

بانکهای اطلاعاتی شبه رابطه ای یا سطر گسترده
نمونهها : Riak , Amazon SimpleDB ,Accumulo ,Cassandra , Hadoop/Hbase
کاربردها : سیستمهاي فایلي معمول، ایندکس زنی دستی ، سریهای زمانی
نقاط قوت : جستوجو و بازیابی سریع، ذخیره توزیع یافته دادهها به روشی سودمند
نقاط ضعف : API سطح پایین که در حال بهبود است
توضیح: نقطه تولد و رشد این پایگاههاي داده، نیاز یکی از شبکههاي بزرگ اجتماعی به یک پایگاه داده سریع و ارزان برای مدیریت میلیونها به روزرسانی دادهاي از افراد مختلف بود. این شبکه اجتماعی بزرگ، ابتدا کار روی پایگاه دادهاي Cassandra را آغاز کرد و سپس آن را به بنیاد آپاچی سپرد تا مورد توسعه و پشتیبانی جامعه اپنسورس قرارگیرد. این پایگاه داده، که محصول شاخصی در رسته پایگاههاي دادهاي توزیع شده به شمار ميآید، ابزاری بسیار مناسب برای مدیریت حجم عظیمی از دادههاست که روی یک شبکه پیچیده از سرورهای متصل به هم ساخته ميشود و در آن هر ماشین دقیقاً حاوی دادههاي یکسان است. در چنین پایگاه دادهای، هر ماشین باید با دیگران یکی باشد و همچنين، همگی باید در شبکه P2P داخلی خود، عملکردی با ثبات ارائه كنند.
با این حال، ثبات در این پیکربندی، ثبات حتمی و صد درصد نیست و حالتی احتمالی و مشروط دارد. به همین دلیل در بعضی از موارد، دادههاي کاربران از روی شبکه اجتماعی مذکور به طورموقت ناپدید شده و دوباره باز میگردد. این پایگاه داده روی جاوا پیادهسازی شده و بهصورت یک پردازه جدا (که در انتظار ارتباطات است) کار ميکند. برای کار با کاساندرا، کتابخانههاي مناسبی به زبانهاي جاوا، پایتون، Ruby و PHP نیز توسعه داده شده و در اختیار کاربران است.
در گام نخست، کار با کاساندرا بسیار ساده به نظر ميرسد، اما به دلیل متفاوت بودن محیط مدلسازی دادهها با مدل سنتی رابطهای، توسعه دهنده در گامهاي نخست با سردرگمی مواجه خواهد شد. در ضمن، ذخیرهکردن دادهها در این پایگاه داده، در گامهاي نخست و در حجمهاي کم ممکن است بسیار کندتر از چیزی باشد که کاربر تصور ميکند زیرا در آن، تنها روتینهاي ساده برای ذخیرهسازی اجرا نمیشوند و موارد مختلف و پیچیده درونی دیگری نیز در ذخیره کلکسیونهاي دادهاي در کاساندرا نقش دارند. با این حال، کاساندرا با ذخیرهسازی دادههاي ماتریسی تُنُک رابطه بسیار خوبیدارد و در ذخیرهسازی سطرهايي که ستونهاي کمی دربر ميگیرند از خود عملکرد بسیار خوبی به نمایش گذاشته و شاخصهاي مربوط را بهصورت درونی برای دادهها تولید و نگهداری ميکند.
