
تحلیل اکتشافی داده ها در پایتون – بررسی داده های کشتی تایتانیک
مقدمه
اولین گام در یادگیری ماشین و مهندسی داده ، بررسی مجموعه داده های موجود و آشنایی با خواص مختلف آماری آنهاست که به نام تحلیل اکتشافی داده (این اینفوگرافیک را از دست ندهید)از آن یاد می کنیم. در بسیاری از موارد، این تحلیل اولیه، عملیات پیش پردازش داده را هم جهت می دهد و تعیین می کند کدام یک خواص [Featues] یا مشخصات داده ها باید حذف شوند و یا چه تبدیلاتی روی داده ها باید صورت گیرد تا آماده ورود به مراحل بعد و اعمال الگوریتم های مختلف یادگیری ماشین شویم.
مهندسی داده با هدف تعمیق بینش علاقه مندان به این حوزه با بیان مثالهای مختلف، این مراحل ابتدایی را با استفاده از زبانهای برنامه نویسی رایج از جمله پایتون و R به صورت عملی آموزش خواهد داد. برای شروع از بررسی داده های مسافران کشتی تایتانیک استفاده خواهیم کرد که یکی از مسابقات ابتدایی سایت معروف کگل برای ورود به بحث مسابقات پردازش داده است .
هدف از این مسابقه پردازش داده، بررسی داده های تعدادی از مسافرین، مثلا کلاس یا درجه بلیط ، جنسیت ، مکان سوار شدن و … ، پیش بینی این است که یک مسافر خاص زنده می ماند یا نه ؟ که یک مساله دسته بندی محسوب میشود. مشخصات مختلف داده ها را می توانید از این آدرس مشاهده کنید و فایل CSV حاوی داده های ۸۹۱ نفر از مسافرین که داده های آموزشی و اولیه ما را تشکیل می دهند هم از این آدرسقابل دانلود است .
نمونه کدها و کتابچه پایتون مربوطه را در گیت هاب قرارداده ام که توسط علاقه مندان به راحتی قابل دسترسی و استفاده باشد .
آماده سازی محیط کار
برای راحتی کار از محیط IPython برای اجرای کدها و نمایش نتایج استفاده خواهیم کرد که می توانید کتابچه پایتون مربوطه را از این آدرس مشاهده و دانلود کنید. این فایل را در همین پوشه ای که فایل پایتون یا کتابچه پایتون شما قرار گرفته است، با نام train.csv ذخیره کنید. کار را با اجرای IPython و خواندن داده ها و بارگذاری آنها به قالب جدولی با استفاده از کتابخانه pandas شروع می کنیم
ipython notebook –pylab=inline
import pandas as pd
import numpy as np
import matplotlib as plt
df = pd.read_csv("train.csv") #Reading the dataset in a dataframe using Pandas
نگاهی به داده ها
در اولین گام از فرآیند تحلیل اکتشافی ابتدا نگاهی به ده سطر اول مجموعه داده مسافران می اندازیم
df.head(10)
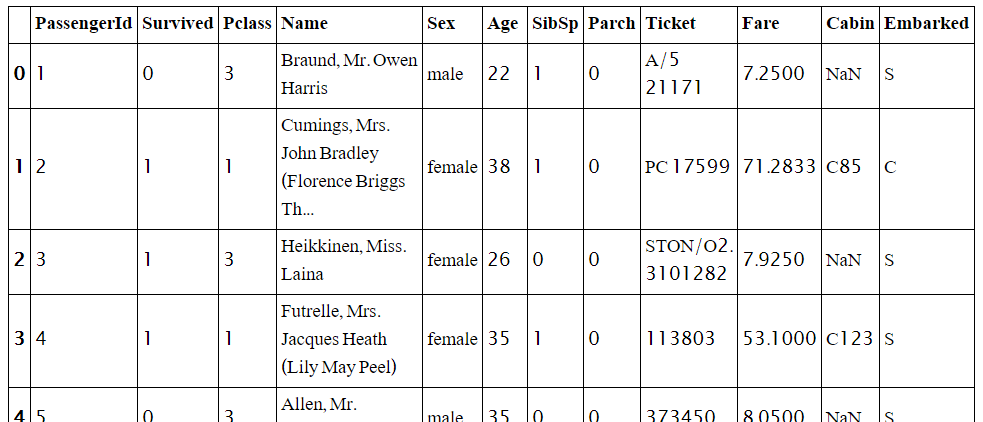
describe()
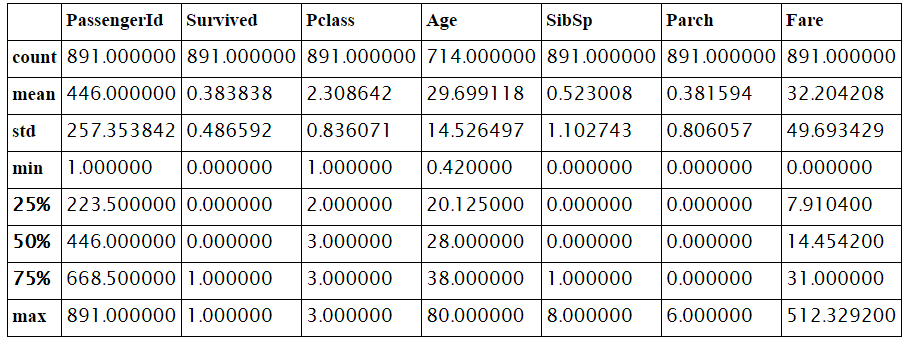
همانطور که مشاهده می کنید شماره مسافر و ستون وضعیت زنده ماندن شخص برابر با تعداد داده ها یا همان ۸۹۱ است. انحراف معیار و میانگین روی برخی فیلدهای عددی مانند شماره مسافر معنادار نیست که وظیفه تحلیل آن بر عهده شماست. با این وجود با نگاهی به جدول فوق نتایج زیر قابل استنتاج خواهند بود :
