
برخی مفاهیم پایه
امروزه اغلب سیستمهای مدیریت پایگاههای داده رابطهای، محیط دستوری را برای اجرای دستورات SQL و مشاهده نتایج در همان محیط را فراهم میآورند. پایگاه داده MongoDB نیز اگرچه جزء پایگاههای داده رابطهای نیست اما برای کاربران خود، یک ابزار تعاملی مبتنیبر جاواسکریپت فراهم میآورد که از تکمیل خودکار دستورات با استفاده از Tab نیز پشتیبانی میکند. این ابزار را میتوانید با اجرای دستور mongo.exe در مسیر نصب مانگو در حالت آماده بهکار قرار دهید (کافی است به پوشه Bin در محل نصب مانگو رفته ، کلید شیفت را نگه دارید و با کلیک راست، گزینه Open PowerShell Window here را بزنید و سپس دستور .\mongo.exe را اجرا کنید ).
اما شاید بد نباشد پیش از آنکه ساخت برنامهای کاربردی را آغاز کنیم که به تعامل با پایگاه داده MongoDB بپردازد، اندکی بیشتر به بررسی این پایگاه داده غیررابطهای بپردازیم تا با نحوه کارکرد آن بیش از پیش آشنا شویم. آشنایی که در قسمتهای بعد و در زمانی که قصد استفاده از زبان برنامهنویسی #C برای تعامل با این پایگاه داده را داریم، بهکار خواهد آمد. از آنجا که پوسته ارتباطی MongoDB، یک مفسر جاوااسکریپتی است، شما قادر خواهید بود تا اعمال پیچیدهای را توسط آن به انجام برسانید. بهعنوان مثال، شما میتوانید بهسادگی و با بهکارگیری یک حلقه چرخشی for – با استفاده از همان قواعد گرامری جاوااسکریپت – نسبت به واردکردن دادههای آزمایشی به یک پایگاه داده اقدام کنید. این رویکرد را میتوان یکی از برتریهای این پایگاه داده دانست، چراکه جاوااسکریپت جزء آندسته از زبانهایی است که بهدلیل محبوبیت آن در لایه نمایش، بهنوعی از زبانهای پایه این حوزه محسوب میشود و کمتر توسعهدهندهای است که با آن آشنایی نداشته باشد. موضوعی که شاید چندان درمورد SQL صادق نیست.
اما بگذارید کمی به ساختار دادهای MongoDB بپردازیم. این پایگاه داده همانطور که پیشتر نیز مطرح شد، یک ساختار ذخیرهسازی سندگرا است که از قالب BSON (مخفف JSON باینری) برای نمایش سندهاسندها خود بهره میبرد. قالب BSON از سوی دیگر، همان قالب JSON است که بهصورت باینری کدگذاری شده و علاوهبر تمامی توانمندیها و کارکردهای قالب JSON، ویژگیهای منحصربهفرد دیگری مانند انواع دادهای بیشتر، از جمله Date و داده باینری (BinData) که جزء مشخصات JSON نبوده اما برای کارکرد MongoDB از اهمیت بالایی برخوردار هستند را در خود دارد. ذکر این نکته ضروری است که BinData در واقع معادل نوع داده BLOB در پایگاههای داده رابطهای است که برای ذخیرهسازی محتوای فایلها درون پایگاه دادهها مورد استفاده قرار میگیرد. برای کسب اطلاعات بیشتر در مورد قالب BSON میتوانید به سایت اختصاصی این قالب به اين آدرس مراجعه کنید. هر سند در پایگاه داده MongoDB مجموعهای از جفتهای فیلد، مقدار است که مقدارها میتواند یکی از انواع زیر باشد:
• یک نوع BSON
• یک سند
• آرایهای از هرنوع BSON
• آرایهای از سند
بنابراین، در این پایگاه داده این امکان وجود دارد که یک سند (در شرایطی که مقدار یک فیلد اطلاعاتی خود یک سند یا آرایهای از سندها است) خود شامل سندهای دیگری باشد. این سندهای درونی بسیار قدرتمند بوده و در عین حال، انعطاف فراوانی را برای شِماهای آن با خود بههمراه دارند که البته، باید با دقت فراوانی مورد استفاده قرار گیرند. چراکه حداکثر اندازه یک سند (بدون استفاده از یک واسط خاص برنامهسازی به نام GridFS) شانزده مگابایت است.
