
الگوریتمهای مختلفی در حوزه یادگیری ماشین و هوش مصنوعی در سالهای اخیر ایجاد یا بهبود یافته اند که برای هر فردی که قصد کار حرفه ای در این حوزه را دارد، آشنایی و تسلط بر آنها و مفاهیم پایه هر کدام و نیز استفاده از آنها در کاربردهای عملی، جزء ضروریات است . سایت مهندسی داده ، اخیراً شروع به نشر مقالاتی در توضیح این الگوریتم ها و نمونه کدهای پایتون و R برای هر کدام نموده است که در بخش اول این مجموعه از مقالات به بررسی دسته بندی کلی این الگوریتم ها پرداختیم و برای اینکه یک مرجعی از الگوریتم های لازم را برای علاقه مندان و محققین ایجاد کنیم ، تصمیم گرفتیم در بخش دوم این مجموعه، الگوریتمهای اصلی یادگیری ماشین را فهرست کنیم .
در سال ۲۰۰۷ یک مقاله با عنوان ده الگوریتم برتر حوزه داده کاوی در دنیا توسط دانشگاه ورمونت مطرح شد که نسخه فارسی شده (دانلود)و حتی آماده انتشار به صورت کتاب آنرا هم در ایران داریم .
این ده الگوریتم عبارتند از :
در سال ۲۰۱۱، در سایت پرسش و پاسخ معروف Qura در پاسخ به سوالی که ده الگوریتم برتر داده کاوی را پرسیده بود، موارد زیر توسط کاربران برشمرده شده اند :
- Kernel Density Estimation and Non-parametric Bayes Classifier
- K-Means
- Kernel Principal Components Analysis
- Linear Regression
- Neighbors (Nearest, Farthest, Range, k, Classification)
- Non-Negative Matrix Factorization
- Dimensionality Reduction
- Fast Singular Value Decomposition
- Decision Tree
- Bootstapped SVM
- Decision Tree
- Gaussian Processes
- Logistic Regression
- Logit Boost
- Model Tree
- Naïve Bayes
- Nearest Neighbors
- PLS
- Random Forest
- Ridge Regression
- Support Vector Machine
- Classification: logistic regression, naïve bayes, SVM, decision tree
- Regression: multiple regression, SVM
- Attribute importance: MDL
- Anomaly detection: one-class SVM
- Clustering: k-means, orthogonal partitioning
- Association: A Priori
- Feature extraction: NNMF
و در سال ۲۰۱۵ این لیست به صورت زیر در آمده است :
- Linear regression
- Logistic regression
- k-means
- SVMs
- Random Forests
- Matrix Factorization/SVD
- Gradient Boosted Decision Trees/Machines
- Naive Bayes
- Artificial Neural Networks
- For the last one I’d let you pick one of the following:
- Bayesian Networks
- Elastic Nets
- Any other clustering algo besides k-means
- LDA
- Conditional Random Fields
- HDPs or other Bayesian non-parametric model
سعی خواهیم کرد که تا چند ماه آتی ، تمامی این الگوریتم ها را با مثالها و نقاط ضعف و قوت و نیز نمونه کدهای لازم در این سایت بررسی کنیم.
فهرست کاملی از تمام منابع و آموزشها و الگوریتم های حوزه یادگیری ماشین را در این آدرس که به صورت مداوم در حال به روز شدن است هم می توانید مشاهده کنید.
پی نوشت :
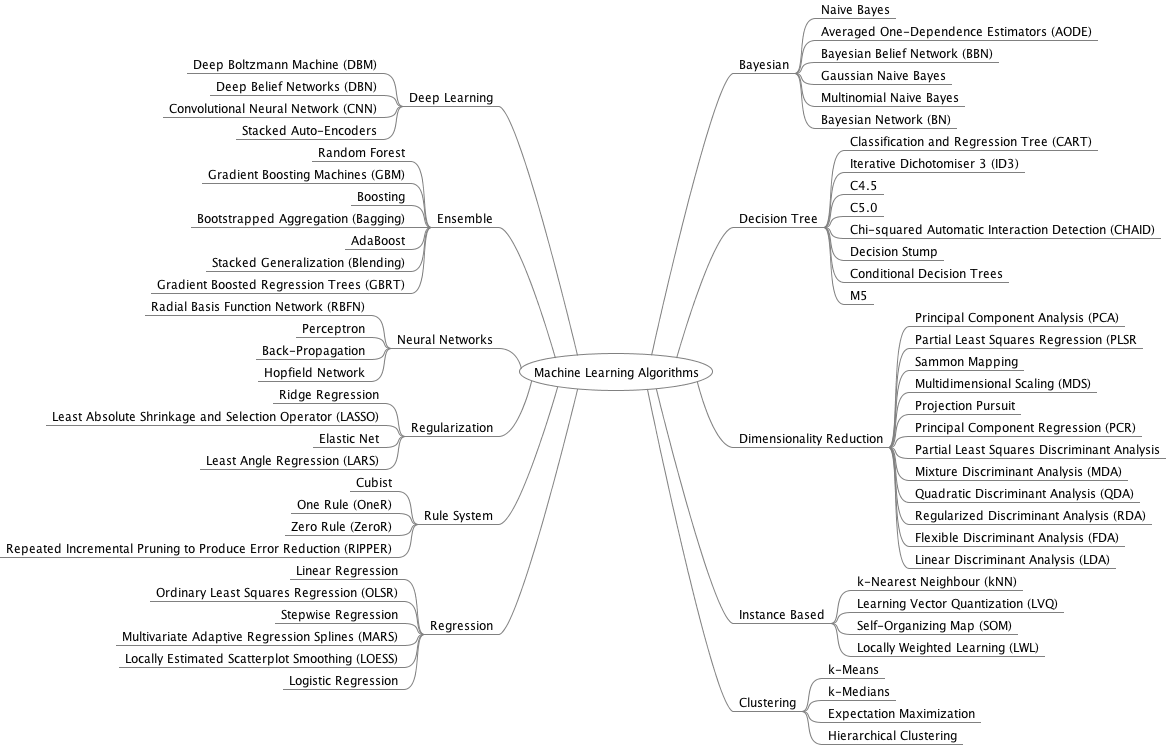
سایت DataFloq اخیراً یک طبقه بندی گرافیکی از الگوریتم های ضروری یادگیری ماشین ارائه کرده است که به صورت طبقه بندی شده ، این الگوریتم ها را فهرست کرده است :

این طبقه بندی را به صورت نقشه ذهن یا Mind Map هم می توانیم مشاهده کنیم :
مقاله خیلی خوبی بود
سلام
مقاله خوبی بود
واقعا ممونم بابت مطالب عالی سایتتون