- تعداد ۲۷۷ نفر یعنی ۸۹۱-۷۱۴ نفر سنشان معلوم نیست .
- ۳۸% از مسافران زنده مانده اند. چون ستون Survived که عدد یک آن نشانگر زنده ماندن و عدد صفر آن نشان دهنده فوت شدن مسافر است، میانگینی برابر ۰٫۳۸ دارد که چون این میانگین جمع عددهای یک یعنی زنده ماندگان بر کل افراد بوده است پس نتیجه میگیریم که ۳۸ درصد افراد زنده مانده اند.
- با نگاه به چارک ها نتیجه می گیریم که بالای ۵۰ درصد افراد مسافر درجه سه بوده اند یعنی PClass آنها برابر ۳ است .
- سن افراد میانگین و انحراف معیار مناسبی دارد (میانگین ۲۹ و انحراف از معیار ۱۴) . همچنین تعداد برادران و خواهران (SibSp) و نیز تعداد فرزندان یا پدرومادر (Parch) هم توزیعی مطابق با انتظار دارد .
- عدد ۵۱۲ در ستون آخر با توجه به میانگین و توزیع چارک ها یک عدد انحرافی به نظر میرسد که شاید بهتر باشد از مجموعه داده ها حذف شود.
از طرفی روی هر ستون از داده ها به صورت جداگانه می توان توابع آماری مورد نیاز را اجرا کرد. مثلاً :
df['Age'].median()
میانه را برای ستون سن به ما می دهد. در مورد داده های غیر عددی مانند جنسیت یا بندری که مسافرین از طریق آن سوار کشتی شده اند (Embarked) نیز می توانیم با نگاه به مقادیر آنها تا حدودی با آنها آشنا شویم . تابع unique این کار را برای ما انجام می دهد :
df['Embarked'].unique()
همان طور که مشاهده می کنید برای بندر بارگیری ما سه مقدار S و C و Q را داریم و نیز مقدار nan که بیانگر نامعلوم بودن بندر بارگیری مسافر است .
بررسی توزیع های آماری
در ادامه نگاهی به توزیع داده ها در هر ستون می اندازیم که دید واقعی تری نسبت به داده ها به ما بدهد :
fig = plt.pyplot.figure()
ax = fig.add_subplot(111)
ax.hist(df['Age'], bins = 10, range = (df['Age'].min(),df['Age'].max()))
plt.pyplot.title('Age distribution')
plt.pyplot.xlabel('Age')
plt.pyplot.ylabel('Count of Passengers')
plt.pyplot.show()
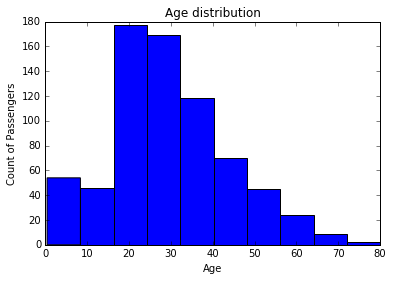
fig = plt.pyplot.figure()
ax = fig.add_subplot(111)
ax.hist(df['Fare'], bins = 10, range = (df['Fare'].min(),df['Fare'].max()))
plt.pyplot.title('Fare distribution')
plt.pyplot.xlabel('Fare')
plt.pyplot.ylabel('Count of Passengers')
plt.pyplot.show()
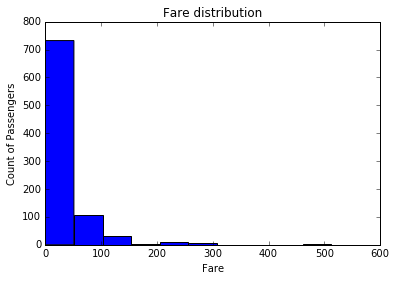
همانطور که نمودار های فوق مشخص است، میانگین سنی مسافرین حدود سی سال است که درست به نظر می رسد و کرایه پرداختی مسافرین نیز بیشتر به سطح مسافرین درجه سه (C class) یعنی قشر کم در آمد متمایل است.
