
۰
میانگین امتیاز
به این متن امتیاز دهید!
سيستمفايلي توزيع شده هدوپ ( Hadoop DFS)
اين سيستمفايلي به زبان برنامهنويسي جاوا نوشتهشده و به صورت يک پروژه منبع باز توسط بنياد آپاچي معرفي شدهاست. سيستمفايلي هدوپ توسط شرکتهاي وبي و ساير شرکتهايي که با مشکل و محدوديتهاي ناشي از حجم زياد داده مواجه بودند، به کار گرفته شدهاست. گستردگي اين استفاده در حدي است که آن را چاقوي همهکاره سوئيسي قرن ۲۱ مينامند. همه اين حرفها به آن معنا است که دير يا زود شما نيز با اين سيستمفايلي تعامل خواهيد داشت. به ويژه تصميم مايکروسافت در مورد تعيين اين سيستمفايلي به عنوان يک گزينه اختياري در محيط سيستمعامل سرور ويندوز، به معني افزايش احتمال استفاده عمومي از اين سيستمفايلي است (به مقاله «مایکروسافت هورتون» در صفحه ۱۹۶ همین ویژهنامه مراجعه کنید.)
اين سيستمفايلي توسط توسعهدهندهاي به نام دوگکاتينگ (Doug Cutting) طراحی شده و از روي فيل اسباببازي پسرش نامگذاري شدهاست. این سیستمفایلی از GFS و MapReduce (روش دسترسي به داده گوگل در محيطهاي محاسباتي) الهام گرفتهاست. در سال ۲۰۰۴ کاتينگ و سايرين در حال کار روي پروژه موتور جستوجوي شرکت آپاچي با نام Nutch بودند. در اين پروژه يک نيازمندي مطرح بود که براساس آن بايد روشي براي مقياسپذيري موتور خزنده و انديسکننده اطلاعات وب ارائه ميشد که بتواند در مقياس محيط وب گسترش پيدا کند. کاتينگ به مطالعه مستندات شرکت گوگل در مورد GFS و MapReduce پرداخت و کار روي مدل مورد نظر خود و پيادهسازي آن را آغاز کرد. اگر چه بيشتر هيجانها و اشتياقهای مربوط به هدوپ از قابليتهاي پردازش داده توزيعشده اين سيستم فايلی ناشي ميشود که خود نتيجه الهام از مديريت توزيع شده پردازش و مدل MapReduce است، اما آنچه اين مجموعههاي عظيم داده را براي پردازشهاي توزيع شده مديريت ميکند سيستمفايلی توزيع شده هدوپ (HDFS) است. سيستمفايلي هدوپ تحت مجوز آپاچي توسعه داده ميشود و توزيعهاي مختلف رايگان و غيررايگان اين محيط قابل تهيه است. توزيعي که من با آن کار کردم توسط شرکتي به نام Cloudera ارائه شده که اکنون کاتينگ را به استخدام خود درآورده است. اين توزيع که شامل Apache هدوپ نيز ميشود، نسخه اپنسورس پلتفرم سازماني Cloudera است. همچنين خدمات Cloudera و Configuration Express Edition را نيز به همراه دارد که براي حداکثرپنجاه نود رايگان است. مايکروسافت براي عملياتيسازي هدوپ در محيط Windows Server و Azure با شرکتي به نام HortonWorks همکاري ميکند. (اين شرکت محل استقرار تعداد زيادي از کارمندان سابق شرکت ياهو است که در گذشته روي پروژه هدوپ فعاليت ميکردند.) شرکت مذکور يک نگارش مبتني بر هدوپ ارائه کردهاست که HortonWorks Data Platform نام دارد و به صورت محدود به عنوان «پيشنمايش فناوري» عرضه شده است. همچنين اين محصول شامل يک بسته مبتني بر دبیان است که جزئي از Apache Core به شمار ميرود و در کنار آن مجموعهاي از محصولات کدباز و تجاري نيز ارائه شده که به نحوي براساس پلتفرم هدوپ عرضه ميشوند. ميتوان از HDFS براي کاربردهاي متنوعي استفاده کرد. نيازمندي اين روش حجم زيادي از سختافزارهاي ارزانقيمت و توانايي آن پردازش حجم عظيمي از داده است. اما اين روش به واسطه معماري خود روش مناسبي براي ذخيرهسازي دادههاي عمومي به شمار نميرود. در اين سيستم تا حدودي از انعطافپذيري ساختار، کاسته خواهد شد. HDFS ناچار است تا از بعضي ويژگيها که در ساير سيستمهایفايلي وجود دارد، فاصله بگيرد زيرا اين سيستم فايلی بايد تضمين کند که ميتواند حجم زياد دادهاي را که روي صدهايا هزاران ماشين فيزيکي قرار گرفتهاند، به خوبي مديريت کرده و از آنها استفاده کند. نمونهاي از نيازهاي مطرح در اين روش، امکان دسترسي تعاملي به داده است که بايد توسط اين سيستمفايلي برآورده شود. در حاليکه هدوپ مبتني بر زبان جاوا است، اما روشهايي ارائه شده تا بتوان به موازات APIهاي جاوا، از طريق کانالهاي ديگر نيز با HDFS تعامل داشت. يک نگارش مبتنی بر C از اين API ها ارائه شدهاست. همچنين از طريق يک پوسته خط فرمان نيز ميتوان با هدوپ تعامل داشت و در نهايت آنکه ميتوان دادهها را با استفاده از درخواستهاي HTTP در اختيار گرفته و مشاهده کرد. همچنين يک نگارش از HDFS Mountable نيز وجود دارد که بر مبناي FUSE توسعه داده شده است، در نتيجه به HDFS امکان ميدهد تا به صورت يک سيستمفايلي توسط بيشتر سيستمعاملها استفاده شود. توسعهدهندگان اين محيط در حال بررسي رابط WebDAV هستند تا بتوانند امکان نوشتن داده در اين سيستم را از طريق محيط وب، فراهم کنند.