نکتهای که باید در اینجا به آن اشاره کرد، آن است که پایگاه داده MongoDB با مجموعهها یا Collections کار میکند که معادل جدولها در پایگاههای داده رابطهای بوده و سند، معادلی برای رکوردهای جدولها در این رده از پایگاه است. بهعبارت دیگر هر پایگاه داده MongoDB، متشکل از مجموعههایی است که هر مجموعه خود شامل سندهایی – رکوردها – هستند که همانطور که در بخش قبل به آن اشاره شد، هر یک از این سندها میتوانند خود مجموعهای از سندها را در خود جای دهند.
از آنجا که هر سند متشکل از یک جفت فیلد اطلاعاتی و مقدار متناظر با آن است، نام مناسب برای شناسایی ویژگی هر سند بهطور مشخص نام فیلد است که درواقع معادل نام ستون است که در پایگاههای داده رابطهای مورد استفاده قرار میگیرد. همچنین هر سندگرا، شامل یک کلید اصلی است که بهصورت خودکار به فیلد id – تخصیص داده میشود.
نکته حائز اهمیت درمورد مجموعهها در پایگاه داده غیر رابطهای MongoDB آن است که اگرچه مجموعهها، بهنوعی با مفهوم جدولها هم ارز هستند که سندها را در خود جای میدهند، اما واقعیت آن است که این مجموعهها هیچ ساختاری را بر سندها تحمیل نمیکنند و این بزرگترین تفاوت این رده از پایگاههای داده با انواع رابطهای آن است. بهعبارت دیگر، برخلاف جدولهای پایگاههای رابطهای که هر رکورد آن، ستونهای یکسانی دارند، سندگراات موجود در یک مجموعه، میتوانند ساختارهای – فیلدهای اطلاعاتی – کاملاً متفاوتی داشته باشند. اگرچه در کاربردهای روزانه، سندهای موجود در یک مجموعه، معمولاً ساختار پایهای مشترکی دارند.
بنابراین، بهطور خلاصه، میتوان ساختار پایگاه دادهای MongoDB را متشکل از مجموعههایی دانست که هر مجموعه شامل سندهایی است و هر سند، معرف یک زوج فیلد اطلاعاتی و مقدار فیلد است که مقدار میتواند یکی از مقادیر مطرح شده در بخشهای قبل را در خود جای داده و ساختار سندگراات تو در تو را فراهم آورد. هر سند با نام فیلد آن شناخته شده و کلید اصلی آن بهصورت خودکار تخصیص داده میشود. (یک شناسه شئ یا Object ID)
بازطراحی یک شِمای رابطهای برای ساخت یک شمای سندگرا
زمانی که قصد استفاده از پایگاه داده MongoDB را داشته باشید، نیازی به طراحی دوباره یک شِمای ساختاریافته وجود ندارد. درواقع در این پایگاه داده، هر سند میتواند در زمان نیاز اطلاعات جدیدی را اضافه کند. اما با این وجود شما برای شروع نیاز به یک طرح و نیازمندیهای اولیه برای مجموعههای متفاوت مورد نیاز در پایگاه داده خود خواهید داشت. واقعیت آن است که یکی از بهترین روشهای درک نحوه کارکرد MongoDB استفاده از یک طراحی رابطهای و بازطراحی آن با استفاده از ویژگیهای اختصاصی موجود در این پایگاه داده است. با این روش، شما به سرعت تفاوتهای میان آنچه میدانید (پایگاه رابطهای) و آنچه در حال آشنا شدن با آن هستید (پایگاه سندگرا) را دریافته و بهاحتمال فراوان فاز انتقال دیدگاه را با موفقیت پشت سر خواهید گذاشت. برای این منظور ما یک طراحی ساده از یک پایگاه داده مختص بازیهای آنلاین را مد نظر قرار میدهیم. این شِما، موجودیتهای-جدولهای- شکل زیر را شامل میشوند.