نکته ای که درباره کد فوق نیاز به توضیح دارد، تابع add_subplot است که یک عدد سه رقمی را به عنوان ورودی گرفته است . این تابع برای ایجاد نمودارهای کنار هم به کار می رود و عدد اول تعداد نمودارها را در محور عمودی و عدد دوم تعداد نمودارها در محور افقی و عدد سوم شماره نمودار فعلی است . با این حساب عدد ۱۱۱ یعنی نمودار اول از یک مجموعه نمودار یک در یک . عدد ۱۲۲ یعنی نمودار دوم از بین یک در دو نمودار (به صورت ماتریسی از نمودارها در نظر بگیرید که عدد اول تعداد سطر و عدد دوم تعداد ستون و عدد سوم هم سلول فعلی از این ماتریس که قصد ترسیم آنرا داریم، نشان می دهد.)
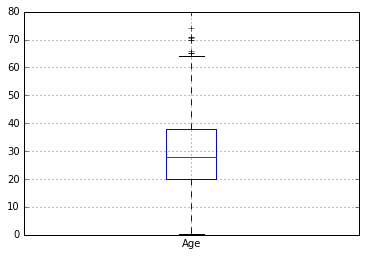
در مرحله بعد ، توزیع داده ها را با رسم نمودار جعبه ای بررسی می کنیم . این نمودار داده ها را به چهار بخش تقسیم می کند که بین چارک اول و چارک سوم یک مستطیل رسم می شود . یعنی مستطیل نیمی از داده ها را از لحاظ فراوانی در بر میگیرد و فضای ابتدای نمودار تا رسیدن به مستطیل ، یک چهارم اول داده ها و فضای انتهای نمودار که بعد از مستطیل قرار می گیرد ، یک چهارم آخر داده ها را نشان می دهد. خط میانی نمودار که بین مستطیل قرار می گیرد هم میانه یا وسط داده ها را نشان می دهد.
خط پررنگ ابتدای و انتهای نمودار هم کمینه و بیشینه داده ها را نشان میدهدو داده هایی که خارج از این بازه هستند به عنوان داده های پرت شناخته می شوند که باید بررسی شوند و به جای آنها مقدار مناسب (مثلا میانگین ) قرار بگیرد. توزیع کرایه ها (Fare) بسیار نامتقارن است و باید داده های این ستون از مسافرین حتماً بررسی و اصلاح گردد.
