
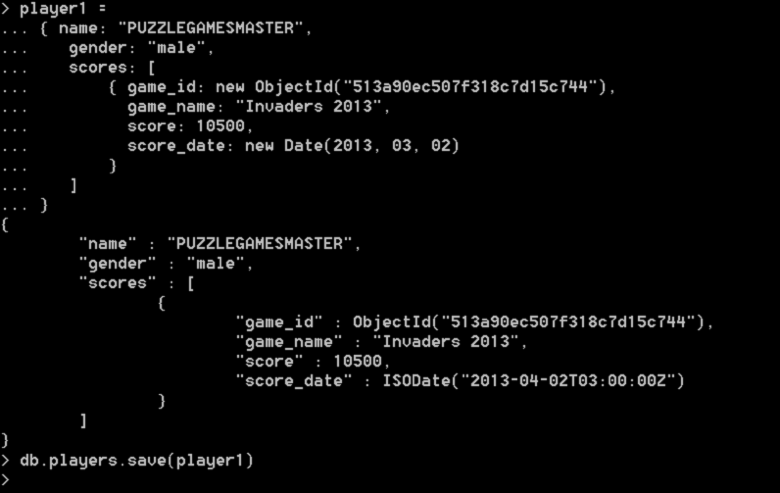
اما برای آنکه این مجموعه کامل شود، ما نیاز به بازیکنانی داریم که امتیازاتی را ثبت کنند. برای اضافهکردن مجموعه players به دیتابیس retrogames و همچنین افزودن یک سندگرا جدید به این مجموعه، تنها کافی است تا دستورات زیر در پوسته MongoDB اجرا شوند تا ضمن اضافه شدن سندگرا جدید، شناسه خودکاری برای این بازیکن نیز ایجاد شود. تنها نکتهای که باید به آن توجه داشت آن است که برای متصلکردن بازیکن به بازی لازم است تا فیلد اطلاعاتی game_id در سندگرا player1 با شناسه تولید شده برای سندگرا game1 جایگزین شود:
خروجی اجرای این دستور را در شکل زیر میبینید.
از آنجا که بازیکنی وجود دارد که امتیازی را برای بازی Invaders 2013 به ثبت رسانیده است، دستور زیر، مقدار فیلد اطلاعاتی played را به مقدار true بهروزرسانی میکند. در واقع در MongoDB برای بهروزرسانی هر سندگرا از دستور ()db.games.update استفاده میشود که در آن، پارامتر نخست شرط جستوجو را مشخص کرده و پارامتر دوم که با اپراتور set$ مشخص میشود، مقدار مورد نظر برای بهروزرسانی را مشخص میکند. بهعنوان مثال در دستور زیر، مدیر پایگاه داده، بازی با شناسه منحصربهفرد “۵۱e10c50085977bc3cd92a65” که همان شناسه سندگرا game1 است را یافته و مقدار فیلد اطلاعاتی played آن را با مقدار true بهروزرسانی میکند:
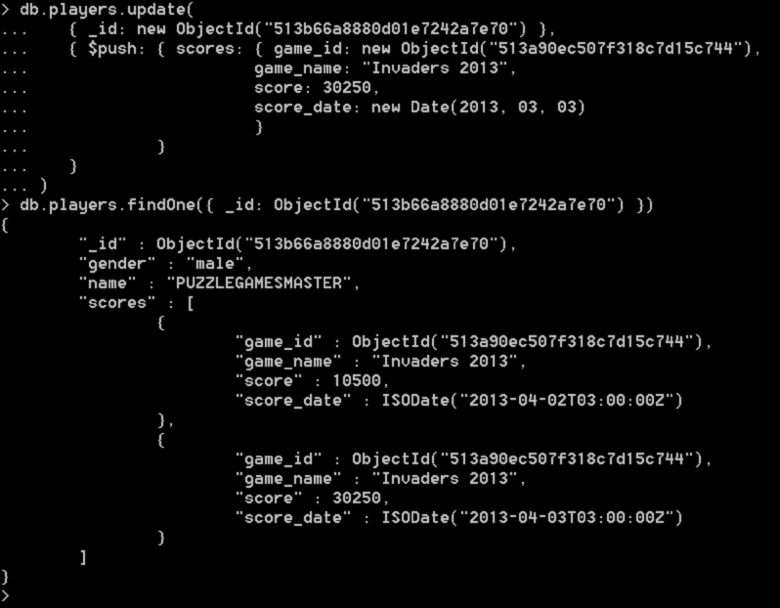
پرسشی که ممکن است به ذهن متبادر شود آن است که اگر همین player1 دوباره به انجام همین بازی پرداخت، چگونه اطلاعات جدید باید به مجموعه players افزوده شود. براساس آنچه در طراحی شمای retorogames در بخشهای پیش به آن پرداختیم، فیلد score در سندگرا player1، در واقع آرایهای از امتیازات خواهد بود و درنتیجه در این طراحی، افزودن امتیاز جدید به معنای بهروزرسانی، فیلد اطلاعات score برای player1 است. فرآیندی که با اجرای دستور زیر در پوسته MongoDB محقق خواهد شد:
اما در این دستور اشاره به چند نکته حایز اهمیت است. همانطور که مشخص است، این یک دستور بهروزرسانی است که پارامتر اول، شناسه سندگرا مورد نظر برای بهروزرسانی را مشخص میکند که شناسه تولید شده توسط دیتابیس برای player1 بوده و گزینه دوم، اپراتور $push است که برای افزودن یک المان جدید به آرایه score مورد استفاده قرار گرفته است. بهزبان سادهتر این دستور بیان میکند که باید المان جدیدی به فیلد اطلاعاتی score – که خود ساختار آرایهای دارد – متعلق به شناسه player1 در مجموعه players افزوده شود. خروجی حاصل از اجرای این دستور در شکل۱۰ نشان داده شده است.
