، برنامههای سطح بالای خود را طراحی کنند و آگاه شوند که دقیقاً به چه چیزی نیاز دارند. الگویی که به این شکل از سوی آمازون ارائه شده است، اولین شکل از عرضه یادگیری ماشینی در قالب یک سرویس است و Amazon Machine Learning، اولین در نوع خود به شمار میرود. (شکل ۵) این سرویس به دادههای ذخیرهشده در Amazon S3، RedShift یا RDS متصل شده است و میتواند طبقهبندی دودویی، طبقهبندی چندکلاسی یا رگرسیون را بر مبنای دادههایی که یک مدل را ایجاد میکنند، به وجود آورد که این خدمات به میزان نسبتاً زیادی آمازونمحور هستند.
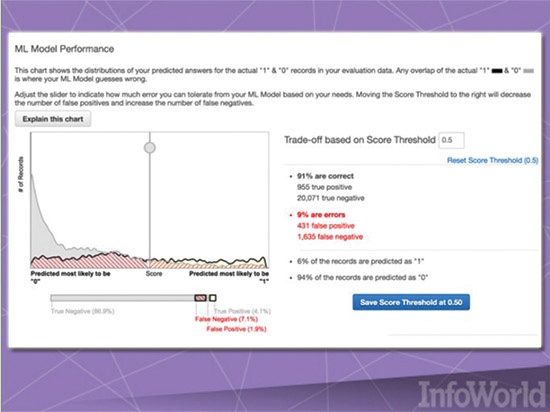
شکل ۵: نمایی از عملکرد یادگیری ماشینی آمازون
با این حال، این سرویس دارای سه مشکل عمده است. اول آنکه این سرویس به دادههای ذخیرهشده در آمازون متکی است، دوم آنکه قابلیت وارد یا خارج کردن مدلهای خروجی در آن وجود ندارد و سوم آنکه از مجموعه دادههای بیش از ۱۰۰ گیگابایت برای آموزش مدلها پشتیبانی نمیکند. با این حال، آمازون نشان داده است که چگونه یادگیری ماشینی میتواند از محصول تزیینی به محصول تجاری تبدیل شود.
Microsoft Distributed Machine Learning Toolkit
بیشتر کامپیوترهایی که امروزه کاربران استفاده میکنند، مشکل عمدهای در ارتباط با یادگیری ماشینی دارند. توان پردازشی یک کامپیوتر منفرد برای سازماندهی و مدیریت برنامههای یادگیری ماشینی کافی نیست. برای حل این مشکل میتوان از ترفند خاصی استفاده کرد؛ به طوری که این کامپیوترها گردهم آمده و به یکدیگر متصل شوند. آنگاه برنامههای یادگیری ماشینی بر مبنای آنها طراحی شده و اجرا شوند. ابزار یادگیری ماشینی توزیعشده DMTK، سرنام Distributed Machine Learning Toolkit، در اصل چارچوبی است که اسباب و وسایل لازم برای این مسئله را ارائه کرده است. (شکل ۶) بهطوری که وظایف مربوط به یادگیری ماشینی را روی کلاستری از سیستمها پخش کرده تا هر یک به بخشی از پردازشها رسیدگی کنند.

شکل ۶: DMTK راهکار مایکروسافت در زمینه ایجاد سیستمهای توزیعشده ویژه یادگیری ماشینی
چارچوب DMTK به جای آنکه راهحل کامل و جامعی را ارائه کند، سعی میکند از تعدادی از الگوریتمهای واقعی در اندازه کوچکتر استفاده کند. DMTK به گونهای طراحی شده است که میتوان بهراحتی در آینده آن را توسعه داد. این چارچوب برای کاربرانی که با منابع محدود روبهرو هستند، راهکار ایدهآلی به شمار میرود. برای مثال، هر گره در یک کلاستر، کش محلی خود را دارد. همین موضوع باعث میشود به میزان قابل توجهی ترافیکی که برای گره سرور مرکزی ارسال میشود، کم شود.
Google TensorFlow
شبیه به پروژه DMTK، پروژه تانسورفلو گوگل یک چارچوب یادگیری ماشینی است که در مقیاس گرههای چندگانه طراحی شده است. (شکل ۷) آنچنان که Google’s Kubernetes برای حل مشکلات داخلی گوگل طراحی شده بود، TensorFlow در قالب محصولی منبعباز ویژه کاربران عادی دنیای فناوری عرضه شده است.