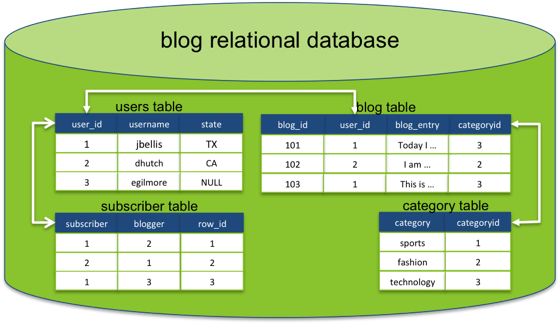 مدل رابطه ای یک سیستم وبلاگ
مدل رابطه ای یک سیستم وبلاگ
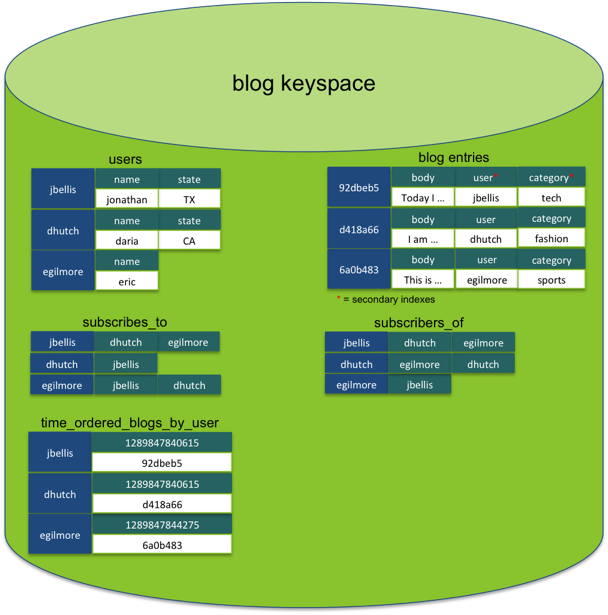
فضای نام وبلاگ در کاساندرا
در زمینه دستیابی به بهترین سرعت خواندن نیز کاربر باید به الگوهای خواندن که در کاربرد موردنظرش بیشتر اتفاق ميافتند، توجه ویژه داشته باشد و به بهترین نحو آن را تنظیم كند. درست است؛ پایگاههاي داده سنتی و رابطهای، این کارها را بهصورت خودکار انجام ميدهند، اما توجه کنید که سرعت اجرای آنها روي سخت افزار مشابه، از نمونه NoSQL خود که در اینجا کاساندرا است بسیار کمتر است و به این نکته نیز توجه داشته باشید که کاساندرا، در مراحل آغازین توسعه خود به سر ميبرد!
یکی دیگر از نمونههاي بسیار قوی در این نوع پایگاههاي داده، Riak است. ذخیره دادهها در این پایگاهداده، با حالتی بسیار پیچیدهتر از دیگر نمونهها انجام ميشود و علاوه بر اینکه بيشتر قابلیتهاي موجود در رقبا را ارائه ميكند، اما امکان کنترل نسخهبرداری از دادهها را نیز فراهم ميسازد. در این پایگاه داده، با اینکه ساختار کلی ذخیرهسازی در قالب جفتهاي کلید و مقدار هستند، اما گزینههاي بازیابی دادهها و تضمین ثبات کل سیستم بسیار غنی و پیشرفته است. به عنوان مثال، در Riak ميتوان از پایگاه داده خواست تا در هنگام نوشتن دادهها، نوشته شدن روی تعداد خاصی از ماشینها (۱، ۲، ۳ یا حتی ۵۴ ماشین) را تضمین کند و تا زمانی که این امر انجام نشده، پیغام انجام درست عملیات را بازنگرداند. به همین دلیل است که شعار تیم توسعه این پایگاه داده، این است: «ثبات مشروط و احتمالی، عذر مناسبی برای از دست دادن دادهها نیست!»
در زمینه بازیابی دادهها نیز Riak امکانات بسیار سودمندی را ارائه ميکند. کنترل خطا، برگرداندن تازهترین به روز رسانی از یک شيء در صورت برخورد با دو نسخه متفاوت از آن روی دو ماشین مختلف یا بازگرداندن هر دوی آنها به کلاینت و ارائه امکان تصمیمگیری به کد و سمت کلاینت از جمله این قابلیتهاي سودمند هستند. این پایگاه داده در دو نسخه اپن سورس و Enterprise ارائهميشود که تفاوت آنها در وجود رابط مدیریتی تحت وب و پشتیبانی از نقل و انتقالهاي دادهاي پرسرعت در دیتاسنترها در نسخه Enterprise است.
کاربرد نمونه: یک سایت خبری با انواع و اقسام محتواها مانند مقالهها، اظهارات کاربران، پروفایل نویسندگان، رأی افراد و… را در نظر بگیرید که قصد دارد تا میزان مناسب بودن مطالب خود را از روی رأی کاربران بسنجد و محتوای پرطرفدارتر را برای دیگر کاربران نمایش دهد. در این مجموعه، با استفاده از پایگاههاي داده توزیعشده و تولید کلیدهاي UUID یکتا، ميتوان یک انباره برای هر کاربر و یک انباره برای هر نوع محتوا ایجاد کرد. انباره کاربر رأیهايي را که هر کاربر ثبت ميکند، ذخیره کرده و انباره محتوا، یک کپی از رأی را که برای هر مطلب داده شده، ذخیره ميكند.