• بازی (Game)
• گروه بازی (GameCategory)
• جنسیت (Gender)
• بازیکن (Player)
• امتیاز بازیکن (PlayerScore)
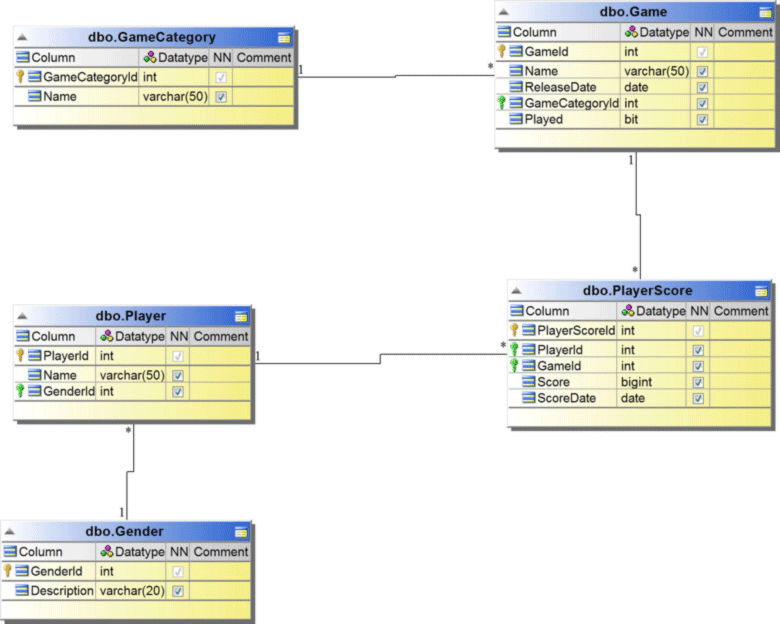
این شِما نشان میدهد که بازیها هر یک در گروهی قرار میگیرند. بازیکنان هر یک جنسیتی دارند و پس از پایان یافتن هر بازی توسط بازیکن، امتیاز آن بازی برای بازیکن مذکور در جدول امتیاز بازیکن ثبت میشود. حالا فرض کنید که صدها هزار بازیکن روزانه به این سایت سر زده و پس از انجام بازی، امتیازات خود را برای ثبت در جدول امتیازها ارسال میکنند. اگر این سایت بازی به هردلیلی، مثلاً علاقه یکی از هنرپیشگان یا ستارههای موسیقی به آن محبوب شود، در مدت زمان کوتاهی حجم اطلاعات آن به چند پتابایت خواهد رسید. در چنین شرایطی، مقیاسکردن این پایگاه داده و اجرای پرسوجوهایی با مجموعهای از توابع مجتمعساز (Aggregate functions) و ترکیب جدولها (joins) با یکدیگر میتواند به مشکلی بسیار جدی تبدیل شود.
اما اوضاع در یک پایگاه سندگراگرا به چه شکل خواهد بود؟ یک شِمای سندگراگرا که بازیکنان و امتیازات ایشان را نگهداری میکند، برای راهاندازی نیاز به یک تصمیم از سوی طراح دارد. چراکه پایگاه داده MongoDB دو گزینه برای طراحی دراختیار طراح قرار میدهد:
• داخلی: ساخت یک مجموعه به نام بازیکنان و نگهداری امتیازات هر بازیکن درون سندگرا متناظر با وی.
• ارجاعی: ساخت دو مجموعه یکی برای بازیکنان و دیگری برای امتیازات. هر امتیاز، کلید اصلی به بازیکنی که آن امتیاز را بهدست آورده است را نگاه میدارد. (روش مشابه طراحی رابطهای)
از آنجا که اشیای فرزند (امتیازها) همواره در سایه والد خود (بازیکنان) پدیدار شده و بهعبارتی و با ادبیات پایگاههای داده رابطهای، موجودیت ضعیف بهشمار میآیند، ما در اینجا از گزینه نخست یعنی داخلی استفاده میکنیم. البته، ذکر این نکته ضروری است که استفاده از راهحل نخست مشکلاتی را با خود بههمراه خواهد داشت که در ادامه مطلب و در زمانی که قصد بهروزرسانی این شِما را داشته باشیم، به آن خواهیم پرداخت. در واقع ما درابتدا روش داخلی را برگزیدیم تا با اشکالات معمولی که در روش سندگراات داخلی، وجود دارد بهعنوان کسی که در ابتدای کار با این پایگاه داده است آشنا شویم.
اجازه دهید به ادامه بحث بازگردیم. در کاربرد تعریف شده – سایت بازی – امتیازات، جزء اطلاعات بازیکن بهشمار خواهد رفت. بنابراین، اینگونه بهنظر میآید که بهترین راه برای نگهداری آنها، داخلی یا درونیسازی آنها در مجموعه بازیکنان و در قالب سندگرا هر بازیکن باشد. حال اگر، بخواهیم برای افزودن جذابیت و ایجاد انگیزه در میان بازیکنان، فارغ از آنکه چه بازیکنی برترین امتیازات را کسب کرده است، تنها برترین امتیازات هر بازی را بهنمایش بگذاریم، آنگاه گزینه ارجاعی، یعنی ساخت دو مجموعه مجزا و ایجاد ارجاع میان آنها، گزینه بسیار بهتری خواهد بود و همچنین هرگز نباید محدودیت ۱۶ مگابایت برای سندگراات را فراموش کرد. چراکه این محدودیت در زمانی که یک بازیکن حجم انبوهی از امتیازات را ثبت کند، مشکلساز خواهد بود.