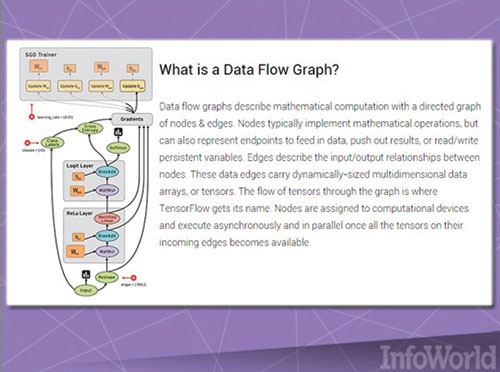
شکل ۷: نمایی از دیارگرام کارکردی TensorFlow
TensorFlow راهکاری است که نمودار جریان دادهها نامیده میشود؛ جایی که دستهای از دادهها (تانسورها) توسط مجموعهای از الگوریتمها که با استفاده از یک گراف توصیف میشوند، پردازش میشوند. حرکت دادهها از طریق سیستم، flows (جریان) نامیده شده و به همین دلیل این چارچوب TensorFlow نامیده میشود. گرافها انعطافپذیر هستند، بهگونهای که کاربران با استفاده از زبانهای برنامهنویسی سیپلاسپلاس یا پایتون میتوانند دوباره آنها را مونتاژ کنند؛ بهطوری که فرایندها روی پردازشگر مرکزی یا پردازشگر گرافیکی مدیریت شوند. گوگل برنامههای بلندمدتی برای TensorFlow در نظر گرفته است و قصد دارد همکاران ثالثی را مجاب سازد تا از این چارچوب استفاده کنند و آن را گسترش دهند.
Microsoft Computational Network Toolkit
اگر بر این باور هستید که DMTK پروژه جالب توجهی از سوی مایکروسافت به شمار میرود، باید بگوییم ابزار محاسباتی شبکه مایکروسافت در نوع خود جالب توجه است. CNTK یکی دیگر از ابزارهای یادگیری ماشینی است که از سوی مایکروسافت ارائه شده است. (شکل ۸) CNTK شبیه به TensorFlow گوگل است. از اینرو به کاربران اجازه میدهد شبکههای عصبی خود را از طریق گرافها ایجاد کنند. اگر CNTK را با چارچوبهایی نظیر Caffe، Theano و Torch مقایسه کنیم، مشاهده خواهیم کرد که CNTK در بعضی جهات نسبت به چارچوبهای یادشده برتریهایی دارد. از جمله این برتریها میتوان به سرعت و توانایی استفاده موازی از پردازندههای چندگانه مرکزی و گرافیکی آن اشاره کرد.
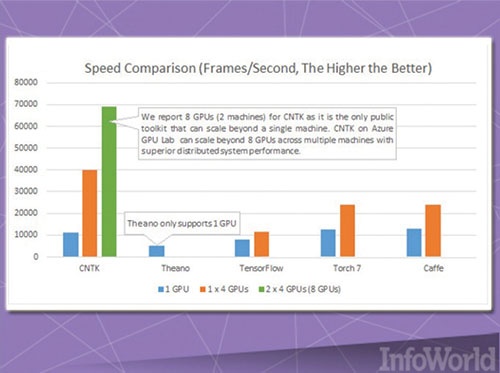
شکل ۸: CNTK راهکار پیشنهادی مایکروسافت در خصوص ساخت شبکههای عصبی توسط کاربران
مایکروسافت ادعا کرده است که برای آموزش کورتانا در زمینه تشخیص سریع صدا از CNTK همراه با کلاسترهای GPU بر مبنای بستر آژر استفاده کرده است. CNTK در اصل پروژهای توسعهیافته است؛ پروژهای که در واحد تحقیقات مایکروسافت برای تشخیص گفتار طراحی شده است. CNTK اولین بار در آوریل ۲۰۱۵ در قالب پروژهای منبعباز در اختیار کاربران قرار گرفت، اما در گیتهاب تحت مجوز MIT بازنشر شد.
(Veles (Samsung
Veles پلتفرم توزیعشدهای برای برنامههای یادگیری عمیق است. (شکل ۹) شبیه به TensorFlow و DMTK این چارچوب نیز به زبان سیپلاسپلاس نوشته شده است. اما از پایتون برای فرایندهای اتوماسیون و هماهنگی بین گرهها و برای انجام محاسبات از کودا یا OpenCL استفاده میکند. مجموعه دادهها قبل از آنکه به عنوان خوراکی برای تغذیه کلاسترها ارسال شوند، ابتدا تجزیه و تحلیل شده، به طور خودکار عادی سازی شده و برای کلاسترها ارسال میشوند.
