
هدوپ چیست؟
درصورتی که مقالههاي مربوط به سیستم نرمافزاری کندور را در شمارههای ۸۸ و ۸۹ ماهنامه خواندهاید، بهتر است بدانید که هدوپ از لحاظ مفهوم کاری به میزان بسیار زیادی به این پلتفرم شبیه است. با این حال، تفاوتهاي بنیادینی میان این دو پلتفرم محاسباتی وجود دارد که با خواندن ادامه این مقاله، به آنها پی خواهید برد.
در بازهاي تقریباً دو ساله، هدوپ، یک نرمافزار اپن سورس رایگان، که از روی یک اسباب بازی نامگذاریشده بود، بسیاری از سایتهاي بزرگ و معروف دنیا را تسخیرکرد. این نرمافزار هماکنون موتورهای جستوجوی بزرگ را کنترل ميکند و درباره نمایش تبلیغات در کنار نتایج جستوجو تصمیم ميگیرد، مطالبی را که در صفحه نخست یاهو نمایش داده ميشوند،تعیین ميکند یا در یافتن دوستی بسیار قدیمی در یک شبکه اجتماعی نقشی اساسی ایفا ميكند. هدوپ چنین قدرتی را از طریق ارزان سازی و سادهسازی تحلیل حجم غیرقابل تصوردادههایی که در سطح اینترنت پراکندهاند، به دست آوردهاست. با فراهمشدن امکان نگاشت اطلاعات روی هزاران كامپيوتر ارزان و خلق روشهاي آسانتر برای نوشتن پرس و جوهای تحلیلی، مهندسان از شر چالشهاي بزرگ برای واکاوی دادهها خلاص شدهاند و به سادگی، سؤالشان را ميپرسند.
این پروژه که هم اکنون یکی از پروژههاي سطح بالای آپاچی است، بر اساس مفهوم Map Reduce و GFS معرفی شده از طرف گوگل توسعه دادهشده است. هدوپ برای نخستينبار توسط فردی با نام دوگ کاتینگ(Doug Cutting) برای پشتیبانی از توزیعشدگی در پروژه موتور جست وجوی Nutch ایجاد شد. کاتینگ نام پروژه را از روی فیل عروسکی پسرش انتخاب کرد (شكل۱).

شکل ۱- سازنده هدوپ و فیل عروسکی معروف پسرش
هم اکنون، تعداد بسیار زیادی از توسعه دهندگان در رشد و توسعه آن نقش دارند و در حوزه ذخیرهسازی و مدیریت دادههاي عظیم توجه زيادي به آن شده است. هماکنون، بزرگترین شرکت سهیم در توسعه هدوپ یاهو است که به طور گستردهاي از امکانات آن در تجارت خود استفاده ميكند.
معماری
بسیاری از ابزارهای مدیریتداده در سطح سازمانهاي بزرگ، از جمله پایگاههاي داده رابطهاي سنتی، طوری طراحی شدهاند که پرس و جوهای ساده را با سرعت اجرا كنند. آنها با استفاده از تکنیکهاي پیشرفتهاي مانند نشانهگذاری دادهها، به ارزیابی قسمت کوچکی از دادههاي موجود پرداخته و عملیات پرسوجو را به اتمام ميرسانند. در نقطه مقابل، هدوپ ابزار متفاوتی است که عملیات فوق را به روش دیگری انجام میدهد. هدوپ، مسائلی را هدف گرفته که یافتن پاسخ آنها، به تحلیل كل دادههاي موجود در سیستم نياز دارد. بهعنوان مثال، در تحلیل متن یا پردازش تصاویر نیاز است تا هر رکورد اطلاعاتی خوانده شده و براساس محتوای دیگر رکوردهای مشابه تفسیر شود. هدوپ عملیات روی دادههاي بسیار بزرگ و حجیم را با مقیاسدهی افقی (Scale Out) پردازشها روی تعداد بسیار زیادی از سرورها و با استفاده از روش MapReduce (توزیع و تجمیع) به انجام ميرساند. توجه به این مفهوم در چند سال اخیر به آن دلیل است که مقیاس پذیری عمودی (Scale Up) یا استفاده از یک سرور منفرد اما بسیار قوی، بسیار پر هزینه و محدود کننده است. در اصل، در حال حاضر و آینده قابل پیش بینی ما، هیچ سرور منفرد مناسبی برای پردازش حجمهاي بسیار زیادي از دادهها در زمان قابل قبول وجود ندارد و به همین دلیل، تمام توجهها به سمت شکستن سربار عملیات پردازش روی ماشینهاي کوچکتر، ارزانتر و با قابلیت نگهداری بالاتر جلب شده است. با استفاده از این مفهوم، ميتوان با افزایش یا کاهش تعداد سرورهای فعال در یک مجموعه توانپردازشی را به میزان دلخواه کم یا زیادكرد و همچنين، از امکان جایگزینی ماشینهاي معیوب با ماشینهاي سالم نیز بهره برد. استفاده از این قابلیت، اما به قابلیت مقياسدهی افقی پردازشهاي موردنظر و امکان اجرای موازی آنها نیزبستگی دارد. با استفاده از روش توزیع و تجمیع، هدوپ یک پردازش را شکسته و پردازشهاي کوچکتر را به سرورهای مختلف ارسال ميکند تا هر کدام پردازش مربوط به خود را به اتمام برسانند. سپس، هدوپ نتایج هر کدام را دریافت کرده و در فایلهایی مينویسد که ممکن است بهعنوان ورودی به پلههاي جدیدی از توزیع و تجمیع ارسال شوند. تکنیک توزیع و تجمیع در آغاز توسط دو تن از مهندسان گوگل و برای ایندکس کردن در کاربردهای مربوط به جستوجوی وب معرفی شد و بعدها توسط بسیاری از پروژهها مورد استفاده قرارگرفت. در بحث جستوجو، تابع Map پارامترهای جستوجو پذیر هر صفحه وب را پیدا کرده و تابع Reduce این داده ها را بهعنوان ورودی دریافت کرده و تعداد بارهایی را که پارامترهای مذکور در این صفحه استفاده شدهاند، به دست ميآورد.