معماری سيستمفايلیHDFS بسيار به GFS نزديک است و از ساختار سهلايهاي و تکمرجع آن پيروي ميکند. هر کلاستر يا خوشه از هدوپ، يک سرور مرجع دارد که NameNode ناميده ميشود. اين سرور مسئول رديابي متاديتا است و آدرس و وضعيت کپيهاي مربوط به هر يک از بلاکهاي ۶۴ مگابايتي داده را نگهداري ميکند. دادهها از طريق همين NameNode در محيط کلاستر کپي ميشوند و سيستمهاي Data Node مسئوليت نوشتن و خواندن داده را بر عهده دارند. به طور پيشفرض هر بلاک داده، سه بار کپي ميشود اما ميتوان از طريق تغيير تنظيمات کلاسترها، تعداد کپيها را نيز تغيير داد. در HDFS نيز همانند GFS، سرور مرجع به سرعت از فرآيندهاي نوشتن و خواندن کنار گذاشته ميشود. اين کار مانع از ايجاد گلوگاه در عملکرد سيستم ميشود. زماني که درخواستي براي دسترسي به داده مطرح ميشود، پردازه NameNode اطلاعات مکاني مربوط به DataNode را بازميگرداند. در اين فرآيند آدرس مربوط به يکي از کپيها برگردانده ميشود که کمترين فاصله را تا محل درخواست داده داشته باشد. همچنين NameNode، مسئول بررسي و رديابي سلامت هر يک از DataNodeها است. اين فرآيند از طريق پروتکلي به نام heartbeat انجام ميشود که مانع ارسال درخواست به DataNodeهايي که پاسخ نميدهند ميشود و آنها را با تگ «dead» علامتگذاري ميکند. بعد از اعلام آدرس، سرويس مرجع NameNode براي تکميل فرآيند هيچ مسئوليت ديگري بر عهده ندارد. هرگونه تغيير در DataNodeها بعد از کاملشدن، به NameNode گزارش داده ميشود و در قالب يک فايل ثبت جزئيات عمليات يا log ذخيره ميشود. اين فايل در مرحله کپيبرداري از داده و به منظور اعمال تغييرات در سطح DataNodeها مورد استفاده قرار ميگيرد. اين فرآيند نيز همانند فرآيند معادل در محيط GFS، به کندي انجام ميشود. در اين فرآيند نيز به موازات هدايت درخواستها به سمت بهروزترين دادهها، پردازشهاي پسزمينهاي که در حال فعاليت هستند غالباً از همان دادههاي کهنه و قديمي استفاده ميکنند تا فرآيند به روزآوري به اتمام برسد. از آنجا که دادهها و سرويسهاي محيط HDFS طوري طراحي شدهاند که دادهها فقط يکبار نوشته شود، در نتيجه شرايط فوق به ندرت رخ ميدهد. تغييرات دادهها در اين روش معمولاً در قالب افزوده شدن داده به دادههاي قبلي است، نه بازنويسي روي دادههاي جديد و در نتيجه حفظ ثبات داده، آسانتر خواهد بود. از طرف ديگر به دليل ماهيت برنامههايي که از هدوپ استفاده ميکنند، دادهها معمولاً به صورت گروهي و در قالب قطعات بزرگ براي سيستمفايلي، ارسال میشوند. زماني که يک کلاينت، دادهاي را براي نوشتهشدن در محيط HDFS ارسال ميکند، اين داده در نخستين مرحله توسط برنامه کلاينت، در يک فايل موقت محلي ذخيره ميشود تا اندازه آن به ۶۴ مگابايت که اندازه پيشفرض بلاکها است، برسد. سپس کلاينت درخواستي را براي NameNode ارسال ميکند و نام يک DataNode را دريافت ميکند.