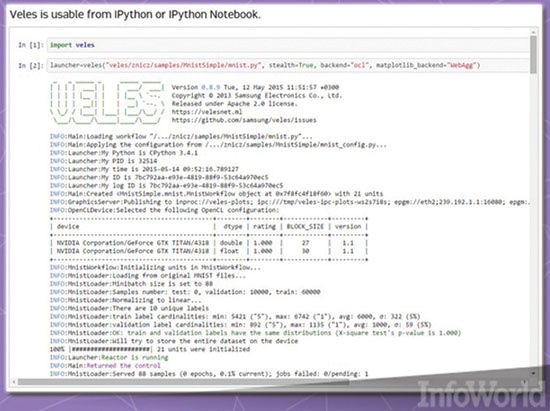
شکل ۹: Veles پلتفرم توزیعشده ویژه یادگیری عمیق
طراحی Veles به گونهای است که به کاربران اجازه میدهد با استفاده از توابع REST مدل آموزشدیدهشده را بیدرنگ در یک محصول استفاده کنند؛ با این فرض که سختافزار خوبی در اختیار داشته باشند. در دنیای محاسبات، REST سرنام representational state transfer، سبکی از معماری نرمافزاری در محیط وب است. معماری REST سعی در القای کارایی، گسترشپذیری، سادگی، قابلیت حمل، قابلیت اطمینان و قابلیت دید دارد. به طور دقیقتر REST سبکی از معماری بوده که شامل مجموعهای هماهنگ از اجزا، اتصالدهندهها و عناصر دادهای است که درون یک سیستم توزیعشده ابری قرار دارند، جایی که بر نقش مؤلفهها و مجموعه خاصی از تعامل میان عناصر دادهای به جای تمرکز بر جزئیات پیادهسازی، تأکید دارد. Veles از پایتون تنها برای کدهای ادغامی _ متصل کردن مؤلفههای غیرسازگار نرمافزاری _ استفاده نمیکند. آیپایتون _ در حال حاضر ژوپیتر _ ابزار مصورسازی دادهها (Data Visualization) و تحلیل میتواند برای مصورسازی و انتشار نتایج از یک کلاستر Velse استفاده شود. سامسونگ امیدوار است با عرضه این پروژه در قالب محصولی منبعباز تحرک بیشتری در توسعه آن به وجود آورد؛ به گونهای که تعامل خوبی با پلتفرمهای ویندوز و Mac OS X داشته باشد.
Brainstorm
Brainstorm پروژهای است که بر مبنای تز پایاننامه دانشجویان مقطع دکترا، «کلاوس گرف» و «روپشف استیوستاوا» در مؤسسه هوش مصنوعی «Dalle Molle» واقع در لوگانو سوییس در سال ۲۰۱۵ طراحی شد. (شکل ۱۰) هدف از طراحی این پروژه پیادهسازی شبکههای عصبی عمیقی بود که بر پایه عوامل سرعت، انعطافپذیری و سرگرمکنندهای اجرا شوند. BrainStorm با استفاده از زبان پایتون نوشته شده است. برایاناستورم میتواند روی پلتفرمهای مختلف اجرا و همچنین برای انجام محاسبات مختلف استفاده شود.
شکل ۱۰: BrainStorm راهکاری جدید ویژه محاسبات و پلتفرمها مختلف
برایاناستورم بهخوبی از مدلهای شبکه عصبی بازگشتی همچون LSTM پشتیبانی میکند. طراحان این پروژه به این دلیل زبان پایتون را انتخاب کردهاند که BrainStorm از همه ظرفیتهای موجود بهخوبی استفاده کند. به عبارت دقیقتر آنها توابع مدیریت دادهها را بهگونهای سازماندهی کردهاند که این توابع با استفاده از کتابخانه Numpy از پرازشگر مرکزی کامپیوتر و با استفاده از کودا از پردازندههای گرافیکی برای انجام محاسبات استفاده کنند. در برایاناستورم تقریباً بیشتر کارها از طریق اسکرپیتهای پایتون انجام میشود، در نتیجه در انتظار رابط گرافیکی قدرتمندی در این زمینه نباشید. سازندگان این چارچوب برنامههای بلندمدتی برای این ابزار در نظر گرفتهاند و درسهای یادگیری منبعبازی را برای آن ارائه کرده و از عناصر طراحی جدید سازگار با پلتفرمهای مختلف و محاسبات بازگشتی استفاده میکنند.