در ساختار رابطهای، هر بازی با یک و تنها یک «گروه بازی» در ارتباط است. به گروهها میتوان به چشم نمایهها (tags) نگاه کرد که با هدف فیلترکردن و دستهبندی بازیها در کنار یکدیگر بهکار گرفته میشوند. اما واقعیت آن است که یک بازی میتواند به چند گروه مختلف تعلق داشته باشد. برای مثال، بازیهای زیادی هستند که در عین قرار داشتن در گروه بازیهای اکشن، فکری نیز هستند و در طی آن باید پازلهای مختلفی را نیز حل کرد. ما در اینجا و برای طراحی این ساختار در MongoDB میتوانیم از قابلیت ذخیرهسازی آرایهای از رشتهها در یک فیلد اطلاعاتی استفاده کنیم. برای این منظور ضروری است تا یک مجموعه بازی با فیلد اطلاعاتی گروه بازی ایجاد کنیم که مقدار آن میتواند آرایهای از رشتهها باشد. همانطور که پیشتر نیز به آن اشاره کردیم، طراحی وابسته به کاربرد خواهد بود. بهعنوان مثال، در شرایط دیگر ممکن است گزینه ساخت دو مجموعه بازی و گروه بازی و استفاده از روش ارجاعی گزینه بهتری برای طراحی باشد.
همچنین هر امتیاز متعلق به یک بازی بوده و شامل شناسه آن بازی (Object ID) خواهد بود. از آنجا که در این کاربرد نیاز داریم تا نام بازی را در کنار هر امتیاز نشان دهیم، بنابراین، گزینه داخلی را انتخاب کرده و نام هر بازی را جزء جزئیات امتیاز نگهداری میکنیم. با این تفاسیر، نخستین نسخه از پایگاه داده ما تنها شامل دو مجموعه یا Collection خواهد بود:
• بازیها (Games)
• بازیکنان (Players)
با اجرای خطوط زیر در پوسته MongoDB، این پایگاه داده، دیتابیس بازی را برای شما ساخته، مجموعه بازی را به این پایگاه داده جدید افزوده و یک سندگرا جدید با یک مقدار تولید شده خودکار برای فیلد id – درون آن ایجاد میکند.
کافی است این دستورات را در خط فرمان مانگو در پاورشل پیست کنید :
خروجی حاصل از اجرای این دستور در پوسته MongoDB در شکل۶ آمده است.
حال اگر به محیط Compass برگردید، میتوانید این سند درج شده را مشاهده کنید (آیکون رفرش را حتما بزنید )
اما مانند هر پایگاه داده دیگری، ذخیره بدون بازیابی هرگز ارزشی نخواهد داشت. پایگاه داده MongoDB مانند پایگاههای داده رابطهای دستورات خاص خود را برای بازیابی اطلاعات ذخیره شده دراختیار کاربران قرار داده است. برای مثال، شما میتوانید خروجی حاصل از اجرای دستور SELECT * FROM games در پایگاه رابطهای را با استفاده از اجرای دستور زیر در پوسته MongoDB بهدست آورید:
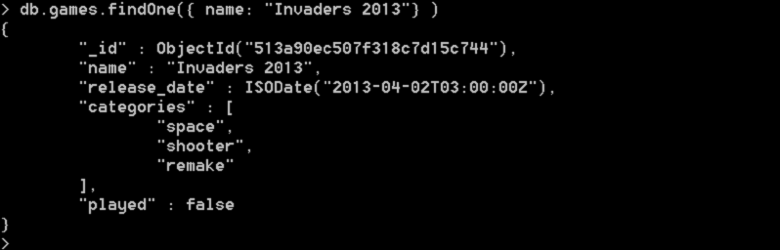
البته در همان خط فرمان هم با زدن دستور زیر می توانید این سند را مشاهده کنید ( دقت کنید که دستور use retrogamesکه در بالا استفاده کرده ایم، دیتابیس پیش فرض را به retrogames تغییر داده است و بنابراین db به این دیتابیس اشاره دارد)۰:
خروجی حاصل از این دستور در زیر قابل مشاهده است.. از آنجایی که این پایگاه داده تنها یک سندگرا را در خود جای داده است، خروجی تنها یک سندگرا را باز میگرداند. اما در شرایط واقعی، چنین مجموعهای میتواند شامل هزاران بازی – سندگرا – باشد که برای بازیابی آنها، نیاز به ابزاری برای محدود کردن سندگراهای واکشی شده خواهد بود. پوسته MongoDB برای این منظور از تابع () limit استفاده میکند.