پس از جمعآوری دادهها، ميتوان عملیات پیوستهاي را اجرا کرد که محتواهایی که کاربران به آنها رأی دادهاند، شناسایی شود. برهمین اساس، ميتوان برای هرکاربری که رأی صادر کرده، فهرستي از محتواهایی را تولیدکرد که رأی بالایی دارند، اما آن کاربر رأیی برای آنها صادر نکرده است. با در اختیار گذاشتن فهرستهاي تولید شده به کاربران، محتوا بهشدت در مجموعه گسترش یافته و چرخه بهینهاي از تولید و انتشار دادهها در کل سایت و کاربران آن اتفاق خواهدافتاد. این مثال، نمونه چیزی است که در بسیاری از شبکههاي اجتماعی کنونی در حال اجرا است.
بانکهای اطلاعاتی گراف محور
نمونهها : OrientDB , FlockDB ,Titan ,InfiniteGraph , Neo4J
کاربردها : شبکههاي اجتماعی، سایتهاي پرسشو پاسخ
نقاط قوت : الگوریتمهاي گراف مانند کوتاهترین مسیر، میزان اتصال، روابط n درجهای
نقاط ضعف :نیاز به پیمایش کل گراف برای رسیدن به جواب، عدم امکان خوشهسازی آسان
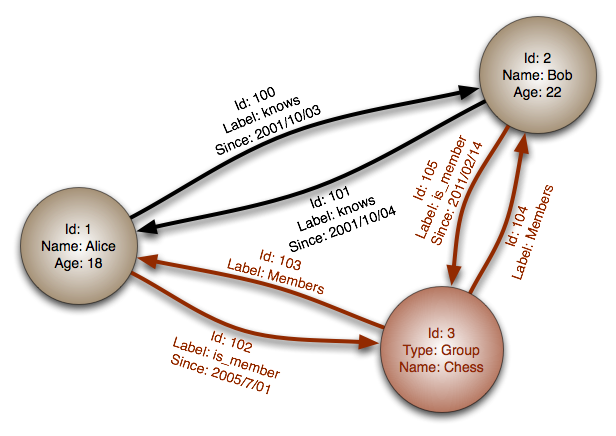
توضیح: معرفی این دسته را با پایگاهداده Neo4J که مهمترین نمونه موجود از این نوع پایگاههاي داده است آغاز میکنیم. فعالان توسعه این پایگاه داده، از کلمه گراف برای اشاره به شبکهاي از نودها و اتصالهاي بین آنها استفاده ميکنند. این پایگاه داده، امکان پرکردن انباره دادهاي با نودهاي مختلف و برقراری ارتباط میان آنها را برای ایجاد معانی یا اشیاء ایجاد ميكند.ساختارمذکور این پایگاه دادهاي را در کاربردهایی نظیر ایجاد شبکههاي اجتماعی سودمند ميسازد.
کد پایه این پایگاه داده با مجموعهاي از الگوریتمهاي محاسباتی مرتبط با گراف عرضه شده است که برای مثال، امکان تعیین کوتاهترین مسیر میان دو نفر را فراهم ميسازد. سایتهايي نظیر linkedin از چنین پایگاههاي دادهاياستفاده ميکنند. این پایگاهداده، یک نمونه بسیار جوان از این دسته است و هر روز یکی از قابلیتهاي مناسب آن توسط توسعهدهندگان و کاربران کشف ميشود. افزایش سرعت کارکرد با استفاده از قابلیتهاي Caching و تولید یک زبان پرسوجوی جدید شبیه XSL از جمله مواردی هستند که به تازگي به این مجموعه آیندهدار اضافه شدهاند. این پایگاهداده توسط Neo Technology توسعه داده ميشود و نسخه تجاری آن نیز با قابلیتهايينظیر مانیتورینگ پیچیده، مدیریت خطا و پشتیبانگیری قابل استفاده است.
با وجود عرضه مجموعههاي نرمافزاری شایسته، همیشه افرادی وجود دارند که به پیچیدگی کد اعتراض داشته و به فکر عرضه راهحلیسادهتر باشند. به همین دلیل، عدهاي از توسعهدهندگان دور هم جمع شدند و نتیجه کار آنها، تولد و معرفی پایگاه دادهاي FlockDB است که به مراتب سریعتر و سادهتر از Neo4J است. این پایگاه داده جزئی از هسته بزرگترین شبکه اجتماعی مایکروبلاگینگ نیز به شمار ميآيد که توسط این شبکه اجتماعی، چیزی حدود یک سال پیش عرضه شد. نكته جالب توجه اين که ميتوان با استفاده از Gizzard که ابزاری برای اشتراکگذاری دادهها روي نمونههاي مختلف FlockDB است، یک نمونه جدید از این سایت بزرگ را از نو ساخت.