mlpack 2
mlpack 2 کتابخانه یادگیری ماشینی گسترشپذیری است که با زبان سیپلاسپلاس در سال ۲۰۱۱ نوشته شده است. (شکل ۱۱) هدف از طراحی این کتابخانه سهولت استفاده و گسترشپذیری اعلام شده است. mlpack دسترسی به الگوریتمهای موجود را از طریق برنامههای ساده و اجرایی خط فرمان و کلاسهای سیپلاسپلاس امکانپذیر میسازد. این مکانیزم میتواند با راهحلهای یادگیری ماشینی عظیمتر ادغام شود. همچنین محققان و کاربران حرفهای میتوانند با استفاده از ماژولهای زبان سیپلاسپلاس بهراحتی تغییرات مورد نیاز خود را به طور داخلی در الگوریتمها پیادهسازی کنند. این رویکرد با هدف رقابت در برابر کتابخانههای یادگیری ماشینی بزرگتر در نظر گرفته شده است.
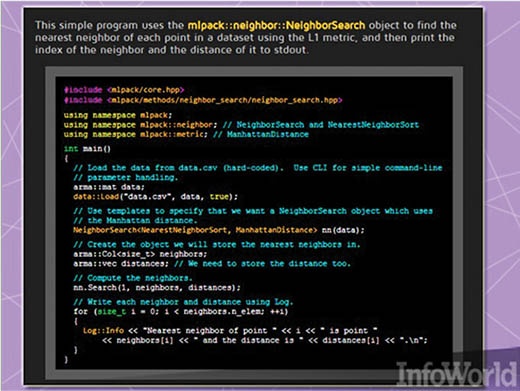
شکل ۱۱: نمایی از یک برنامه mlpack2
نسخه ۲ این محصول دارای تعداد زیادی ویژگی جدید و فاکتورگیری مجدد است. در نسخه جدید تعدادی الگوریتم تازه معرفی شده است و تعدادی از الگوریتمهای موجود با هدف افزایش سرعت و روانتر شدن دستخوش تغییراتی شدهاند. مقیدسازی نکردن به زبانهای مختلف از جمله معایب این کتابخانه هستند. کاربران زبانهای برنامهنویسی غیر سیپلاسپلاس، همچون R یا پایتون نمیتوانند از mplack استفاده کنند، مگر اینکه توسعهدهندهای پیدا شود تا این کتابخانه را برای زبان هدف آمادهسازی کند. برای مثال برای استفاده از این کتابخانه در R پروژهای به نام RcppMLPACK طراحی شده است. این کتابخانه بیشتر برای محیطهای بزرگی کاربرد دارد که یادگیری ماشینی راهکاری برای حل مشکلات آنها شناخته میشود.
Marvin
استیو جوروستون گفته است: «کلان دادهها دردسر بزرگی هستند و یادگیری عمیق کلید حل این دردسر بزرگ است.» اگر به تحولات دنیای صنعت و فناوری نگاهی بیندازیم، آنگاه به این حقیقت آگاه میشویم که هر ده سال یکبار تحولی عظیم در این زمینه رخ داده است. اگر دهه ۹۰ میلادی تا ابتدای سال ۲۰۰۰ میلادی دوران حکمفرمایی اینترنت بود، از سال ۲۰۰۰ تا سال ۲۰۱۰ امپراطوری تلفنهای هوشمند بر همه جا سیطره گسترانیده بود، از این سال به بعد دوران حکمرانی یادگیری ماشینی آغاز شده است. دورانی که تا سال ۲۰۲۰ ادامه خواهد داشت و زندگی مدرن ما را دستخوش تغییرات اساسی خواهد کرد. (شکل ۱۲) Marvin یکی دیگر از محصولات نسبتاً جدید این حوزه است. چارچوب شبکه عصبی ماروین، محصولی است که Princeton Vision Group آن را طراحی کرده است.