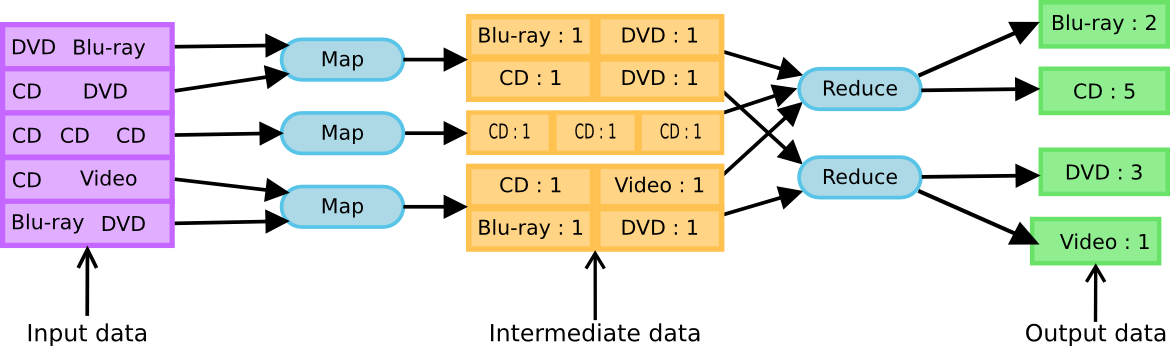
شکل ۲- عملیات توزیع و تجمیع در هدوپ
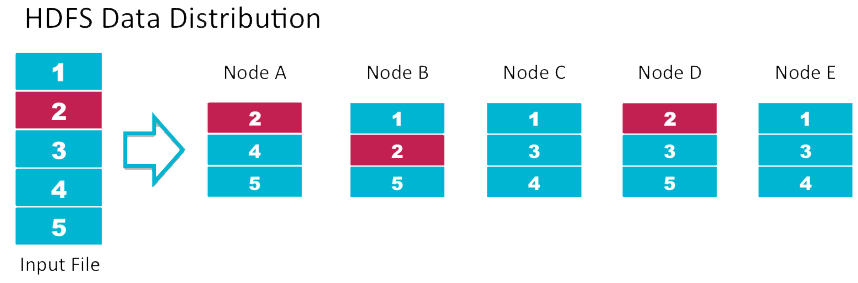
شکل ۳- نحوه ذخیره سازی فایلهاي روی HDFS – توزیع بلاکهای هر فایل روی چندین نود در شبکه
توجه به این نکته ضروری است که قدرت عملیاتی هدوپ تنها در محیطهایی به ثمر مينشیند که با استفاده از تعداد بسیار زیادی از سرورها در یک سرور فارم، به جمع آوری و نگهداری از دادهها پرداختهميشود. هدوپ ميتواند پرسوجوهای دادهاي را بهصورت وظایف بزرگ پس زمینه در مجموعه سرورها اجرا کند. این قابلیت، اجازه میدهد تا کاربر قادر باشد بهجای خرید سختافزارهای گران قیمت، از مجموعهاي از سختافزارهای ارزان استفاده کند. همچنين، این روشها باعث ميشوند تا حجم عظیم دادهها که بارگذاری آنها برای پردازش الزامی است، قابل پردازش باشند زيرا با توجه به حجم آنها و محدودیتهاي امروزی، انجام چنین کارهایی با سختافزارهای منفرد غیر ممکن خواهد بود. توجه داشته باشید که قابلیت تبدیل پردازشها به پردازشهاي کوچکتر در موفقیت این روش نقشی اساسی دارد و شکست پردازشها یکی از بزرگترین چالشهاي موجود بر سر راه عملیات به شمار ميرود.
۰
میانگین امتیاز
شما هم امتیاز بدهید!