df.boxplot(column='Age',return_type='axes')
df.boxplot(column='Fare',return_type='axes')
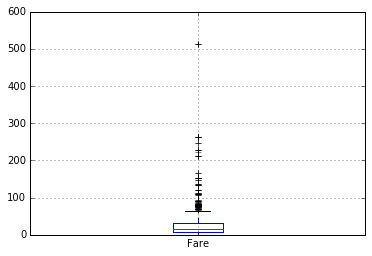
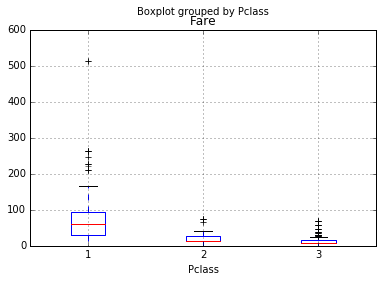
یک دلیل ناهماهنگی در داده های کرایه این است که همه مسافرین با هم مقایسه شده اند در صورتیکه مسافرین کشتی ، سه درجه مختلف دارند بنابراین باید هر گروه (کلاس) با خودش سنجیده شود. بنابراین بهتر است در رسم نمودار جعبه ای ، این گروه بندی ها را هم درنظر بگیریم :
df.boxplot(column='Fare', by = 'Pclass')
بررسی داده های غیر عددی
تا اینجا داده های عددی مسافرین را تا حدودی بررسی کردیم . حال به داده های غیر عددی و رشته ای می پردازیم . می خواهیم تاثیر درجه بلیط یک مسافر را در میزان زنده ماندن آنها بررسی کنیم. برای این منظور دو جدول داده موقت با فیلتر کردن جدول اصلی داده های مسافرین (df) ایجاد می کنیم و با ساخت دو نمودارِ کنار هم، نتایج را مشاهده می کنیم :
temp1 = df.groupby('Pclass').Survived.count()
temp2 = df.groupby('Pclass').Survived.sum()/df.groupby('Pclass').Survived.count()
fig = plt.pyplot.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Pclass')
ax1.set_ylabel('Count of Passengers')
ax1.set_title("Passengers by Pclass")
temp1.plot(kind='bar')
ax2 = fig.add_subplot(122)
temp2.plot(kind = 'bar')
ax2.set_xlabel('Pclass')
ax2.set_ylabel('Probability of Survival')
ax2.set_title("Probability of survival by class")
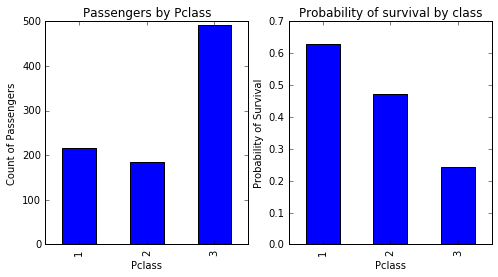
همانطور که از نمودار فوق مشاهده می شود، درصد بیشتری از مسافرین با درجه یک زنده مانده اند که البته طبیعی به نظر میرسد چون مسافرین ثروتمند از امکانات نجات بیشتری استفاده کرده اند.
بعد از این مرحله می خواهیم تاثیر جنسیت را هم در نجات مسافرین بررسی کنیم . برای این منظور از ساخت جدول کراس تب استفاده می کنیم و روی این جدول آماری ایجاد شده، نمودار مورد نیاز خود را رسم می کنیم به گونه ای که برای محور افقی آن ترکیب جنسیت و کلاس و برای محور عمودی هم زنده ماندن افراد نمایش داده شود .نتیجه را در زیر می بینید .
همانطور که از این نمودار هم مشخص است میزان زنده ماندن خانمها از آقایان بیشتر است و تقریبا همه خانمهای مسافر درجه یک هم نجات پیدا کرده اند ….
temp3 = pd.crosstab([df.Pclass, df.Sex], df.Survived.astype(bool)) temp3.plot(kind='bar', stacked=True, color=['red','blue'], grid=False)
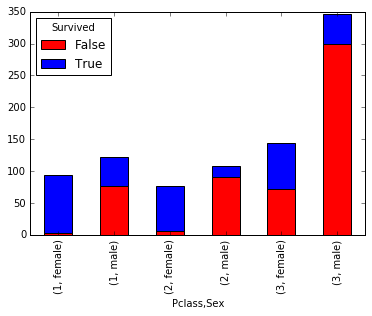
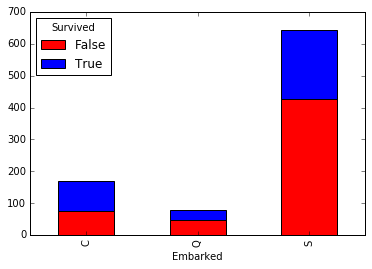
می توانیم بندر بارگیری مسافران را هم به این صورت تحلیل کنیم که متوجه میشویم مسافرینی که در بندر C سوار شده اند شانس بیشتری برای زنده ماندن داشته اند که البته شاید به خاطر درجه بلیط آنها بوده است .
temp3 = pd.crosstab(df.Embarked, df.Survived.astype(bool)) temp3.plot(kind='bar', stacked=True, color=['red','blue'], grid=False)
سخن پایانی
در این نوشتار الفبای پردازش داده با پایتون را بررسی کردیم و بدون وارد شدن به بسیاری از جزییات ، وارد حیطه جذاب و کاربردی مصورسازی داده ها شدیم . حوزه ای که تخصص آن به ممارست و تمرین نیاز دارد و گام مهمی در پردازش داده هاست . در آموزشهای بعدی به پیش پردازش داده ها خواهیم پرداخت …..
با سلام. من می خواستم همین تحلیل رو روی یه رقابت دیگه انجام بدم ولی نمیدونم چطوری و کجا train.csv رو قرار دهم. میشه راهنمایی بفرمایید