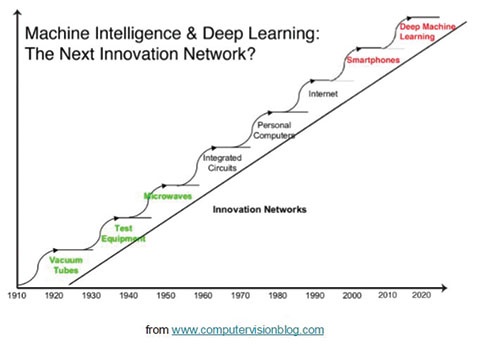
شکل ۱۲: سیر تحول فناوریهای از سال ۱۹۱۰ تا سال ۲۰۲۰
(شکل۱۳) این چارچوب با زبان سیپلاسپلاس نوشته شده و بر مبنای چارچوب پردازش گرافیکی کودا عمل میکند. با وجود حداقل کدها، ماروین همراه با تعدادی مدل ازپیشساختهشده و با قابلیت استفاده مجدد در اختیار کاربران قرار گرفته است و کاربران بر حسب نیاز خود قادر به سفارشیسازی آنها هستند.

شکل ۱۳: Marvin شبکه عصبی مناسب برای سختافزارهای نه چندان قدرتمند
این چارچوب در مقایسه با شبکههای عمیق عصبی مشابه همچون AlexNet، VGG، GoogLeNet سریعترین عملکرد را از خود نشان داده است. بهینهسازی برای مصرف کمتر پردازنده گرافیکی، پشتیبانی از پردازندههای گرافیکی چندگانه، فیلتر مجازیساز، پشتیبانی از پلتفرمهای مختلف همچون لینوکس، ویندوز و مک، پیادهسازی، اجرای سریع و نظایر اینها، از ویژگیهای این چارچوب هستند.
Neon
Nervana شرکتی است که پلتفرم سختافزاری و نرمافزاری خود را برای با یادگیری عمیق طراحی میکند. بر همین اساس این شرکت موفق شده است چارچوب یادگیری عمیقی به نام Neon را تولید کند. (شکل ۱۴) چارچوبی که در قالب یک پروژه منبعباز در اختیار کاربران قرار دارد. این چارچوب از ماژولهای ویژهای استفاده میکند که توانایی کار کردن با پردازشگر مرکزی، پردازشگر گرافیکی یا سختافزارهای سفارشی خاص این شرکت را دارد. بخش عمدهای از طراحی Neon با زبان پایتون انجام شده و تعداد دیگری از مؤلفههای آن با زبانهای سیپلاسپلاس و اسمبلی نوشته شدهاند. این زبانها به دو دلیل انتخاب شدهاند. اول آنکه سرعت محاسبات را افزایش دهند و دوم آنکه کاربران در بهکارگیری این چارچوب در زبانهای دیگری همچون پایتون مشکل خاصی نداشته باشند.
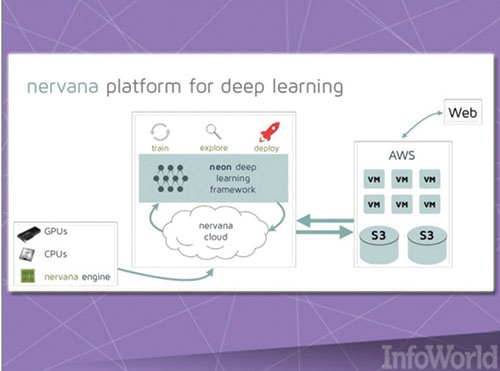
شکل ۱۴: نمایی از پلتفرم ارائهشده از سوی nervana درخصوص یادگیری عمیق
نئون در مقایسه با چارچوبهای دیگری همچون Caffe و Theano دوبرابر سریعتر است. از ویژگیهای اصلی نئون میتوان به بهینهسازی در سطح اسمبلر، پشتیبانی از پردازندههای گرافیکی چندگانه، بهینهسازی دادههای در حال بارگذاری و استفاده از الگوریتم وینوگراد برای محاسبات پیچیده اشاره کرد. در مجموع میتوانیم اینگونه بیان کنیم که نئون برای افراد تازهکار در حوزه یادگیری ماشینی گزینه ایدهآلی است. ترکیب نحوی شبیه به پایتون این چارچوب متشکل از پیادهسازی تمام اجزای مورد استفاده در یادگیری ماشینی همچون لایهها، قواعد یادگیری، فعالسازها، بهینهسازها، مقداردهندههای اولیه و مانند اینها است. بهرهمندی از مثالهای متنوع در ارتباط با تشخیص تصویر، گفتار، ویدیو و پردازش زبان طبیعی به عنوان مرجعی خوب و اولیه در اختیار کاربران قرار دارد.