بهعبارت دیگر شما میتوانید با استفاده از دستور زیر، صد سندگرا آخر وارد شده به مجموعه games را واکشی کنید:
این دستور معادل پرسوجوی TOP 100 * FROM games SELECT در SQL Server یا SELECT * FROM games Limit 100 در MySQL است. توجه کنید که در اینجا به دلیل وجود تنها یک سندگرا در مجموعه games خروجی db.games.find() و db.games.find().limit(100) یکسان شده است.
یکی دیگر از کاربردهای حیاتی در واکشی اطلاعات ذخیره شده در هر پایگاه دادهای، واکشی وابسته به یک فیلد است که در پرسوجوهای رابطهای با استفاده از گزاره WHERE محقق میشود. در MongoDB نیز این قابلیت فراهم است تا جستوجو و اکشی براساس یک فیلد اطلاعاتی خاص و با استفاده از دستور زیر انجام گیرد:
حال میتوانیم کمی جستجویمان را حرفه ای کنیم : (بخش داخل آکولاد را اگر نوار پرس و جوی Compass هم بنویسید نتیجه را به شما نشان خواهد داد )
با سلام
ممنونم بابت تمام پست های مربوط به بحث مانگو…
خیلی خوب و مفید بود.
با سلام
بسیار ممنونم بابت مطلب جامع و کاربردی که در زمینه مانگو منتشر کردید. من تجربه کار با پایگاه داده های غیر رابطه ای رو نداشتم ولی اخیرا پروژه ای بهم پیشنهاد شده که در آن مجبورم تقریبا هر ۵ دقیقه یکبار حدود ۱۰۰۰ تا فایل اکسل رو که از نظر ساختار شبیه هم نبوده ولی فیلدهایی دارند که در تمامی آنها مشترک هستند رو خونده و در پایگاه داده ذخیره کرده و در نهایت بتونم براساس فیلدهای مشترک روی همه اونها در بازه های زمانی مختلف کوئری بزنم. راستش دارم تحقیق می کنم ببینم چه نوع پایگاه داده ای همچین قابلیتی رو بهتر بهم میده.
به نظر شما مانگو جوابگوی این مدل داده ها هست؟
ممنون میشم اگر در این زمینه بهم کمک کنید.
با تشکر
سلام بنیامین عزیز …
خوشحالم که مطالب سایت براتون مفید بوده .
اگر هر پنج دقیقه یک بار قراره داده های غیرهمگنی به تعداد هزار فایل را در درازمدت بخونید، توصیه بنده استفاده از الاستیک سرچه که همه جور کوئری را با سرعتی بسیار بالا جواب میده. فرمت ذخیره اون هم جی سان هستش و مقیاس پذیری عالی ای داره .
موفق باشید .
سلام
برنامه ای دارم که در آن با ید درهر ۳۰ ثانیه باید مختصات ۲۰۰۰۰ نقطه را روی نقشه نگهداری نماید و در صورت نیاز مختصات بک نقطه را که میدهم باید آبجکتهای نزدیک به آن نقطه را تا فاصله ۵ کیلومتری روی نقشه به من نشان دهد از چه دیتابیسی استفاده کنم بهتره ؟
مهندسی داده :
برای کار با داده های جی آی اس ، از PostGIS استفاده کنید که هم مجموعه قابلیتهای کاملی در حوزه داده های جغرافیایی و مکانی داره و هم از دیتابیس قدرتمند پستگرس استفاده می کند.
کاش توضیحی راجع به نسخه های مختلف مثل community یا enterprise می دادید؟
درود بر سعید عزیز .
توی سایت خود مانگو و در بخش دانلود، تفاوت های این دو نسخه یعنی نسخه سازمانی و نسخه رایگان ذکر شده . اگر توی مطالب اون بخش، مشکلی داشتید بفرمایید تا توضیح داده بشه .
موفق باشید .
من این پیام رو بعد از پیغام “waiting for connections on port 27017” دارم لطفا راهنمایی کنید:
A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond. 127.0.0.1:55824
ممنون از مطلب آموزنده و خوبتون لطفا سری هم به سایت ما بزنید