اما بهجز اپراتور $push ، شما میتوانید از اپراتور دیگری بهنام $addToSet نیز استفاده کنید. تفاوت این اپراتور با اپراتور استفاده شده در دستور بالا، آن است که $addToSet در زمان افزودن یک المان جدید به آرایه فعلی، وجود المان تکراری را بررسی کرده و در صورت وجود از ورود آن به فیلد خودداری میکند. در اینجا و با توجه به این موضوع که ممکن است یک بازیکن، بارها یک بازی خاص را انجام داده و امتیاز یکسانی بهدست آورد، استفاده از push$ گزینه بهتری خواهد بود.
همچنین شما خواهید توانست با استفاده از دستور زیر، سندگرا مربوط به player1 با نام PUZZLEGAMESMASTER را از مجموعه players واکشی کرده و اطلاعات آنرا مشاهده کنید. خروجی حاصل از این دستور در فهرست۳ قابل مشاهده است:
همانطور که در خروجی بالا نیز مشاهده میشود، فیلد اطلاعاتی score بازیکن player1 ، تبدیل به آرایهای از امتیازات شده است. نیازی به توضیح نیست که با ادامه یافتن این فرآیند و انجام بازی توسط این بازیکن، این فیلد اطلاعاتی شامل سایر اطلاعات بازیهای خود نیز خواهد شد.
در مقالههای بعدی، سعی خواهیم کرد تا ضمن معرفی برخی ابزارهای گرافیکی برای کار با پایگاه داده MongoDB ، نحوه ایندکسگذاری روی دادهها برای جلوگیری از جستوجوی کامل در زمان پرسوجوها را معرفی کرده و چگونکی کار با مجموعهها در برنامههای کاربردی نوشته شده با زبان #C را مورد تحلیل و کاوش قرار دهیم.
مدلسازی دادهها در مانگودیبی
برای افرادی که از دنیای بانکهای اطلاعاتی رابطهای به دنیای مانگو مهاجرت کردهاند، توصیه میکنیم که مقاله مدلسازی داده در مانگو را هم به دقت مطالعه کنند.
دست به کد : تمرین عملی با مانگودیبی
در این نوشتار به بررسی یک مثال کاربردی با مانگودی بی می پردازیم و با دستورات اصلی و پیشرفته مانگو بخصوص توابع تجمعی (استخراج آمار و اطلاعات) آشنا می شویم.
با سلام
ممنونم بابت تمام پست های مربوط به بحث مانگو…
خیلی خوب و مفید بود.
با سلام
بسیار ممنونم بابت مطلب جامع و کاربردی که در زمینه مانگو منتشر کردید. من تجربه کار با پایگاه داده های غیر رابطه ای رو نداشتم ولی اخیرا پروژه ای بهم پیشنهاد شده که در آن مجبورم تقریبا هر ۵ دقیقه یکبار حدود ۱۰۰۰ تا فایل اکسل رو که از نظر ساختار شبیه هم نبوده ولی فیلدهایی دارند که در تمامی آنها مشترک هستند رو خونده و در پایگاه داده ذخیره کرده و در نهایت بتونم براساس فیلدهای مشترک روی همه اونها در بازه های زمانی مختلف کوئری بزنم. راستش دارم تحقیق می کنم ببینم چه نوع پایگاه داده ای همچین قابلیتی رو بهتر بهم میده.
به نظر شما مانگو جوابگوی این مدل داده ها هست؟
ممنون میشم اگر در این زمینه بهم کمک کنید.
با تشکر
سلام بنیامین عزیز …
خوشحالم که مطالب سایت براتون مفید بوده .
اگر هر پنج دقیقه یک بار قراره داده های غیرهمگنی به تعداد هزار فایل را در درازمدت بخونید، توصیه بنده استفاده از الاستیک سرچه که همه جور کوئری را با سرعتی بسیار بالا جواب میده. فرمت ذخیره اون هم جی سان هستش و مقیاس پذیری عالی ای داره .
موفق باشید .
سلام
برنامه ای دارم که در آن با ید درهر ۳۰ ثانیه باید مختصات ۲۰۰۰۰ نقطه را روی نقشه نگهداری نماید و در صورت نیاز مختصات بک نقطه را که میدهم باید آبجکتهای نزدیک به آن نقطه را تا فاصله ۵ کیلومتری روی نقشه به من نشان دهد از چه دیتابیسی استفاده کنم بهتره ؟
مهندسی داده :
برای کار با داده های جی آی اس ، از PostGIS استفاده کنید که هم مجموعه قابلیتهای کاملی در حوزه داده های جغرافیایی و مکانی داره و هم از دیتابیس قدرتمند پستگرس استفاده می کند.
کاش توضیحی راجع به نسخه های مختلف مثل community یا enterprise می دادید؟
درود بر سعید عزیز .
توی سایت خود مانگو و در بخش دانلود، تفاوت های این دو نسخه یعنی نسخه سازمانی و نسخه رایگان ذکر شده . اگر توی مطالب اون بخش، مشکلی داشتید بفرمایید تا توضیح داده بشه .
موفق باشید .
من این پیام رو بعد از پیغام “waiting for connections on port 27017” دارم لطفا راهنمایی کنید:
A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond. 127.0.0.1:55824
ممنون از مطلب آموزنده و خوبتون لطفا سری هم به سایت ما بزنید