با اینکه بسیاری FlockDB را نمونهاي از پایگاههاي دادهگرافی ميدانند، اما این پایگاه داده قابلیتهاي پیشرفتهتری نظیر اضافهکردن دادههاي جدید (از جمله دادههاي زمانی) به نودها و همچنین پرسوجوی عمیقتر را نیز ارائهميکند. در این حالت ميتوان دو نود را مشخص کرد که براساس آنها میزان دادههاي قابل استخراج، بر مبنای نیاز کاربر و با استفاده از پارامترهای کوئری انجام شده قابل تعیین است. تفاوت دیگر این پایگاه داده در مقابل Neo4J، عدم پشتیبانی از الگوریتمهاي گرافی است که بهصورت سرویس ارائه ميشوند و نشان از آن دارد که توسعهدهندگان علاقهچندانی به آنهانداشته و حذفشانکردهاند. کد پایگاه داده FlockDB بسیار جوان است و راه زیادی را تا رسیدن به بلوغ کامل در پیش دارد.
با مرور کد ارائه شده، به راحتی مشاهده میشود که تمام کدهای اعمال شده اخیر، توسط کارمندان توییترتهیه شدهاند. البته هنوز خدمات میزبانی FlockDB بهعنوان سرویس از طرف کسی ارائه نشده است. به همین دلیل، به نظر ميرسد این پروژه از توجه و محبوبیت ویژهاي در میان توسعهدهندگان برخوردار نیست و شاید به زمان بیشتری برای اثبات قابلیتهاي خود نیاز داشته باشد.
کاربرد نمونه: هر برنامه کاربردی که برای اهدافی چون شبکههاي اجتماعی توسعه داده ميشود، بهترین گزینه پایگاه داده آن یک پایگاه داده گرافی است. همچنين، هر برنامهاي که نیاز دارد از فعالیت کاربران مطلع شده و بايد بداند که چه ميخرند یا از چه چیزی لذت ميبرند تا اطلاعات مشابه و مورد علاقه آنها را برایشان فراهم کند، به راحتی ميتواند از چنین پایگاههاي دادهاي استفاده کنند. همچنین هرگاه یک برنامه به پاسخ پرسشی نظیر: «دوستان افرادی که سن آنها زیر ۴۰ سال است و از اسکی لذت ميبرند و به کنیا نیز مسافرت کردهاند، از چه رستورانهايي متنفرند؟» نیاز داشت، یکی از مناسبترین راهحلها، یک پایگاهداده گرافی است.
چگونه انتخاب کنیم؟
هیچ پاسخ ساده و کوتاهی برای این سؤال نمیتوان یافت. انتخاب بهترین پایگاهداده NoSQL برای یک توسعهدهنده ماهر، امری مهم و انتخابی برای ایجاد تعادل در میان استحکام پروژه، وجود پشتیبانی تجاری، کیفیت اسناد مرتبط و کیفیت کد به شمار ميآید. مهمترین تفاوت راهحلهاي موجود در این زمینه، مفاهیم اضافی موجود در آنها است. همه راهحلهاي مبتنی بر NoSQL موجود، در اصل، جفتهاي دادهاي را گرفته و ذخیره ميکنند و در صورت نیاز بر ميگردانند، اما پرسش مهم این است که آنها، چگونه بار محاسباتی مربوط را در میان سرورها پخش کرده و چگونه بهروزرسانیهاي دادهاي را در میان این مجموعه عظیم مدیریت ميکنند؟ سؤال بعدی، چگونگی میزبانی آنها است.
ایده ارائه این راهحلها به عنوان سرویس در کلاود و انجام تمام امور نگهداری توسط دیگران، برای توسعهدهندگان حرفهاي، ایدهاي بسیار وسوسهکننده و جذاب است. با این حال، هزینه گذار به چنین پایگاههاي داده جدیدی بسیار بالا است. علاوه بر اینکه زبان پرس و جوی واحد و استانداردی برای استفاده در آنها وجود ندارد، از وجود لایههاي وسیع آرایههاي انتزاعی JDBC نیز در آنها خبری نیست. توجه داشته باشید که استفاده نادرست از این نوع پایگاههاي داده ممکن است شما را در پروژهتان قفل کند. این هزینهاي است که باید برای ویژگیها و سرگرمیهاي جدید پرداخت.