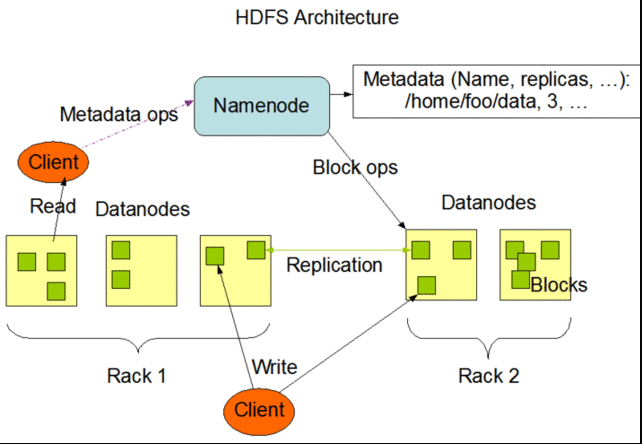
شکل ۲ -شمایی از معماری سیستمفایلی هدوپ
در مرحله بعدي، آدرس مذکور را قفل کرده و داده را در آن ذخيره ميکند. اين فرآيند به طور متوالي و جداجدا، به ازاي هر بلاک از داده نهايي، انجام ميشود. با اين روش حجم ترافيک شبکه نيز کاهش مييابد و البته سرعت نوشتن داده نيز کندتر ميشود. اما بايد در نظر داشت که HDFS بيشتر براي انجام فرآيندهاي خواندن داده طراحي شده نه فرآيندهاي نوشتن و ذخيره داده. يکي ديگر از ويژگيهاي HDFS که منجر به کاهش ترافيک نوشتن داده در سطح شبکه ميشود، به نحوه تهيه کپي از داده در اين سيستمفايلي، باز ميگردد. با فعالکردن يکي از قابليتهاي HDFS به نام “rack awareness” امکان مديريت توزيعهاي مختلفي از داده فراهم ميشود. به اين ترتيب، مدير سيستم ميتواند به ازاي هر نود، يک rack ID تعيين کند. با اين کار و از طريق يک متغير در فايل متني تنظيمات، ميتوان محل فيزيکي هر يک از دادهها را تعيين کرد. به طور پيشفرض، همه نودها در يک rack قرار دارند، اما وقتي پارامتر rack awareness، فعال شود، سيستمفايلي HDFS، يک کپي از داده را در نود ديگري (در محل فيزيکي ديگر) قرار ميدهد که در همان مرکز داده متناظر با آن rack قرار دارد و کپي ديگر را در rack ديگري قرار ميدهد. اين کار ميزان ترافيک ناشي از نوشتن داده را در سطح شبکه، کاهش ميدهد و بر اين منطق استوار است که احتمال بروز خطا در کل محيط rack در مقايسه با هر تکنود، بسيار ناچيز است.
اين روش به صورت تئوري عملکرد نوشتن داده در سيستمفايلي HDFS را بهبود ميدهد بدون آنکه قابل اطمينان بودن آنرا بامشکل روبهرو کند. سرور NameNode در سيستمفايلي HDFS همانند نگارشهاي اوليه GFS، به صورت بالقوه به عنوان عامل شکست کل سيستمي به شمار ميآيد که قرار بود يک سيستم به شدت دردسترس و توزيعشده باشد. اگر متاديتاي ذخيره شده در NameNode از دست برود، کل سيستمفايلي HDFS مطلقا غيرقابل دسترس خواهد بود. درست مانند ديسک سختي که جدول اختصاص دهي فضا به فايلهاي آن خراب شده باشد. HDFS داراي قابليت معرفي نود پشتيبان است. اين قابليت، يک کپي همزمان شده از متاديتاي NameNode را در حافظه نگهداري ميکند و کپيهايي از وضعيتهاي قبلي سيستم را نيز تهيه ميکند تا بتوان در صورت لزوم فرآيند بازگشت به عقب را نيز از طريق آن انجام داد. همچنين، ميتوان کپيهاي مذکور از وضعيت قبلي را روي سيستمهايي جداگانه نگهداري کرد که در اين فرآيند check point node ناميده ميشوند. البته طبق مستندات HDFS، اين سيستمفايلي فعلاً از فرآيند بازيابي خودکار داده NameNode پشتيباني نميکند و نود پشتيبان نميتواند به صورت خودکار جايگزين نود اصلي شده و خدمات نود مرجع را ارائه دهد. هر دو سيستمفايلي HDFS و GFS با توجه به نيازهاي برنامههايي نظير موتورهاي جستوجو طراحي شدهاند. اما در سرويسهاي محيط ابري که براي فرآيندهاي محاسباتي عموميتر طراحي شدهاند، ناديده گرفتن بعضي نکتهها نظير رويکرد نوشتن فقط يک بار و تغييرات محدود در آن که براي تضمين عملکرد بهينه در پرسوجو از داده کاربرد دارد، نميتواند رويکرد مناسبي باشد. به همين سبب شرکت آمازون سيستمفايلي توزيعشده مختص به خود را توسعه داده و معرفي کرد که با نام داينامو شناخته ميشود.